


インターネット上の Python チュートリアルのほとんどはバージョン 2.X です。python3.X と比較すると、多くのライブラリの使用方法が大きく異なります。私は Python3 をインストールしました
。春節(なんて暇なんだ)、冗談を兼ねて簡単なプログラムを書き、プログラムを書く過程を記録してみました。私が初めてクローラーに出会ったのは、このような投稿を見たときでした。オムレットで女の子の写真をクロールするという面白い投稿でした。そこで私も猫や虎の真似をして
写真を撮り始めました。 テクノロジーは未来にインスピレーションを与えます。プログラマーとして、どうしてそのようなことができるでしょうか?

0x02
腕まくりをして始める前に、まず理論的な知識を広めていきましょう。
簡単に言えば、Web ページ上の特定の場所にコンテンツをプルダウンする必要があります。どのようにプルダウンするか? まず、Web ページを分析して、必要なコンテンツを確認する必要があります。例えば、今回クロールしたのは、爆笑サイトのジョークです。 爆笑サイトのジョークページを開くと、たくさんのジョークが表示されます。読んでから落ち着いてください。こんなふうに笑っていたらコードは書けません。
ome では、inspect 要素を開いて HTML タグをレベルごとに展開するか、小さなマウスをクリックして必要な要素を見つけます。
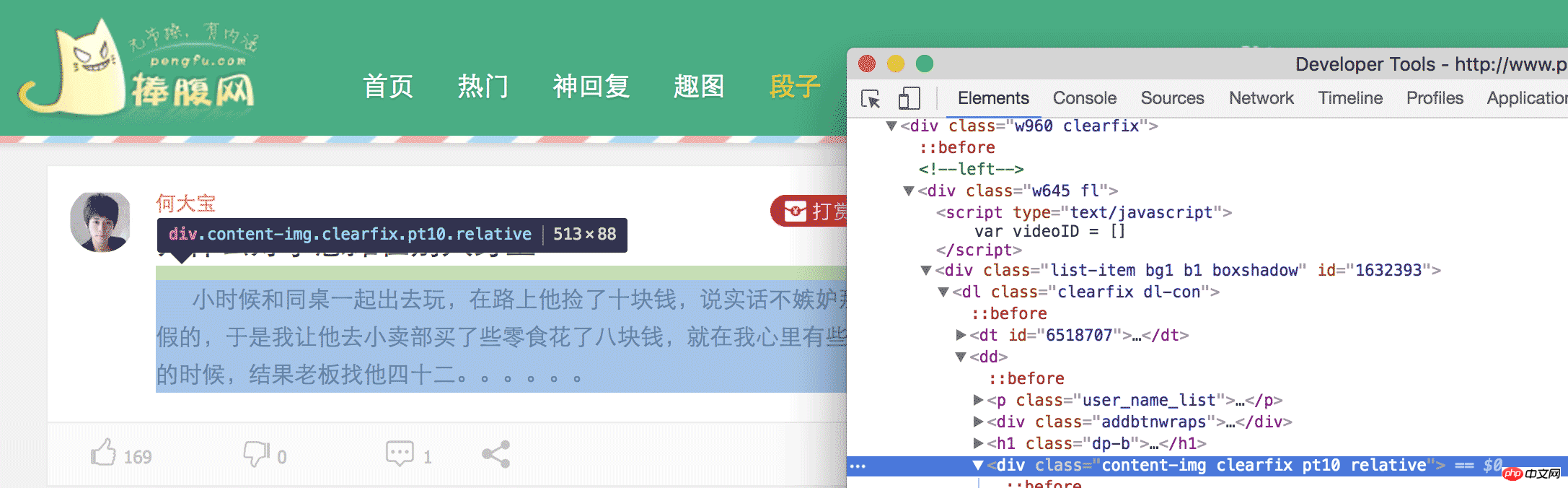
最後に、
の内容が必要なジョークであることがわかります。2 番目のジョークを見ると、同じことが当てはまります。したがって、この Web ページ内のすべての
を見つけて、その中のコンテンツを抽出すれば完了です。
0x03
さて、目的はわかったので、腕まくりをして始めましょう。ここでは python3 を使用します。python2 と python3 の選択については、実現できる機能は自由ですが、いくつかの違いがあります。ただし、依然として python3 を使用することをお勧めします。
必要なコンテンツをプルダウンしたいのですが、まずこの Web ページをプルダウンする必要があります。ここでは、urllib というライブラリを使用して Web 全体を取得する必要があります。ページ。まず、urllibをインポートします
コードは次のとおりです:
import urllib.request as request
次に、リクエストを使用してWebページを取得できます
コードは次のとおりです:
def getHTML(url):
人生は短いです。Web ページをダウンロードするのに 1 行のコードで Python を使用します。Python を使用しない理由はありますか。 return request.urlopen(url).read()
ログイン後にコピー
XML
をすばやく解析して、必要な要素を取得できます。
コードは次のとおりです:
soup = BeautifulSoup(getHTML("http://www.pengfu.com/xiaohua_1.html"))BeautifulSoupを使用してWebページを解析するのはたったの1文ですが、コードを実行すると、このような警告が表示され、パーサーを指定するように求められます。そうしないと、機能しない可能性があります。他のプラットフォームまたはシステムの場合は、エラーを報告してください。
コードは次のとおりです:
/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/site-packages/bs4/init.py:181: UserWarning: No parser was explicitly specified, so I'm using the best available HTML parser for this system ("lxml"). This usually isn't a problem, but if you run this code on another system, or in a different virtual environment, it may use a different parser and behave differently.
The code that caused this warning is on line 64 of the file joke.py. To get rid of this warning, change code that looks like this:
BeautifulSoup([your markup])
to this:
BeautifulSoup([your markup], "lxml")
markup_type=markup_type))パーサーの種類とさまざまなパーサーの違いについては、公式ドキュメントに詳細な手順が記載されています。現時点では、lxml 解析を使用する方が確実です。
修正後
コードは以下の通りです:
soup = BeautifulSoup(getHTML("http://www.pengfu.com/xiaohua_1.html", 'lxml'))このようにすると、上記の警告は出なくなります。
コードは次のとおりです:
p_array = soup.find_all('p', {'class':"content-img clearfix pt10 relative"})find_all
functionを使用して、class = content-img clearfix pt10相対のすべてのpタグを検索し、この配列を走査します。コードは次のとおりです:
for x in p_array: content = x.string
この中でこのようにして、ターゲットの p コンテンツを取得します。この時点で、私たちは目標を達成し、冗談の範囲まで登りました。
しかし、同じ方法でクロールすると、このようなエラーが報告されます
コードは次のとおりです:
raise RemoteDisconnected("Remote end closed connection without" http.client.RemoteDisconnected: Remote end closed connection without response说远端无响应,关闭了链接,看了下网络也没有问题,这是什么情况导致的呢?莫非是我姿势不对?
打开 charles 抓包,果然也没反应。唉,这就奇怪了,好好的一个网站,怎么浏览器可以访问,python 无法访问呢,是不是 UA 的问题呢?看了下 charles,发现,利用 urllib 发起的请求,UA 默认是 Python-urllib/3.5 而在 chrome 中访问 UA 则是 User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36,那会不会是因为服务器根据 UA 来判断拒绝了 python 爬虫。我们来伪装下试试看行不行
代码如下:
def getHTML(url):
head
ers = {'User-Agent': 'User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'}
req = request.Request(url, headers=headers)
return request.urlopen(req).read()这样就把 python 伪装成 chrome 去获取糗百的网页,可以顺利的得到数据。
至此,利用 python 爬取糗百和捧腹网的笑话已经结束,我们只需要分析相应的网页,找到我们感兴趣的元素,利用 python 强大的功能,就可以达到我们的目的,不管是 XXOO 的图,还是内涵段子,都可以一键搞定,不说了,我去找点妹子图看看。
# -*- coding: utf-8 -*-
import sys
import urllib.request as request
from bs4 import BeautifulSoup
def getHTML(url):
headers = {'User-Agent': 'User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'}
req = request.Request(url, headers=headers)
return request.urlopen(req).read()
def get_pengfu_results(url):
soup = BeautifulSoup(getHTML(url), 'lxml')
return soup.find_all('p', {'class':"content-img clearfix pt10 relative"})
def get_pengfu_joke():
for x in range(1, 2):
url = 'http://www.pengfu.com/xiaohua_%d.html' % x
for x in get_pengfu_results(url):
content = x.string
try:
string = content.lstrip()
print(string + '\n\n')
except:
continue
return
def get_qiubai_results(url):
soup = BeautifulSoup(getHTML(url), 'lxml')
contents = soup.find_all('p', {'class':'content'})
restlus = []
for x in contents:
str = x.find('span').getText('\n','<br/>')
restlus.append(str)
return restlus
def get_qiubai_joke():
for x in range(1, 2):
url = 'http://www.qiushibaike.com/8hr/page/%d/?s=4952526' % x
for x in get_qiubai_results(url):
print(x + '\n\n')
return
if name == 'main':
get_pengfu_joke()
get_qiubai_joke()【相关推荐】
1. Python免费视频教程
3. Python基础入门手册
以上がネットワーク段落ページ クローラーの Python 実装ケースの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



