


1. 中国語のピンインへの変換の現状
まず第一に、連絡先をピンイン文字でソート/フィルタリングするなど、中国語のピンインへの変換に対する強い需要があると言われるべきです。目的地(通常はチケット購入など)
ピンインの頭文字による分類など お待ちください。しかし、この要件の解決策は、(特にブラウザ側で)賢い実装については聞いたことがありませんが、おそらく巨大な辞書が必要です。
特に JavaScript については、github と npm を確認してください。中国語の文字をピンインに変換するための優れたライブラリには、pinyin
と pinyinjs が含まれています。どちらにも膨大な辞書が付属していることがわかります。
これらの辞書は数十、数百 KB (場合によっては数 MB) になることが多く、ブラウザ側で使用するにはまだ勇気が必要です。したがって、中国語の文字をピンインに変換する必要がある場合、最初の反応はリクエストを拒否する (またはサーバー側で実装する) ことになるのは驚くべきことではありません。
さて、ブラウザ側の 300 行のコードで中国語の文字をピンインに変換できると言ったら、信じられませんか?
2. Android 4.2.2 連絡先コードから始めます
このブログでもう一度強調します - Android ソース コードを使用して、漢字からピンインへの変換機能を簡単に実現します。
今日は、Android システムのソース コードから抽出した中国語の文字をピンインに変換するソリューションを紹介します。たった 1 つのクラスと 560 行を超えるコードで、他の 3 番目のコードを使用せずに、中国語の文字をピンインに変換する機能を簡単に実装できます。 -パーティの依存関係。
それはあなたの考えを壊しましたか: 辞書を放棄できる強力なアルゴリズムはありますか?
初めてブログを読んだ後、Android コードから発見された数百行のコードが紹介されているだけで、少しがっかりしました。 JavaScript に移植しようと思ってコードを 2 回目に読んだときに、ようやく原理が理解できたので、移植の旅を始めました。
3. 中国語の文字をピンインに変換するための 300 行の JavaScript コードをステップごとに説明します
まず、核心に直接触れましょう: なぜ中国語の文字をピンインに変換するという考え方があるのですか巨大な辞書が必要ですか?
漢字の配列はピンインとは関係がないため、たとえば、u4E00-u9FFFの漢字区間では、前者がハ、後者がゼである可能性があり、漢字のUnicodeを関連付けることはできません。この辞書には、各漢字 (または常用漢字) のピンインが記録されています。
ただし、「A」、「AI」、「AN」、「ANG」、「AO」、「BA」、...、「ZUI」、「ZUN」など、すべての漢字をピンインで並べ替えることができるとします。 、「ZUO」でソートすると、同じピンインを持つ各漢字 queue の最初の漢字を覚えるだけで済みます。そうすれば、必要な辞書は非常に少なくなります(すべてのピンインをカバーするだけで、ピンイン自体の数は多くありません)。
さて、難しいのは中国語の文字をピンインで並べ替えることです。幸いなことに、ICU/ローカリゼーション関連の API は、この並べ替え API を提供しています (便利な並べ替え/比較メソッドがなかった場合、この記事は表示されない可能性があります)。
これが、中国語の文字をピンインに変換するために 300 行を使用できる理由です: Intl.CollatorAPI: Intl.Collator は、ローカリゼーション関連の 文字列ソートを内部的に実装します。基本的に、Intl.Collator.prototype.compare を使用して、すべての中国語の文字をピンインに従って並べ替えることができます。
境界漢字テーブル: ソートされた境界点を記録します。この漢字テーブルの各漢字は、並べ替え後の同じピンインを持つ一連の漢字の最初の漢字です (各中国語は、collator が zh_CN の場合、同じピンイン内の最初の漢字になります)。
そう言えば、まだ不明な点があるかもしれないので、コードの一部に直接進みましょう:

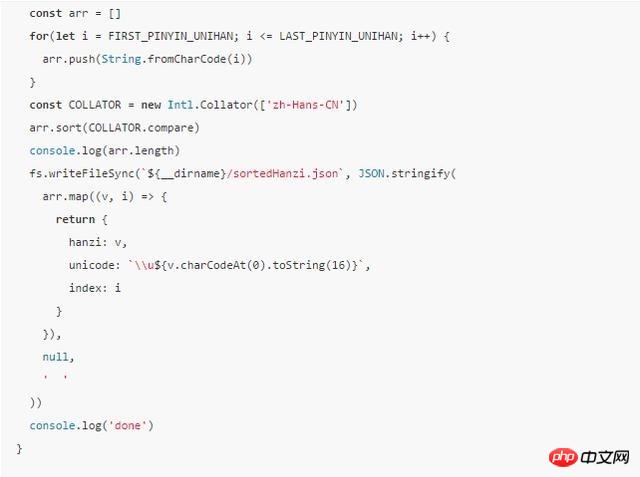
興味のある学生は、上記のnode--icu-data-dir=node_modules/full-icuを実行して確認してください。 script.js を開き、基本的にピンインでソートされた漢字テーブルが得られるかどうかを確認します。
注意すべき点がいくつかあります:
取得した中国語の文字のリストがピンインに従って完全にソートされていないため、再度「基本」を太字にしました。一部の中国語の文字の途中に他のピンインが挿入されている場合があります。これは、境界テーブルを作成するときに特に注意する必要があります。
上記のスクリプトで取得したテーブルは、すべての漢字のソートです。一部のテーブルは、Android コードの HanziToPinyin.java のテーブルと異なるため、HanziToPinyin.java のテーブルを更新する必要があります。 (Java から JavaScript に切り替える際の最大の落とし穴と作業負荷: 境界テーブルの修正)
誰もがコア コード: constCOLLATOR=newIntl.Collator(['zh-Hans-CN']), Intl.Collator
(ここで指定されたロケールは中国です zh-Hans-CN)は、中国語の文字をピンインでソートするためのキーです。これは、文字列をロケール固有の順序でソートする国際化 API です。
スクリプトを実行するときは、最初に npmifull-icu を実行してください。この依存関係により、不足している中国語サポートが自動的にインストールされ、スクリプトを実行するための ICU データ ファイルを指定する方法が求められます。
1.ICUICU は InternationalComponentsforUnicode の略で、アプリケーションに Unicode と国際化サポートを提供します。
ICU は、ソフトウェア アプリケーションに Unicode とグローバリゼーションのサポートを提供する、広く使用されている C/C++ ライブラリと Java ライブラリのセットです。ICU は広く移植可能であり、C/C++ と Java ソフトウェア間のすべてのプラットフォームで同じ結果をアプリケーションに提供します。
ICU は、ローカライズされた文字列比較サービス (UnicodeCollation Algorithm + ローカル固有の比較ルール) を提供します。
Collation:Compare ICU の照合は、Unicode 照合アルゴリズムと、このタイプのデータの包括的なソースである Common Locale Data Repository からのロケール固有の比較ルールに基づいています。
最新のブラウザでは、一般に ICU にユーザーのローカル言語のサポートが組み込まれており、それを直接使用できます。
しかし、node.js の場合、通常、ICU にはサブセット (通常は英語) しか含まれていないため、独自に中国語のサポートを追加する必要があります。一般に、不足している中国語サポートは、npminstallfull-icu 経由で full-icu
をインストールすることでインストールできます。 (上記のnode--icu-data-dir=node_modules/full-icuを参照してください)。
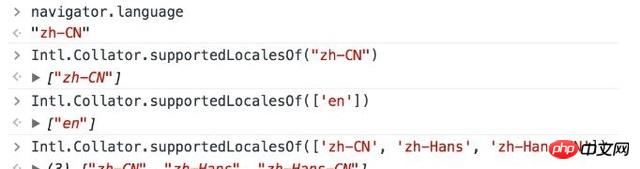
2.IntlAPI 前のセクションでは基本的に国際化/ローカライゼーションに関する知識を説明しました。ここで組み込み API の使用方法を追加します。ユーザー言語とランタイムがこの言語をサポートしているかどうかを確認するにはどうすればよいですか? Intl.Collator.supportedLocalesOf(array|string)
サポートされているロケールを含む array を返します (デフォルトのロケールに戻ることなく) パラメーターには、テストするロケールである配列または文字列を指定できます (つまり、BCP47 言語タグ)。
Collator オブジェクト を構築し、文字列
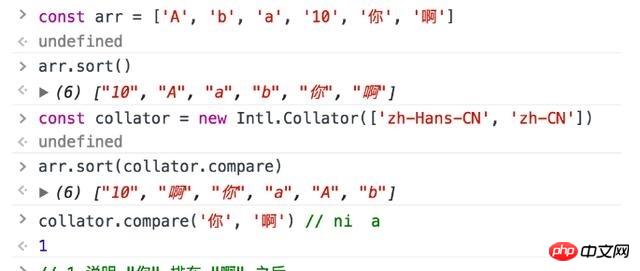
Intl.Collator.prototype.compare を使用すると、言語で指定された順序で文字列を並べ替えることができます。中国語では、この並べ替えはほとんどの場合ピンイン順、「A」、「AI」、「AN」、「ANG」、「AO」、「BA」、「BAI」、「BAN」、「BANG」、」になります。バオ」、「ベイ」、「ベン」、「ベン」、「ビ」、「ビアン」、「ビアオ」、「ビー」、「ビン」、「ビン」、「ボ」、「ブ」、「CA」 、'CAI'、'CAN'、...
、これが上で説明した中国語の文字をピンインに変換するための鍵です。
4. 境界テーブルの修正
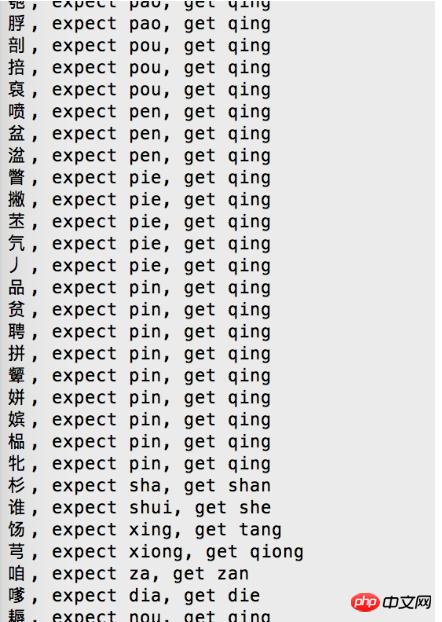
明らかに、この境界テーブルには問題があるため、修正する必要があります。
ほとんどの漢字が清に変換されていることがわかります。清のピンインに対応する漢字に問題があることがわかります。
この漢字が見つかりました。「u72c5」/「狅」とその前後に 1 文字加えたものです、['u4eb2','u72c5','u828e']/["奇","狅","苎"]
。
検索、'u72c5'/'狅'はqingと読めるのですが、現在はkuangと読まれており、これがエラーの原因となります。
すべての漢字の初期ソートリストによると、清の最初の漢字は「u9751」/「靑」です。
変更後、失敗した変換は 104 件のみになりました。

【関連する推奨事項】
3. JavaScript による検索ツールバーの実装の詳細な例
4. 。JavaScript での async と await の使用法の詳細な紹介
5. JavaScript の最も実践的な 12 のヒントを共有します
以上がJavaScriptを使って漢字をピンインに変換する例を詳しく解説の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。





























![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



