


現在のプロジェクトでは、js でレンダリングされた Web サイトからデータをキャプチャする必要があります。一般的に使用される httpclient を使用してキャプチャされたページにはデータがありません。 Baidu で検索した結果、誰もが推奨する解決策は PhantomJS を使用することです。 PhantomJS はインターフェースのない Webkit ブラウザーで、js を使用してブラウザーと同じ効果でページをレンダリングできます。 Selenium は Web テスト フレームワークです。 Selenium を使用して PhantomJS を操作するのは完璧にマッチします。しかし、インターネット上のサンプルのほとんどは Python で作られています。どうしようもなく、Python をダウンロードしてチュートリアルに従ったのですが、Selenium のインポートの問題で行き詰まってしまいました。そこで、C# では利用できないとは信じられなかったので、諦めて通常の C# を使用することにしました。 30 分ほどいじった後、完了しました (Python をいじるのは 1 時間)。私のような C# 初心者が PhantomJS を使用できるように、このブログ投稿を記録します。
ステップ 1: Visual Studio 2017 を開き、新しいコンソール プロジェクトを作成し、nuget パッケージ マネージャーを開きます。
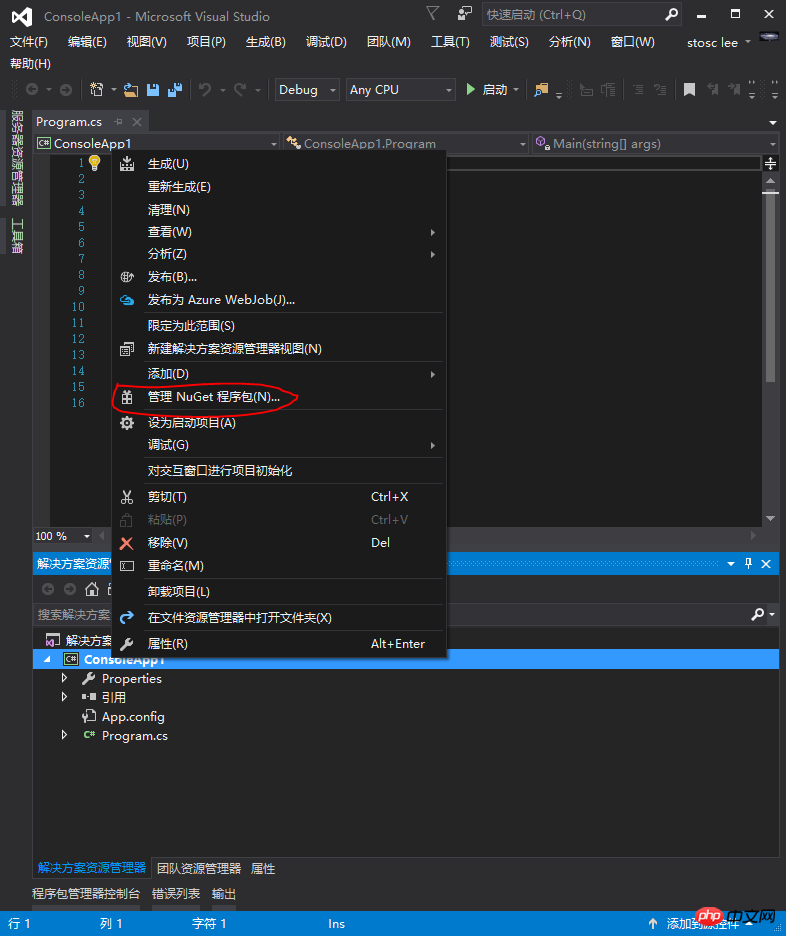
パート 2: Selenium を検索し、Selenium.WebDriver をインストールします。注: プロキシを使用する場合は、バージョン 3.0.0 をインストールするのが最善です。
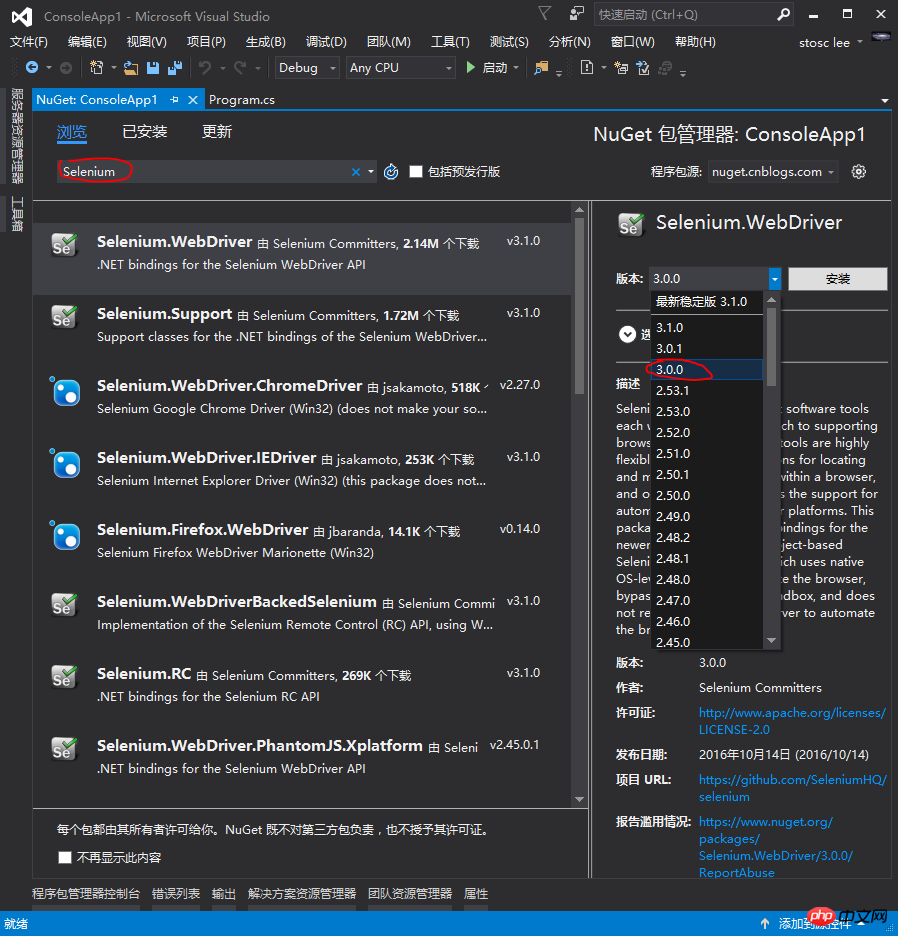
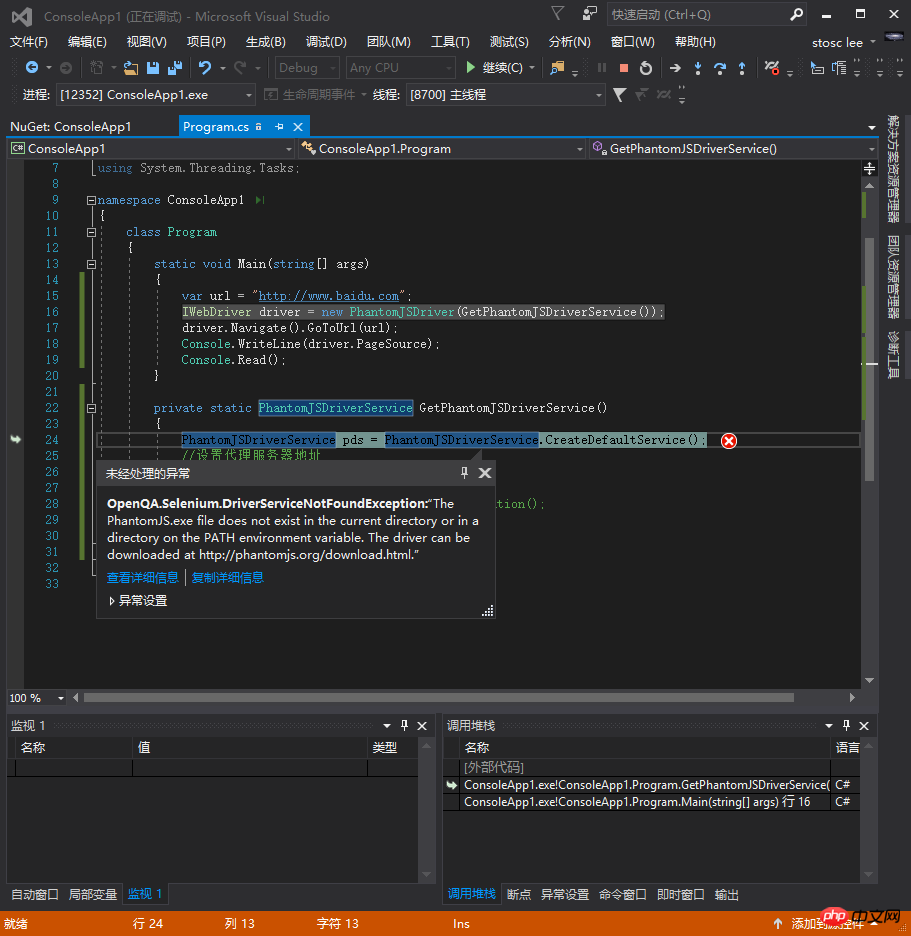
ステップ 3: 以下に示すようにコードを記述します。ただし、実行するとエラーが報告されます。理由は、PhantomJS.exe が見つからないためです。現時点では、1 つダウンロードすることも、ステップ 4 に進むこともできます。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
|
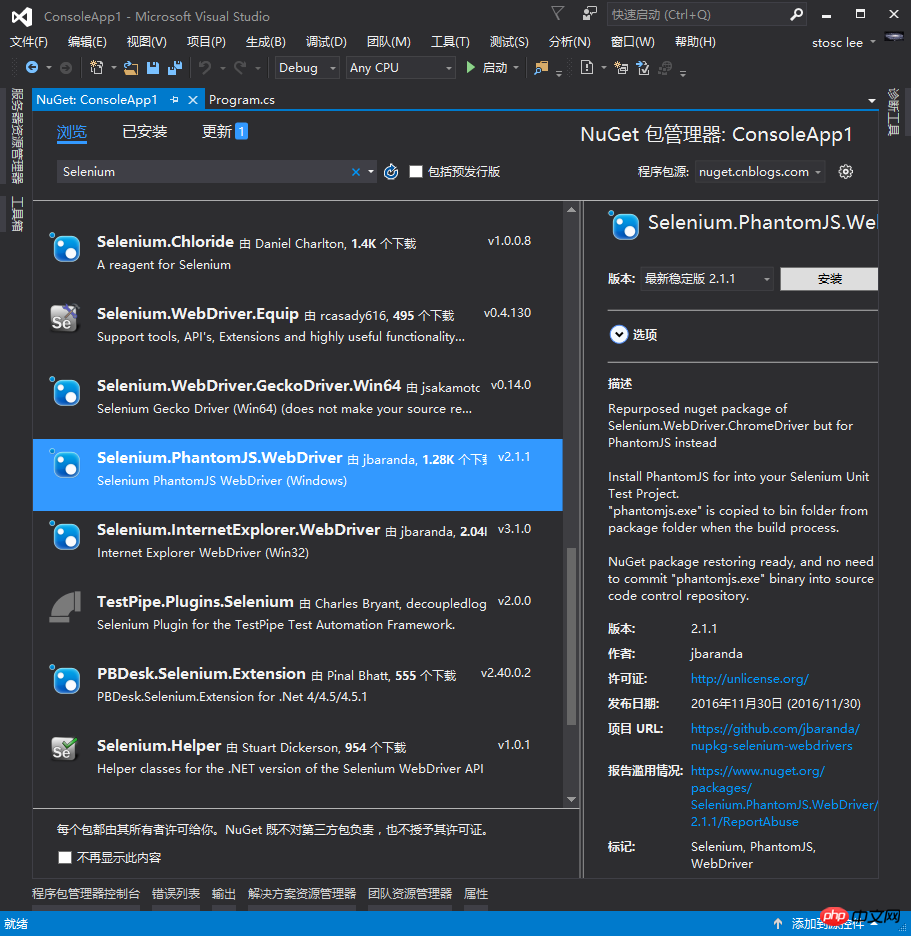
ステップ 4: nuget を開いて Selenium.PhantomJS.WebDriver パッケージをインストールします。
ステップ 5: 走ります。 phantomjs.exe が自動的にダウンロードされていることがわかります。
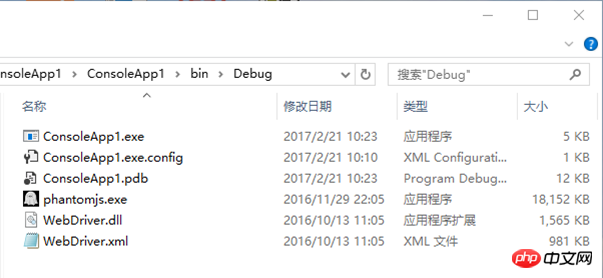
さて、これでデータキャプチャビジネスを始めることができます。
以上がSelenium+PhantomJS を使用してデータをキャプチャする C# の詳細な説明の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



