


MySQL のインデックスは B+tree を介しています。 B+tree はバランス型バイナリ ツリーの一種であるため、クエリ速度が非常に高速です。
インデックスは主にクラスター化インデックスと補助インデックスに分けられます:
クラスター化インデックス: mysqlのデータは主キーのクラスター化インデックスを介して保存されるため、リーフノードは各行のデータを保存するため、主キーを使用します。
これが非常に高速である理由は、主キーがクラスター化インデックスであるためですが、実際の使用では、そのような B+ ツリーが 1 つだけ構築されるため、主キーが一意である理由が説明できます。
インターネット上の画像の引用:
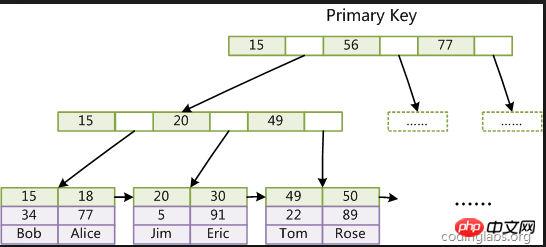
各層での検索は IO 操作であり、一般的に B+tree 層の数は 2 ~ 4 であるため、最悪の場合のみ実行する必要があります。 4 回の IO 操作。
補助インデックス: 補助インデックスとクラスター化インデックスの違いは、すべてのデータがリーフ ノードに保存されるわけではなく、データの場所が保存されることです。これは、補助インデックスを使用してデータを検索し、クラスター化インデックスのツリーを通じて詳細情報を検索することと同じです。
インターネット上の画像からの引用:
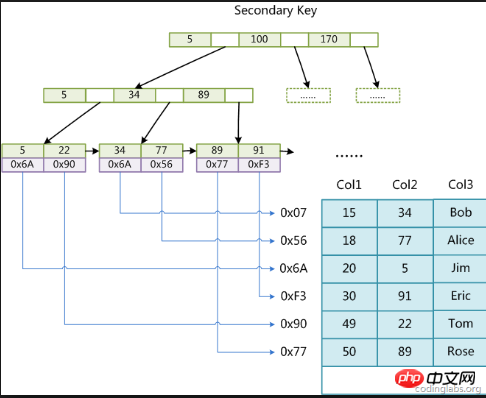 この画像は論理的な画像ですが、最下層はリーフ ノードを介してクラスター化インデックスを指します。つまり、最初のタイプの画像を通過する必要があります。次は
この画像は論理的な画像ですが、最下層はリーフ ノードを介してクラスター化インデックスを指します。つまり、最初のタイプの画像を通過する必要があります。次は
ロジック。
最終結果は、クラスター化インデックス ツリーを指す複数の補助インデックス ツリーになります
(図は本当に醜いです)
いつインデックスを作成すべきかについてこれはツリーなので、 through 二分探索法で検索するため、whereの条件として使用するのに適しており、値の範囲も広く、インデックスを作成するのに適しています。範囲が狭いもの (is_delete、sex などの列挙型) には適していません。
特定の状況については、show Index を通じて分析できます:
show index from company_related_person
結果:
 次にカーディナリティを通じて計算します
次にカーディナリティを通じて計算します
select 105/(select count(*) from company_related_person) from DUAL
ここで得られた結果は 0.913 です (この値はストレージ容量に関連しており、これが最適です)この値が 1 に近いほど、インデックスの効率が高くなります。計算された値が非常に小さい場合は、インデックスを作成しないことをお勧めします
Explain
EXPLAIN select * from company_related_person where company_id='2'
Output
によるインデックス  key は現在使用されているインデックス列を表します。最後の追加は、どのメソッドが使用されるかを示します。ここで、「インデックスを使用」は、ディスクが直接読み取られることを示します。 。
key は現在使用されているインデックス列を表します。最後の追加は、どのメソッドが使用されるかを示します。ここで、「インデックスを使用」は、ディスクが直接読み取られることを示します。 。
SQL パフォーマンス最適化の目標: 少なくとも範囲レベルに達すること。要件は参照レベルであり、const にできればそれが最善です。
1) 定数 1 つのテーブルには一致する行 (主キーまたは一意のインデックス) が最大 1 つあり、最適化フェーズ中にデータを読み取ることができます。
2) ref は、通常のインデックスの使用を指します。
3) range はインデックスの範囲取得を実行します
4) インデックスはディスクから直接読み取ることを意味します
上の図からも、ref を使用していることがわかります
インデックスとキーの違いについて:インデックスを作成するときに、「インデックスとキーの違いは何ですか?」という質問がよくあります。 。キーは、主キー (Primary Key)、外部キー (Foreign Key) など、データの整合性チェックや一意性制約に使用される、リレーショナル モデル理論の一部であるキー値です。インデックスは実装レベルにあります。たとえば、テーブルの任意の列にインデックスを付けることができ、インデックス付きの列が SQL ステートメントの Where 条件に含まれる場合、データの場所を高速に取得できるようになります。 Unique Index については、インデックスの 1 つの種類にすぎません。Unique Index の確立は、この列のデータを繰り返すことができないことを意味します。
以上がMySQLインデックスの詳しい説明の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



