


このセクションでは主に、いくつかの特定の種類の最適化クエリについて説明します。
(1) カウントクエリの最適化
(2) 関連クエリ
(3) サブクエリ
(4) GROUP BY と DISTINCT の最適化
(5) LIMIT ページングの最適化
COUNT() 集計関数の役割:
(1) 特定の列の値の数をカウントし、行数をカウントすることもできます。 列の値をカウントする場合、列の値は空ではない必要があることに注意してください(NULLはカウントしません)
(2) 結果セット内の行数をカウントします。列の値を空にできない場合、テーブル内の行数がカウントされます。ただし、結果セット内の行数を取得するには COUNT() を使用する必要があります。 Wildcard は、すべての列の値を直接無視し、最適化のために行数を直接計算します。
MyISAM ストレージ エンジンの場合、MyISAM 自体がすでに合計行数を格納しているため、where クエリ条件が 1 つのテーブルに制限されていない場合、COUNT(*) は非常に高速です。 where 修飾条件がある場合は、クエリ統計も必要です。
以下は簡単な最適化の使用例です:
(1) 最適化 1:
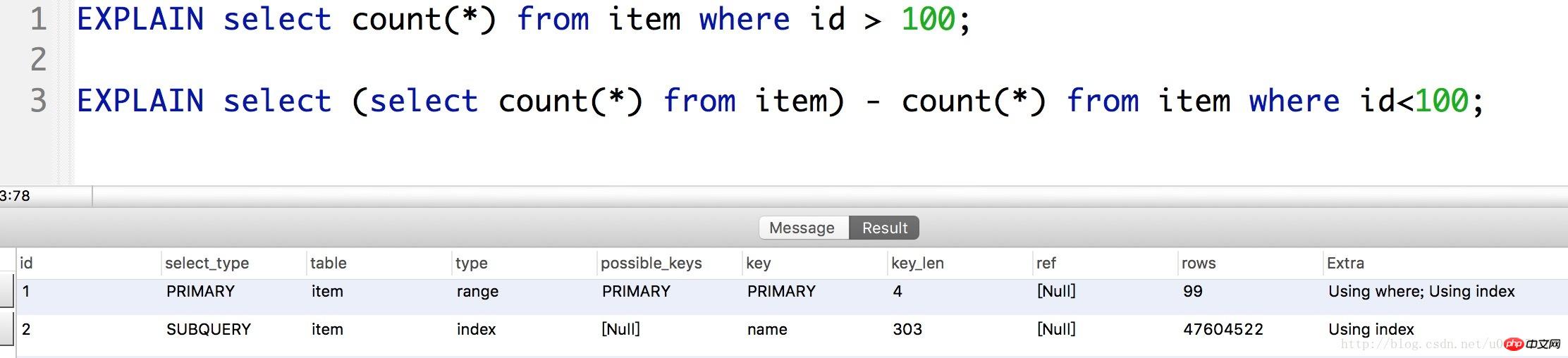
id > 100 のレコードを直接チェックすると、2,000 万行を超えるレコードがスキャンされることがわかります。ただし、COUNT() 機能により、count() - (id
(2) 最適化 2:
さらに、カバリングインデックスを使用する別の最適化方法もあります。
(1) ON 句または USING 句の列にインデックスがあることを確認します。インデックスを作成するときは、テーブル A とテーブル B が列 c に関連付けられている場合、オプティマイザの関連付け順序が B、A の場合、テーブル A にインデックスを作成するだけで済みます。未使用のインデックスはストレージを占有します
(2) Group by 操作と order by 操作の 式 には、1 つのテーブル内の列のみが含まれるようにしてください。このようにして、MySQL でインデックス最適化を使用することが可能です。
一時テーブルが count(*) のように非常に小さい場合を除き、サブクエリは一時テーブルを生成するため、サブクエリの使用をできるだけ少なくします。
GROUP BY と DISTINCT を最適化する最も効果的な方法は、インデックスを使用することです。
インデックスを使用できない場合、group by は 2 つの戦略を使用します。グループ化のための一時テーブルまたはファイルの並べ替えです。
グループ化するすべての列にインデックスを付ける必要があります。例:
select product, count(*) from orders group by product;
のようなクエリの場合、商品にインデックスを付ける必要があります。
ページング操作を実行するとき、通常、一部のデータはオフセットを通じてクエリされます。説明した order by と相まって、パフォーマンスは全体的に良好です。
order by 列に必ずインデックスを追加してください。
ただし、制限 10000、10 の場合、ターゲットの 10 レコードを取得するには、まず前の 10000 レコードをクエリする必要があります。この場合、コストが非常に高くなります。最適化する最も簡単な方法は、カバーリング インデックスを使用することです。
以上が高パフォーマンスMySQL - 特定タイプのクエリの最適化について詳しく説明の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



