


最近、試験のためにインターネットからソフト試験問題をクロールする予定ですが、クロール中にいくつかの問題が発生しました。次の記事では、主に Python を使用してソフト試験問題をクロールする方法と、IP 自動プロキシの関連情報を紹介します。この記事では、それについて詳しく紹介しています。以下を見てみましょう。
はじめに
最近、ソフトウェア プロフェッショナル レベルの試験があります。以下、ソフト試験と呼びます。試験の復習と準備をより良くするために、www.rkpass からソフト試験の問題を取得する予定です。 CN。
まず最初に、私がどのようにしてソフト試験問題をクロールしたかの物語(ケン)を話させてください。以下の図に示すように、特定のモジュール内のすべての問題を自動的にキャプチャできるようになりました。
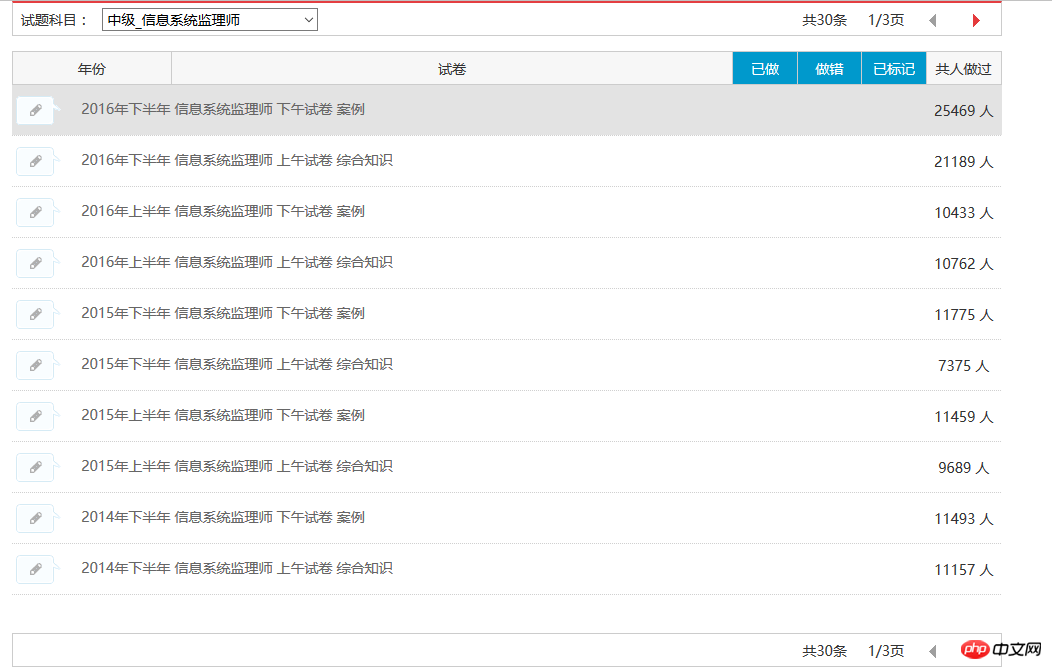
現在、情報システム監督者の試験問題レコード 30 件すべてをキャプチャでき、結果は図に示すとおりです。以下:
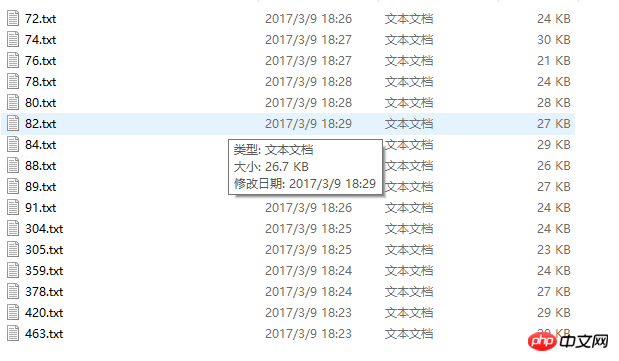
キャプチャされたコンテンツの写真:

一部の情報はキャプチャできますが、キャプチャされた情報システムのスーパーバイザーを例に挙げると、目標が明確であり、コードの品質は高くありません。パラメータは明確です。テスト用紙の情報を短時間で取得するために、昨夜はピットを埋めるのに長い時間を費やしませんでした。
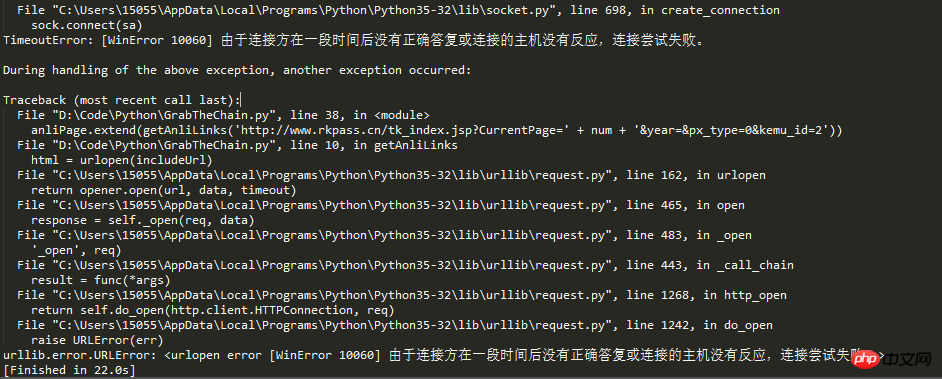
本題に戻りますが、今日このブログを書いているのは、新たな落とし穴に遭遇したからです。記事のタイトルから、リクエストが多すぎたために、Web サイトのクローラー対策メカニズムによって IP がブロックされたのではないかと推測できます。
生きている人間が自分の尿を窒息させて死ぬことはできません。私たちの革命家の偉業は、社会主義の後継者として、解決するために困難に屈したり、山を越えて道路を開いたり、川を渡ったりすることができないことを教えてくれます。知財問題、知財庁というアイデアが出てきたばかりです。
ウェブクローラーによる情報の巡回過程において、巡回頻度がウェブサイトの設定した閾値を超えた場合、アクセスが禁止されます。通常、Web サイトのクローラー対策メカニズムは IP に基づいてクローラーを識別します。
したがって、クローラー開発者は通常、この問題を解決するために 2 つの方法を取る必要があります:
1. クロール速度を遅くし、ターゲット Web サイトへの負荷を軽減します。ただし、これにより単位時間あたりのクロール量が減少します。
2. 2 番目の方法は、プロキシ IP を設定するなどの手段で、クローラー対策メカニズムを突破し、高頻度のクロールを継続することです。ただし、これには複数の安定したプロキシ IP が必要です。
多くのことは言わないで、コードに直接進みましょう:
# IP地址取自国内髙匿代理IP网站:www.xicidaili.com/nn/
# 仅仅爬取首页IP地址就足够一般使用
from bs4 import BeautifulSoup
import requests
import random
#获取当前页面上的ip
def get_ip_list(url, headers):
web_data = requests.get(url, headers=headers)
soup = BeautifulSoup(web_data.text)
ips = soup.find_all('tr')
ip_list = []
for i in range(1, len(ips)):
ip_info = ips[i]
tds = ip_info.find_all('td')
ip_list.append(tds[1].text + ':' + tds[2].text)
return ip_list
#从抓取到的Ip中随机获取一个ip
def get_random_ip(ip_list):
proxy_list = []
for ip in ip_list:
proxy_list.append('http://' + ip)
proxy_ip = random.choice(proxy_list)
proxies = {'http': proxy_ip}
return proxies
#国内高匿代理IP网主地址
url = 'http://www.xicidaili.com/nn/'
#请求头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36'}
#计数器,根据计数器来循环抓取所有页面的ip
num = 0
#创建一个数组,将捕捉到的ip存放到数组
ip_array = []
while num < 1537:
num += 1
ip_list = get_ip_list(url+str(num), headers=headers)
ip_array.append(ip_list)
for ip in ip_array:
print(ip)
#创建随机数,随机取到一个ip
# proxies = get_random_ip(ip_list)
# print(proxies)実行結果のスクリーンショット:
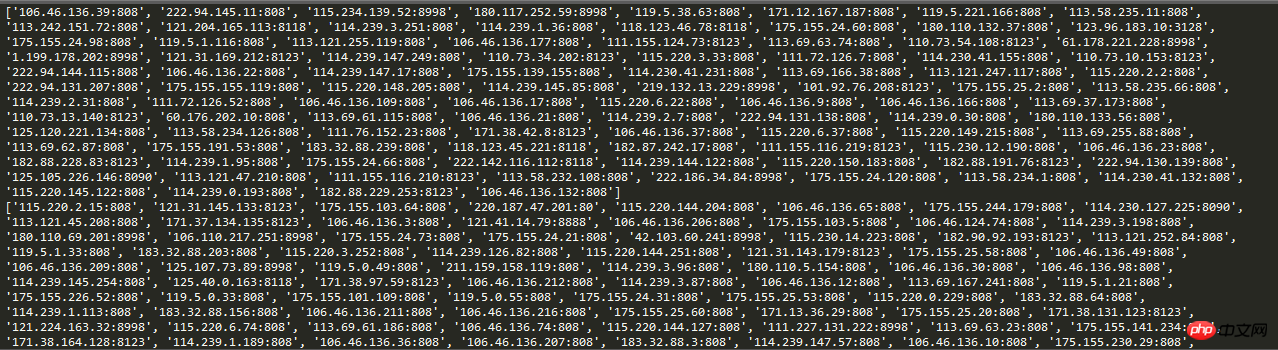
このようにして、クローラーがリクエストするときに、リクエスト IP を自動 IP に設定します。これにより、単純な問題を効果的に回避できます。アンチクローラ機構 IP をブロックして固定する方法が使用されます。
------------------------------------------------ -------------------------------------------------- ----------------------------------
ウェブサイトの安定性を確保するために、誰もがウェブサイトの速度を制御する必要があります。結局のところ、ウェブマスターにとっても簡単ではありません。この記事のテストでは、17 ページの IP のみがキャプチャされました。
概要
以上がPython クローリング テクノロジーでの IP 自動プロキシの例の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。





























![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



