


次のエディターは、Web ページの自動操作とデータ収集を実現するために HTTP リクエストをシミュレートする方法に関する記事をお届けします。編集者はこれが非常に良いものだと思ったので、皆さんの参考として今から共有します。編集者と一緒に覗いてみてください
はじめに
Webページは、ニュースや株価などの情報提供サイトと事業運営カテゴリに分けられます。オンライン商館、OA等の事業運営。もちろん、Weibo、Douban、Taobao など、両方の特性を同時に備えた Web サイトも数多くあります。情報を提供するだけでなく、特定のビジネスも実行します。
通常のインターネットアクセス方法は手動操作が一般的です(説明の必要はありません:D)。ただし、インターネット上の大量のデータのクロール、ページの変更のリアルタイム監視、バッチ操作 (Weibo へのバッチ投稿、タオバオ ショッピングのバッチなど)、注文のブラウジングなど、手動操作では不十分な場合があります。手動操作は大量の操作と反復操作のため、非効率的でエラーが発生しやすくなります。このとき、ソフトウェアを使用して自動で動作させることができます。
Webクローラーや自動バッチ運用事業など、そのようなソフトウェアをいくつか開発してきました。使用されるコア機能の 1 つは、HTTP リクエストをシミュレートすることです。もちろん、HTTPS プロトコルが使用されることもあります。通常、さらなる操作を実行するには、Web サイトにログインする必要があります。最も重要な点は、Web サイトのビジネス プロセスを理解すること、つまり、いつ、どのように送信するかを知ることです。特定の操作を実行するためにどのページに移動するのか? 最後に、データを抽出したり、操作の結果を知るには、HTML を解析する必要もあります。この記事ではそれらを一つずつ説明していきます。
この記事ではコードを表示するために C# 言語を使用しています。もちろん、原理は同じです。 JD.com へのログインを例に挙げます。
HTTP リクエストのシミュレート
C# HTTP リクエストをシミュレートするには、次のクラスを使用する必要があります:
•WebRequest
•HttpWebRequest
•HttpWebResponse
• Stream
まずリクエストオブジェクト(HttpWebRequest)を作成し、関連するHeaders情報を設定してからリクエストを送信します(POSTの場合は、ターゲットアドレスがアクセス可能な場合、フォームデータをネットワークストリームに書き込みます)。応答オブジェクト ( HttpWebResponse ) を取得すると、返された結果は、対応するオブジェクトのネットワーク ストリームから読み取ることができます。
サンプルコードは次のとおりです:
String contentType = "application/x-www-form-urlencoded"; String accept = "image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, application/x-shockwave-flash, application/x-silverlight, application/vnd.ms-excel, application/vnd.ms-powerpoint, application/msword, application/x-ms-application, application/x-ms-xbap, application/vnd.ms-xpsdocument, application/xaml+xml, application/x-silverlight-2-b1, */*"; String userAgent = "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.116 Safari/537.36"; public String Get(String url, String encode = DEFAULT_ENCODE) { HttpWebRequest request = WebRequest.Create(url) as HttpWebRequest; InitHttpWebRequestHeaders(request); request.Method = "GET"; var html = ReadHtml(request, encode); return html; } public String Post(String url, String param, String encode = DEFAULT_ENCODE) { Encoding encoding = System.Text.Encoding.UTF8; byte[] data = encoding.GetBytes(param); HttpWebRequest request = WebRequest.Create(url) as HttpWebRequest; InitHttpWebRequestHeaders(request); request.Method = "POST"; request.ContentLength = data.Length; var outstream = request.GetRequestStream(); outstream.Write(data, 0, data.Length); var html = ReadHtml(request, encode); return html; } private void InitHttpWebRequestHeaders(HttpWebRequest request) { request.ContentType = contentType; request.Accept = accept; request.UserAgent = userAgent; } private String ReadHtml(HttpWebRequest request, String encode) { HttpWebResponse response = request.GetResponse() as HttpWebResponse; Stream stream = response.GetResponseStream(); StreamReader reader = new StreamReader(stream, Encoding.GetEncoding(encode)); String content = reader.ReadToEnd(); reader.Close(); stream.Close(); return content; }
Get メソッドと Post メソッドのコードのほとんどが類似していることがわかります。そのため、コードはカプセル化され、同じコードが新しい関数として抽出されます。
HTTPSリクエスト
ウェブサイトがhttpsプロトコルを使用している場合、上記のコードで次のエラーが発生する可能性があります:
The underlying connection was closed: Could not establish trust relationship for
理由は証明書エラーです。ブラウザで開くと、次のページが表示されます。
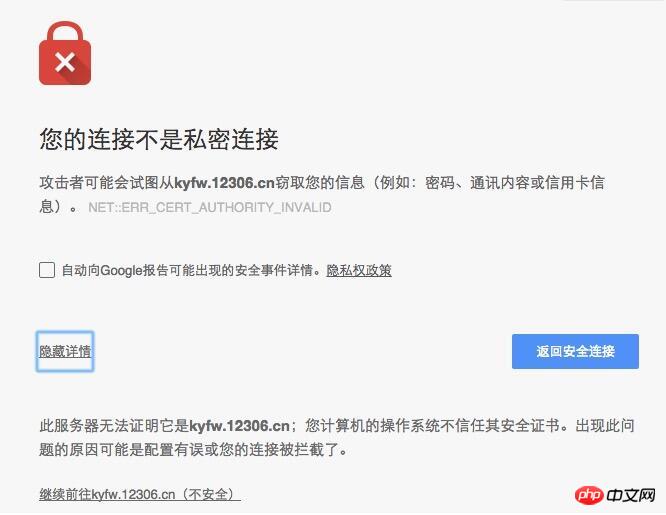
クリックすると xxx.xx (安全ではありません) に進むと、引き続き Web ページを開くことができます。プログラムでは、このステップをシミュレートするだけで続行できます。 C# では、ServicePointManager.ServerCertificateValidationCallback プロキシを設定し、プロキシ メソッドで直接 true を返すだけで済みます。
private HttpWebRequest CreateHttpWebRequest(String url) { HttpWebRequest request; if (IsHttpsProtocol(url)) { ServicePointManager.ServerCertificateValidationCallback = new RemoteCertificateValidationCallback(CheckValidationResult); request = WebRequest.Create(url) as HttpWebRequest; request.ProtocolVersion = HttpVersion.Version10; } else { request = WebRequest.Create(url) as HttpWebRequest; } return request; } private HttpWebRequest CreateHttpWebRequest(String url) { HttpWebRequest request; if (IsHttpsProtocol(url)) { ServicePointManager.ServerCertificateValidationCallback = new RemoteCertificateValidationCallback(CheckValidationResult); request = WebRequest.Create(url) as HttpWebRequest; request.ProtocolVersion = HttpVersion.Version10; } else { request = WebRequest.Create(url) as HttpWebRequest; } return request; }
このようにして、https ウェブサイトに正常にアクセスできるようになります。
本人認証のために Cookie を記録する
一部の Web サイトでは、次のステップを実行するためにログインが必要です。たとえば、JD.com でのショッピングでは最初にログインする必要があります。 Web サイト サーバーはセッションを使用してクライアント ユーザーを記録し、各セッションはユーザーに対応し、前のコードはリクエストが作成されるたびにセッションを再確立します。ログインに成功した場合でも、次のステップで新しい接続が作成されるため、ログインは無効になります。現時点では、この一連のリクエストが同じセッションからのものであるとサーバーに認識させる方法を見つける必要があります。
クライアントは Cookie のみを持ち、次のリクエスト時にクライアントがどのセッションに対応するかをサーバーに知らせるために、Cookie にセッション ID の記録が存在します。したがって、Cookie が同じである限り、サーバーにとっては同じユーザーになります。
この時点では CookieContainer を使用する必要があります。名前が示すように、これは Cookie コンテナーです。 HttpWebRequest には CookieContainer プロパティがあります。各リクエストの Cookie が CookieContainer に記録されている限り、次のリクエストでは HttpWebRequest の CookieContainer 属性が設定されます。Cookie は同じであるため、サーバーにとっては同じユーザーになります。
public String Get(String url, String encode = DEFAULT_ENCODE) { HttpWebRequest request = WebRequest.Create(url) as HttpWebRequest; InitHttpWebRequestHeaders(request); request.Method = "GET"; request.CookieContainer = cookieContainer; HttpWebResponse response = request.GetResponse() as HttpWebResponse; foreach (Cookie c in response.Cookies) { cookieContainer.Add(c); } }
Web サイトの分析とデバッグ
上記で HTTP リクエストのシミュレーションが実現されました。もちろん、最も重要なのは分析ステーションです。一般的な状況としては、ドキュメントがなく、Web サイト開発者も見つからず、探索はブラック ボックスから始まります。多くの分析ツールがあります。Chrome+ プラグイン Advanced Rest Client を使用すると、Web ページを開いたときにバックグラウンドでどのような操作やリクエストが行われたかを知ることができます。
たとえば、JD.com にログインすると、次のデータが送信されます:
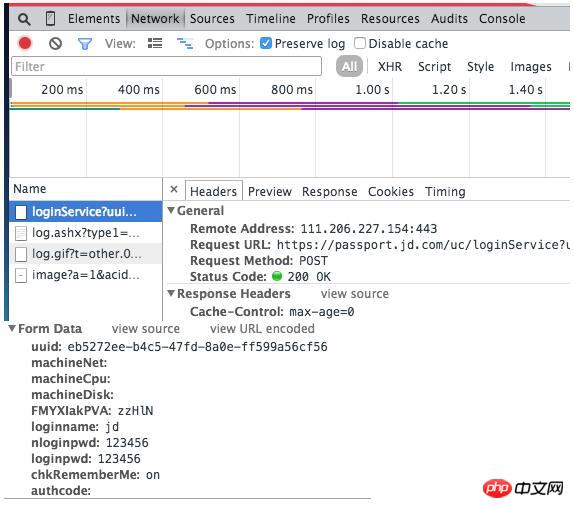
また、Jingdong のパスワードが実際には平文で送信されていることがわかり、セキュリティが非常に懸念されています。
返されたデータも確認できます:

返されたデータは JSON データですが、u8d26 これは何ですか?実際、これは Unicode エンコードです。Unicode エンコード変換ツールを使用して、読み取り可能なテキストに変換できます。たとえば、今回返される結果は、「アカウント名とパスワードが一致しません。再入力してください」です。
HTMLを解析する
HTTPリクエストによって取得されるデータは通常HTML形式ですが、場合によってはJsonやXMLの場合もあります。有用なデータを抽出するには解析が必要です。 HTML を解析するコンポーネントは次のとおりです:
•HTML パーサー。 Java/C#/Python などの複数のプラットフォームで利用できます。長い間使っていない。
•HTMLアジリティパック。 XPath 経由で HMTL を解析する。いつも使っています。 XPath チュートリアルについては、W3School の XPath チュートリアルを参照してください。
結論
この記事では、HTTP/HTTPS リクエストのシミュレートから Cookie、Web サイトの分析、HTML の解析まで、シミュレートされた自動 Web ページ操作を開発するために必要なスキルを紹介します。このコードは使用方法を説明することを目的としており、完全なコードではないため、直接実行できない場合があります。
以上がWebページの自動操作とデータ収集を実現するHTTPリクエストをシミュレートする手法(コレクション)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。





























![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



