

この記事では、MySQL クエリ テーブルのデータを複製する方法を主に紹介しますので、必要な方は参考にしてください
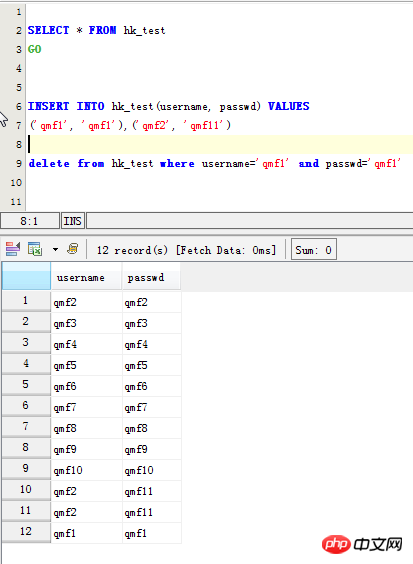 まず、重複したオリジナルを確認します。データ:
まず、重複したオリジナルを確認します。データ:
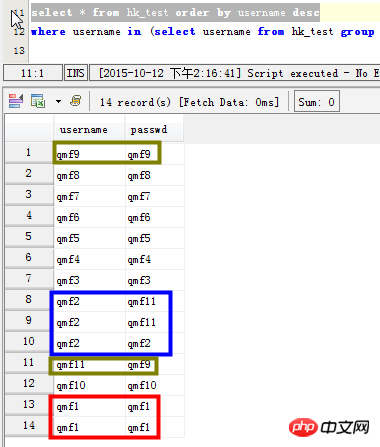
INSERT INTO hk_test(username, passwd) VALUES ('qmf1', 'qmf1'),('qmf2', 'qmf11') delete from hk_test where username='qmf1' and passwd='qmf1'
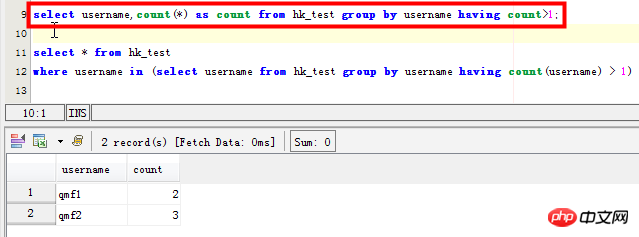 シナリオ 2: を一覧表示しますusername フィールド 重複レコードは具体的には以下を参照します:
シナリオ 2: を一覧表示しますusername フィールド 重複レコードは具体的には以下を参照します:
select username,count(*) as count from hk_test group by username having count>1; SELECT username,count(username) as count FROM hk_test GROUP BY username HAVING count(username) >1 ORDER BY count DESC;
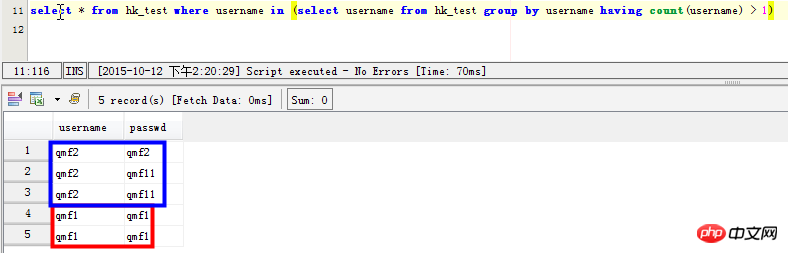
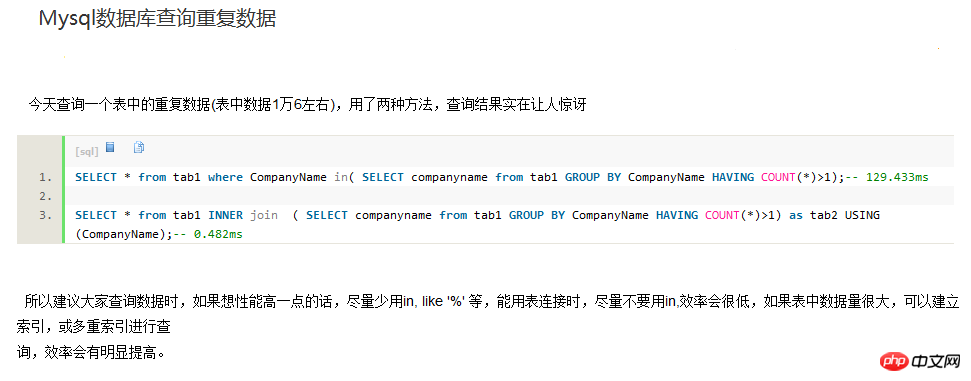
select * from hk_test where username in (select username from hk_test group by username having count(username) > 1) SELECT username,passwd FROM hk_test WHERE username in ( SELECT username FROM hk_test GROUP BY username HAVING count(username)>1) 但是这条语句在mysql中效率太差,感觉mysql并没有为子查询生成临时表。在数据量大的时候,耗时很长时间
于是使用先建立临时表 create table `tmptable` as ( SELECT `name` FROM `table` GROUP BY `name` HAVING count(`name`) >1 ); 然后使用多表连接查询 SELECT a.`id`, a.`name` FROM `table` a, `tmptable` t WHERE a.`name` = t.`name`; 结果这次结果很快就出来了。 用 distinct去重复 SELECT distinct a.`id`, a.`name` FROM `table` a, `tmptable` t WHERE a.`name` = t.`name`;
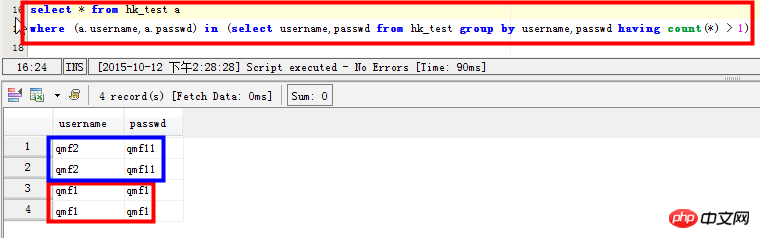
select * from hk_test a where (a.username,a.passwd) in (select username,passwd from hk_test group by username,passwd having count(*) > 1)
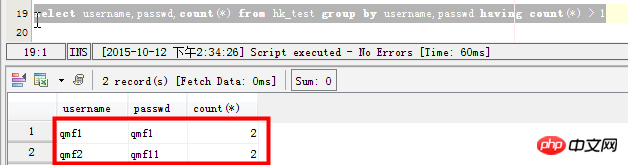
select username,passwd,count(*) from hk_test group by username,passwd having count(*) > 1
MySQL查询表内重复记录 查询及删除重复记录的方法 (一) 1、查找表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断 select * from people where peopleId in (select peopleId from people group by peopleId having count(peopleId)>1) 2、删除表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断,只留有一个记录 delete from people where peopleId in (select peopleId from people group by peopleId having count(peopleId)>1) and min(id) not in (select id from people group by peopleId having count(peopleId)>1) 3、查找表中多余的重复记录(多个字段) select * from vitae a where (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*)>1) 4、删除表中多余的重复记录(多个字段),只留有rowid最小的记录 delete from vitae a where (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1) and rowid not in (select min(rowid) from vitae group by peopleId,seq having count(*)>1) 5、查找表中多余的重复记录(多个字段),不包含rowid最小的记录 select * from vitae a where (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1) and rowid not in (select min(rowid) from vitae group by peopleId,seq having count(*)>1) (二) 比方说 在A表中存在一个字段“name”,而且不同记录之间的“name”值有可能会相同,现在就是需要查询出在该表中的各记录之间,“name”值存在重复的项; Select Name,Count(*) From A Group By Name Having Count(*) > 1 如果还查性别也相同大则如下: Select Name,sex,Count(*) From A Group By Name,sex Having Count(*) > 1 (三) 方法一 declare @max integer,@id integer declare cur_rows cursor local for select 主字段,count(*) from 表名 group by 主字段 having count(*) >; 1 open cur_rows fetch cur_rows into @id,@max while @@fetch_status=0 begin select @max = @max -1 set rowcount @max delete from 表名 where 主字段 = @id fetch cur_rows into @id,@max end close cur_rows set rowcount 0
重複レコードの検索mysqlデータテーブル内
次の SQL ステートメントは、テーブル内のすべての重複レコードを検索できます。select user_name, count(*) as count from user_table group by user_name getting count>1;
user_name は、重複を検索するものです。
count は、検索するテーブルの名前です。
having は、フィルターに使用されます。独自のデータ テーブルでパラメータを使用する まず、Phmyadmin または Navicat で対応するフィールド パラメータを実行して、重複しているデータを確認してから、データベースから削除することができます。また、バックグラウンドでニュースを読むページに SQL ステートメントを直接挿入することもできます。リストを完了して重複データを照会します。重複がある場合は、それらを直接削除できます。
効果は次のとおりです:
欠点: この方法の欠点は、データベース内のデータ量が多い場合、Navicat を使用してテストしたことです。もちろん、Web サイト上でデータを繰り返しクエリする SQL ステートメントは他にもあります。調査を行って、Web サイトに適したクエリ ステートメントを見つけてください。 。以上がmysqlクエリテーブルの重複データメソッドの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



