1. はじめに
前回の記事では、ブログ、Wikipedia InfoBox、画像をクロールするために Python を使用してソース コードを解析する方法を紹介しました。記事のリンクは次のとおりです。
【Python学習】Wikipediaプログラミング言語のメッセージボックスを簡単にクロールする
【Python学習】ブログの記事やアイデアをクロールする簡単なWebクローラー
【Python学習】画像サイトギャラリー内の画像を簡単にクローリング
コアコードは以下の通り:
# coding=utf-8
import urllib
import re
#下载静态HTML网页
url='http://www.csdn.net/'
content = urllib.urlopen(url).read()
open('csdn.html','w+').write(content)
#获取标题
title_pat=r'(?<=<title>).*?(?=</title>)'
title_ex=re.compile(title_pat,re.M|re.S)
title_obj=re.search(title_ex, content)
title=title_obj.group()
print title
#获取超链接内容
href = r'<a href=.*?>(.*?)</a>'
m = re.findall(href,content,re.S|re.M)
for text in m:
print unicode(text,'utf-8')
break #只输出一个urlログイン後にコピー
>>>
CSDN.NET - 全球最大中文IT社区,为IT专业技术人员提供最全面的信息传播和服务平台
登录
>>>
ログイン後にコピー
コアコード画像のダウンロードの手順は次のとおりです。
import os
import urllib
class AppURLopener(urllib.FancyURLopener):
version = "Mozilla/5.0"
urllib._urlopener = AppURLopener()
url = "http://creatim.allyes.com.cn/imedia/csdn/20150228/15_41_49_5B9C9E6A.jpg"
filename = os.path.basename(url)
urllib.urlretrieve(url , filename)ログイン後にコピー
1. 正規表現は、HTML ソース コードに依存するのではなく、HTML ソース コードによって制約されます。より抽象的な構造。Web ページ構造では、小さな変更によりプログラムが中断される可能性があります。
2. プログラムは、実際の HTML ソース コードに基づいてコンテンツを分析する必要があり、& などの文字エンティティなどの HTML 機能に遭遇する可能性があり、
などの別のコンテンツを指定する必要があります。アイコンのハイパーリンク、下付き文字など。
3. 正規表現は完全に読み取れるわけではなく、より複雑な HTML コードやクエリ式は乱雑になります。
「Python Basics Tutorial (2nd Edition)」では 2 つの解決策が採用されています。1 つ目は Tidy (Python ライブラリ) プログラムと XHTML 解析を使用することです。2 つ目は BeautifulSoup ライブラリを使用することです。
II. Beautiful Soupライブラリのインストールと紹介
Beautiful SoupはPython で書かれた HTML/XML パーサーを使用できます。不規則なマークアップを適切に処理し、解析ツリーを生成します。 これは、解析ツリーの移動、検索、変更に使用されるシンプルで一般的に使用される操作を提供します。プログラミング時間を大幅に節約できます。 この本にあるように、「それらの悪い Web ページはあなたが書いたものではなく、あなたはそこからデータを取得しようとしただけです。今では、HTML がどのように見えるかを気にする必要はなく、パーサーがそれを行います」それはあなたのためです。」
アドレスのダウンロード:インストールプロセスは以下に示すように次のように示されています:python setup.pyインストール
公式を使用して、TifulSoupの使用法の簡単な説明。 「不思議の国のアリス」の例:
#!/usr/bin/python
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
#获取BeautifulSoup对象并按标准缩进格式输出
soup = BeautifulSoup(html_doc)
print(soup.prettify())
ログイン後にコピー
出力コンテンツ
は、次のように標準のインデント形式構造
に従って出力されます: 
<html>
<head>
<title>
The Dormouse's story
</title>
</head>
<body>
<p class="title">
<b>
The Dormouse's story
</b>
</p>
<p class="story">
Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1">
Elsie
</a>
,
<a class="sister" href="http://example.com/lacie" id="link2">
Lacie
</a>
and
<a class="sister" href="http://example.com/tillie" id="link3">
Tillie
</a>
;
and they lived at the bottom of a well.
</p>
<p class="story">
...
</p>
</body>
</html>ログイン後にコピー
以下は簡単ですそして BeautifulSoup ライブラリの簡単な紹介: (参考: 公式ドキュメント)
'''获取title值'''
print soup.title
# <title>The Dormouse's story</title>
print soup.title.name
# title
print unicode(soup.title.string)
# The Dormouse's story
'''获取<p>值'''
print soup.p
# <p class="title"><b>The Dormouse's story</b></p>
print soup.a
# <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
'''从文档中找到<a>的所有标签链接'''
print soup.find_all('a')
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
for link in soup.find_all('a'):
print(link.get('href'))
# //m.sbmmt.com/
# //m.sbmmt.com/
# //m.sbmmt.com/
print soup.find(id='link3')
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>ログイン後にコピー
記事内のすべてのテキストコンテンツを取得したい場合、コードは次のとおりです:
'''从文档中获取所有文字内容'''
print soup.get_text()
# The Dormouse's story
#
# The Dormouse's story
#
# Once upon a time there were three little sisters; and their names were
# Elsie,
# Lacie and
# Tillie;
# and they lived at the bottom of a well.
#
# ...
ログイン後にコピー
同时在这过程中你可能会遇到两个典型的错误提示:
1.ImportError: No module named BeautifulSoup
当你成功安装BeautifulSoup 4库后,“from BeautifulSoup import BeautifulSoup”可能会遇到该错误。

其中的原因是BeautifulSoup 4库改名为bs4,需要使用“from bs4 import BeautifulSoup”导入。
2.TypeError: an integer is required
当你使用“print soup.title.string”获取title的值时,可能会遇到该错误。如下:
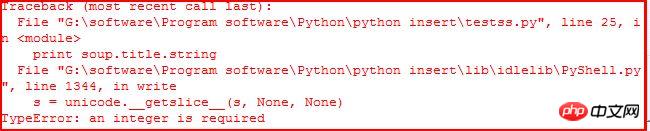
它应该是IDLE的BUG,当使用命令行Command没有任何错误。参考:stackoverflow。同时可以通过下面的代码解决该问题:
print unicode(soup.title.string)
print str(soup.title.string)
三. Beautiful Soup常用方法介绍
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种:Tag、NavigableString、BeautifulSoup、Comment|
1.Tag标签
tag对象与XML或HTML文档中的tag相同,它有很多方法和属性。其中最重要的属性name和attribute。用法如下:
#!/usr/bin/python
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" id="start"><b>The Dormouse's story</b></p>
"""
soup = BeautifulSoup(html)
tag = soup.p
print tag
# <p class="title" id="start"><b>The Dormouse's story</b></p>
print type(tag)
# <class 'bs4.element.Tag'>
print tag.name
# p 标签名字
print tag['class']
# [u'title']
print tag.attrs
# {u'class': [u'title'], u'id': u'start'}ログイン後にコピー
使用BeautifulSoup每个tag都有自己的名字,可以通过.name来获取;同样一个tag可能有很多个属性,属性的操作方法与字典相同,可以直接通过“.attrs”获取属性。至于修改、删除操作请参考文档。
2.NavigableString
字符串常被包含在tag内,Beautiful Soup用NavigableString类来包装tag中的字符串。一个NavigableString字符串与Python中的Unicode字符串相同,并且还支持包含在遍历文档树和搜索文档树中的一些特性,通过unicode()方法可以直接将NavigableString对象转换成Unicode字符串。
print unicode(tag.string)
# The Dormouse's story
print type(tag.string)
# <class 'bs4.element.NavigableString'>
tag.string.replace_with("No longer bold")
print tag
# <p class="title" id="start"><b>No longer bold</b></p>ログイン後にコピー
这是获取“The Dormouse's story
”中tag = soup.p的值,其中tag中包含的字符串不能编辑,但可通过函数replace_with()替换。
NavigableString 对象支持遍历文档树和搜索文档树 中定义的大部分属性, 并非全部。尤其是一个字符串不能包含其它内容(tag能够包含字符串或是其它tag),字符串不支持 .contents 或 .string 属性或 find() 方法。
如果想在Beautiful Soup之外使用 NavigableString 对象,需要调用 unicode() 方法,将该对象转换成普通的Unicode字符串,否则就算Beautiful Soup已方法已经执行结束,该对象的输出也会带有对象的引用地址。这样会浪费内存。
3.Beautiful Soup对象
该对象表示的是一个文档的全部内容,大部分时候可以把它当做Tag对象,它支持遍历文档树和搜索文档树中的大部分方法。
注意:因为BeautifulSoup对象并不是真正的HTML或XML的tag,所以它没有name和 attribute属性,但有时查看它的.name属性可以通过BeautifulSoup对象包含的一个值为[document]的特殊实行.name实现——soup.name。
Beautiful Soup中定义的其它类型都可能会出现在XML的文档中:CData , ProcessingInstruction , Declaration , Doctype 。与 Comment 对象类似,这些类都是 NavigableString 的子类,只是添加了一些额外的方法的字符串独享。
4.Command注释
Tag、NavigableString、BeautifulSoup几乎覆盖了html和xml中的所有内容,但是还有些特殊对象容易让人担心——注释。Comment对象是一个特殊类型的NavigableString对象。
markup = "<b><!--Hey, buddy. Want to buy a used parser?--></b>"
soup = BeautifulSoup(markup)
comment = soup.b.string
print type(comment)
# <class 'bs4.element.Comment'>
print unicode(comment)
# Hey, buddy. Want to buy a used parser?
ログイン後にコピー
介绍完这四个对象后,下面简单介绍遍历文档树和搜索文档树及常用的函数。
5.遍历文档树
一个Tag可能包含多个字符串或其它的Tag,这些都是这个Tag的子节点。BeautifulSoup提供了许多操作和遍历子节点的属性。引用官方文档中爱丽丝例子:
操作文档最简单的方法是告诉你想获取tag的name,如下:
soup.head# <head><title>The Dormouse's story</title></head>soup.title# <title>The Dormouse's story</title>soup.body.b# <b>The Dormouse's story</b>
ログイン後にコピー
注意:通过点取属性的放是只能获得当前名字的第一个Tag,同时可以在文档树的tag中多次调用该方法如soup.body.b获取标签中第一个标签。
如果想得到所有的标签,使用方法find_all(),在前面的Python爬取维基百科等HTML中我们经常用到它+正则表达式的方法。
soup.find_all('a')# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
ログイン後にコピー
子节点:在分析HTML过程中通常需要分析tag的子节点,而tag的 .contents 属性可以将tag的子节点以列表的方式输出。字符串没有.contents属性,因为字符串没有子节点。
head_tag = soup.head
head_tag
# <head><title>The Dormouse's story</title></head>
head_tag.contents
[<title>The Dormouse's story</title>]
title_tag = head_tag.contents[0]
title_tag
# <title>The Dormouse's story</title>
title_tag.contents
# [u'The Dormouse's story']
ログイン後にコピー
通过tag的 .children 生成器,可以对tag的子节点进行循环:
for child in title_tag.children:
print(child)
# The Dormouse's storyログイン後にコピー
子孙节点:同样 .descendants 属性可以对所有tag的子孙节点进行递归循环:
for child in head_tag.descendants:
print(child)
# <title>The Dormouse's story</title>
# The Dormouse's storyログイン後にコピー
父节点:通过 .parent 属性来获取某个元素的父节点.在例子“爱丽丝”的文档中,标签是标签的父节点,换句话就是增加一层标签。<br/> <span style="color:#ff0000">注意:文档的顶层节点比如<html>的父节点是 BeautifulSoup 对象,BeautifulSoup 对象的 .parent 是None。</span><br/></span></strong></p><div class="code" style="position:relative; padding:0px; margin:0px;"><pre style="overflow-x:auto; overflow-y:hidden; padding:5px; line-height:15.6000003814697px; border-top-width:1px; border-bottom-width:1px; border-style:solid none; border-top-color:rgb(170,204,153); border-bottom-color:rgb(170,204,153); background-color:rgb(238,255,204)">title_tag = soup.titletitle_tag# <title>The Dormouse's story</title>title_tag.parent# <head><title>The Dormouse's story</title></head>title_tag.string.parent# <title>The Dormouse's story</title></pre><div class="contentsignin">ログイン後にコピー</div></div><p><strong><span style="font-size:18px"> <span style="color:#ff0000">兄弟节点</span>:因为<b>标签和<c>标签是同一层:他们是同一个元素的子节点,所以<b>和<c>可以被称为兄弟节点。一段文档以标准格式输出时,兄弟节点有相同的缩进级别.在代码中也可以使用这种关系。</span></strong><br/></p><div class="code" style="position:relative; padding:0px; margin:0px;"><pre style="overflow-x:auto; overflow-y:hidden; padding:5px; color:rgb(51,51,51); line-height:15.6000003814697px; border-top-width:1px; border-bottom-width:1px; border-style:solid none; border-top-color:rgb(170,204,153); border-bottom-color:rgb(170,204,153); background-color:rgb(238,255,204)">sibling_soup = BeautifulSoup("<a><b>text1</b><c>text2</c></b></a>")print(sibling_soup.prettify())# <html># <body># <a># <b># text1# </b># <c># text2# </c># </a># </body># </html></pre><div class="contentsignin">ログイン後にコピー</div></div><p><strong><span style="font-size:18px"> <span style="color:#ff0000">在文档树中,使用 .next_sibling 和 .previous_sibling 属性来查询兄弟节点。<b>标签有.next_sibling 属性,但是没有.previous_sibling 属性,因为<b>标签在同级节点中是第一个。同理<c>标签有.previous_sibling 属性,却没有.next_sibling 属性:</span></span></strong><br/></p><div class="code" style="position:relative; padding:0px; margin:0px;"><pre style="overflow-x:auto; overflow-y:hidden; padding:5px; color:rgb(51,51,51); line-height:15.6000003814697px; border-top-width:1px; border-bottom-width:1px; border-style:solid none; border-top-color:rgb(170,204,153); border-bottom-color:rgb(170,204,153); background-color:rgb(238,255,204)">sibling_soup.b.next_sibling# <c>text2</c>sibling_soup.c.previous_sibling# <b>text1</b></pre><div class="contentsignin">ログイン後にコピー</div></div><p><strong><span style="font-size:18px"> 介绍到这里基本就可以实现我们的BeautifulSoup库爬取网页内容,而网页修改、删除等内容建议大家阅读文档。下一篇文章就再次爬取维基百科的程序语言的内容吧!希望文章对大家有所帮助,如果有错误或不足之处,还请海涵!建议大家阅读官方文档和《Python基础教程》书。</span><br><span style="font-size:18px; color:rgb(51,51,51); font-family:Arial; line-height:26px"> </span><span style="font-size:18px; font-family:Arial; line-height:26px"><span style="color:#ff0000"> (By:Eastmount 2015-3-25 下午6点</span></span><span style="font-size:18px; color:rgb(51,51,51); font-family:Arial; line-height:26px">
</span>//m.sbmmt.com/<span style="font-family:Arial; color:#ff0000"><span style="font-size:18px; line-height:26px">)</span></span></strong><br></p>
<p></p>
<p><br></p>
<p class="pmark"><br></p>
<p>
</p></span></p><p>以上がPython BeautifulSoupライブラリのインストールと紹介の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。</p> </div>
</div>
<div style="height: 25px;">
<div class="wzconBq" style="display: inline-flex;">
<span>関連ラベル:</span>
<div class="wzcbqd">
<a onclick="hits_log(2,'www',this);" href-data="//m.sbmmt.com/ja/search?word=beautifulsoup" target="_blank">beautifulsoup</a> <a onclick="hits_log(2,'www',this);" href-data="//m.sbmmt.com/ja/search?word=python" target="_blank">python</a> <a onclick="hits_log(2,'www',this);" href-data="//m.sbmmt.com/ja/search?word=知識" target="_blank">知識</a> </div>
</div>
<div style="display: inline-flex;float: right; color:#333333;">ソース:php.cn</div>
</div>
<div class="wzconOtherwz">
<a href="//m.sbmmt.com/ja/faq/355982.html" title="Pythonのメソッド、プロパティ、イテレータの詳細な説明">
<span>前の記事:Pythonのメソッド、プロパティ、イテレータの詳細な説明</span>
</a>
<a href="//m.sbmmt.com/ja/faq/356004.html" title="Pythonでの関数map()とreduce()の使用法">
<span>次の記事:Pythonでの関数map()とreduce()の使用法</span>
</a>
</div>
<div class="wzconShengming">
<div class="bzsmdiv">このウェブサイトの声明</div>
<div>この記事の内容はネチズンが自主的に寄稿したものであり、著作権は原著者に帰属します。このサイトは、それに相当する法的責任を負いません。盗作または侵害の疑いのあるコンテンツを見つけた場合は、admin@php.cn までご連絡ください。</div>
</div>
<ins class="adsbygoogle"
style="display:block"
data-ad-format="autorelaxed"
data-ad-client="ca-pub-5902227090019525"
data-ad-slot="2507867629"></ins>
<script>
(adsbygoogle = window.adsbygoogle || []).push({});
</script>
<div class="wzconZzwz">
<div class="wzconZzwztitle">著者別の最新記事</div>
<ul>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="//m.sbmmt.com/ja/faq/354750.html">HTMLで太字、斜体、下線、取り消し線などのフォント効果を設定する例の紹介</a>
</div>
<div>1970-01-01 08:00:00</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="//m.sbmmt.com/ja/faq/338018.html">Java バージョンの Redis を実装する</a>
</div>
<div>1970-01-01 08:00:00</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="//m.sbmmt.com/ja/faq/353509.html">最も単純な WeChat アプレットのデモ</a>
</div>
<div>1970-01-01 08:00:00</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="//m.sbmmt.com/ja/faq/356272.html">Pythonでのpandas.DataFrameの簡単な操作方法(作成、インデックス、追加、削除)の紹介</a>
</div>
<div>1970-01-01 08:00:00</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="//m.sbmmt.com/ja/faq/354839.html">WeChat ミニ プログラム: タブ効果の実装方法の例</a>
</div>
<div>1970-01-01 08:00:00</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="//m.sbmmt.com/ja/faq/354423.html">Python は辞書構造の出力を美しくするためのカスタム メソッドを構築します</a>
</div>
<div>1970-01-01 08:00:00</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="//m.sbmmt.com/ja/faq/350853.html">HTML5: Canvas を使用してビデオをリアルタイムで処理する</a>
</div>
<div>1970-01-01 08:00:00</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="//m.sbmmt.com/ja/faq/346502.html">Asp.net は SignalR を使用して画像を送信します</a>
</div>
<div>1970-01-01 08:00:00</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="//m.sbmmt.com/ja/faq/354842.html">WeChat ミニ プログラム開発チュートリアル - App() および Page() 関数の概要</a>
</div>
<div>1970-01-01 08:00:00</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="//m.sbmmt.com/ja/faq/356574.html">Python Redisの使い方を詳しく解説</a>
</div>
<div>1970-01-01 08:00:00</div>
</li>
</ul>
</div>
<div class="wzconZzwz">
<div class="wzconZzwztitle">最新の問題</div>
<div class="wdsyContent">
<div class="wdsyConDiv flexRow wdsyConDiv1">
<div class="wdcdContent flexColumn">
<a href="//m.sbmmt.com/ja/wenda/175783.html" target="_blank" title="BeautifulSoupを使用して特定のGoogle天気テキストをスクレイピングする方法は?" class="wdcdcTitle">BeautifulSoupを使用して特定のGoogle天気テキストをスクレイピングする方法は?</a>
<a href="//m.sbmmt.com/ja/wenda/175783.html" class="wdcdcCons">BeautifulSoupを使用してPythonでコーステキスト「米国ニューヨーク市」を見つけるにはどうすればよいですか?練習のためにビデオをコピーしようとしましたが、うまくいきま...</a>
<div class="wdcdcInfo flexRow">
<div class="wdcdcileft">
<span class="wdcdciSpan"> から 2024-04-01 14:06:14</span>
</div>
<div class="wdcdciright flexRow">
<div class="wdcdcirdz flexRow ira"> <b class="wdcdcirdzi"></b>0 </div>
<div class="wdcdcirpl flexRow ira"><b class="wdcdcirpli"></b>1</div>
<div class="wdcdcirwatch flexRow ira"><b class="wdcdcirwatchi"></b>308</div>
</div>
</div>
</div>
</div>
<div class="wdsyConLine wdsyConLine2"></div>
</div>
</div>
<div class="wzconZt" >
<div class="wzczt-title">
<div>関連トピック</div>
<a href="//m.sbmmt.com/ja/faq/zt" target="_blank">詳細>
</a>
</div>
<div class="wzcttlist">
<ul>
<li class="ul-li">
<a target="_blank" href="//m.sbmmt.com/ja/faq/pythonkfgj"><img src="https://img.php.cn/upload/subject/202407/22/2024072214424826783.jpg?x-oss-process=image/resize,m_fill,h_145,w_220" alt="Python開発ツール" /> </a>
<a target="_blank" href="//m.sbmmt.com/ja/faq/pythonkfgj" class="title-a-spanl" title="Python開発ツール"><span>Python開発ツール</span> </a>
</li>
<li class="ul-li">
<a target="_blank" href="//m.sbmmt.com/ja/faq/pythondb"><img src="https://img.php.cn/upload/subject/202407/22/2024072214312147925.jpg?x-oss-process=image/resize,m_fill,h_145,w_220" alt="実行可能ファイルにパッケージ化されたPython" /> </a>
<a target="_blank" href="//m.sbmmt.com/ja/faq/pythondb" class="title-a-spanl" title="実行可能ファイルにパッケージ化されたPython"><span>実行可能ファイルにパッケージ化されたPython</span> </a>
</li>
<li class="ul-li">
<a target="_blank" href="//m.sbmmt.com/ja/faq/pythonnzsm"><img src="https://img.php.cn/upload/subject/202407/22/2024072214301218201.jpg?x-oss-process=image/resize,m_fill,h_145,w_220" alt="Pythonで何ができるのか" /> </a>
<a target="_blank" href="//m.sbmmt.com/ja/faq/pythonnzsm" class="title-a-spanl" title="Pythonで何ができるのか"><span>Pythonで何ができるのか</span> </a>
</li>
<li class="ul-li">
<a target="_blank" href="//m.sbmmt.com/ja/faq/formatzpython"><img src="https://img.php.cn/upload/subject/202407/22/2024072214275096159.jpg?x-oss-process=image/resize,m_fill,h_145,w_220" alt="Pythonでフォーマットを使用する方法" /> </a>
<a target="_blank" href="//m.sbmmt.com/ja/faq/formatzpython" class="title-a-spanl" title="Pythonでフォーマットを使用する方法"><span>Pythonでフォーマットを使用する方法</span> </a>
</li>
<li class="ul-li">
<a target="_blank" href="//m.sbmmt.com/ja/faq/pythonjc"><img src="https://img.php.cn/upload/subject/202407/22/2024072214254329480.jpg?x-oss-process=image/resize,m_fill,h_145,w_220" alt="Pythonのチュートリアル" /> </a>
<a target="_blank" href="//m.sbmmt.com/ja/faq/pythonjc" class="title-a-spanl" title="Pythonのチュートリアル"><span>Pythonのチュートリアル</span> </a>
</li>
<li class="ul-li">
<a target="_blank" href="//m.sbmmt.com/ja/faq/pythonhjblbz"><img src="https://img.php.cn/upload/subject/202407/22/2024072214252616529.jpg?x-oss-process=image/resize,m_fill,h_145,w_220" alt="Python環境変数の設定" /> </a>
<a target="_blank" href="//m.sbmmt.com/ja/faq/pythonhjblbz" class="title-a-spanl" title="Python環境変数の設定"><span>Python環境変数の設定</span> </a>
</li>
<li class="ul-li">
<a target="_blank" href="//m.sbmmt.com/ja/faq/pythoneval"><img src="https://img.php.cn/upload/subject/202407/22/2024072214251549631.jpg?x-oss-process=image/resize,m_fill,h_145,w_220" alt="python eval" /> </a>
<a target="_blank" href="//m.sbmmt.com/ja/faq/pythoneval" class="title-a-spanl" title="python eval"><span>python eval</span> </a>
</li>
<li class="ul-li">
<a target="_blank" href="//m.sbmmt.com/ja/faq/scratchpyt"><img src="https://img.php.cn/upload/subject/202407/22/2024072214235344903.jpg?x-oss-process=image/resize,m_fill,h_145,w_220" alt="スクラッチとパイソンの違い" /> </a>
<a target="_blank" href="//m.sbmmt.com/ja/faq/scratchpyt" class="title-a-spanl" title="スクラッチとパイソンの違い"><span>スクラッチとパイソンの違い</span> </a>
</li>
</ul>
</div>
</div>
</div>
</div>
<div class="phpwzright">
<ins class="adsbygoogle"
style="display:block"
data-ad-client="ca-pub-5902227090019525"
data-ad-slot="3653428331"
data-ad-format="auto"
data-full-width-responsive="true"></ins>
<script>
(adsbygoogle = window.adsbygoogle || []).push({});
</script>
<div class="wzrOne">
<div class="wzroTitle">人気のおすすめ</div>
<div class="wzroList">
<ul>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots wzrolr"></span>
<a style="height: auto;" title="Pythonのevalとはどういう意味ですか?" href="//m.sbmmt.com/ja/faq/419793.html">Pythonのevalとはどういう意味ですか?</a>
</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots wzrolr"></span>
<a style="height: auto;" title="Pythonでtxtファイルの内容を読み取る方法" href="//m.sbmmt.com/ja/faq/479676.html">Pythonでtxtファイルの内容を読み取る方法</a>
</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots wzrolr"></span>
<a style="height: auto;" title="pyファイル?" href="//m.sbmmt.com/ja/faq/418747.html">pyファイル?</a>
</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots wzrolr"></span>
<a style="height: auto;" title="Python で str は何を意味しますか" href="//m.sbmmt.com/ja/faq/419809.html">Python で str は何を意味しますか</a>
</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots wzrolr"></span>
<a style="height: auto;" title="Pythonでフォーマットを使用する方法" href="//m.sbmmt.com/ja/faq/471817.html">Pythonでフォーマットを使用する方法</a>
</div>
</li>
</ul>
</div>
</div>
<script src="https://sw.php.cn/hezuo/cac1399ab368127f9b113b14eb3316d0.js" type="text/javascript"></script>
<div class="wzrThree">
<div class="wzrthree-title">
<div>人気のチュートリアル</div>
<a target="_blank" href="//m.sbmmt.com/ja/course.html">詳細>
</a>
</div>
<div class="wzrthreelist swiper2">
<div class="wzrthreeTab swiper-wrapper">
<div class="check tabdiv swiper-slide" data-id="one">関連するチュートリアル <div></div></div>
<div class="tabdiv swiper-slide" data-id="two">人気のおすすめ<div></div></div>
<div class="tabdiv swiper-slide" data-id="three">最新のコース<div></div></div>
</div>
<ul class="one">
<li>
<a target="_blank" href="//m.sbmmt.com/ja/course/812.html" title="最新の ThinkPHP 5.1 ワールドプレミアビデオチュートリアル (PHP エキスパートになるための 60 日間のオンライン トレーニング コース)" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/041/620debc3eab3f377.jpg" alt="最新の ThinkPHP 5.1 ワールドプレミアビデオチュートリアル (PHP エキスパートになるための 60 日間のオンライン トレーニング コース)"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="最新の ThinkPHP 5.1 ワールドプレミアビデオチュートリアル (PHP エキスパートになるための 60 日間のオンライン トレーニング コース)" href="//m.sbmmt.com/ja/course/812.html">最新の ThinkPHP 5.1 ワールドプレミアビデオチュートリアル (PHP エキスパートになるための 60 日間のオンライン トレーニング コース)</a>
<div class="wzrthreerb">
<div>1422719 <b class="kclbcollectb"></b></div>
<div class="courseICollection" data-id="812">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="//m.sbmmt.com/ja/course/74.html" title="PHP 入門チュートリアル 1: 1 週間で PHP を学ぶ" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/068/6253d1e28ef5c345.png" alt="PHP 入門チュートリアル 1: 1 週間で PHP を学ぶ"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="PHP 入門チュートリアル 1: 1 週間で PHP を学ぶ" href="//m.sbmmt.com/ja/course/74.html">PHP 入門チュートリアル 1: 1 週間で PHP を学ぶ</a>
<div class="wzrthreerb">
<div>4267688 <b class="kclbcollectb"></b></div>
<div class="courseICollection" data-id="74">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="//m.sbmmt.com/ja/course/286.html" title="JAVA 初心者向けビデオチュートリアル" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/068/62590a2bacfd9379.png" alt="JAVA 初心者向けビデオチュートリアル"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="JAVA 初心者向けビデオチュートリアル" href="//m.sbmmt.com/ja/course/286.html">JAVA 初心者向けビデオチュートリアル</a>
<div class="wzrthreerb">
<div>2531408 <b class="kclbcollectb"></b></div>
<div class="courseICollection" data-id="286">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="//m.sbmmt.com/ja/course/504.html" title="Little Turtle のゼロベースの Python 学習入門ビデオ チュートリアル" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/068/62590a67ce3a6655.png" alt="Little Turtle のゼロベースの Python 学習入門ビデオ チュートリアル"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="Little Turtle のゼロベースの Python 学習入門ビデオ チュートリアル" href="//m.sbmmt.com/ja/course/504.html">Little Turtle のゼロベースの Python 学習入門ビデオ チュートリアル</a>
<div class="wzrthreerb">
<div>507117 <b class="kclbcollectb"></b></div>
<div class="courseICollection" data-id="504">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="//m.sbmmt.com/ja/course/2.html" title="PHP ゼロベースの入門チュートリアル" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/068/6253de27bc161468.png" alt="PHP ゼロベースの入門チュートリアル"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="PHP ゼロベースの入門チュートリアル" href="//m.sbmmt.com/ja/course/2.html">PHP ゼロベースの入門チュートリアル</a>
<div class="wzrthreerb">
<div>862213 <b class="kclbcollectb"></b></div>
<div class="courseICollection" data-id="2">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
</ul>
<ul class="two" style="display: none;">
<li>
<a target="_blank" href="//m.sbmmt.com/ja/course/812.html" title="最新の ThinkPHP 5.1 ワールドプレミアビデオチュートリアル (PHP エキスパートになるための 60 日間のオンライン トレーニング コース)" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/041/620debc3eab3f377.jpg" alt="最新の ThinkPHP 5.1 ワールドプレミアビデオチュートリアル (PHP エキスパートになるための 60 日間のオンライン トレーニング コース)"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="最新の ThinkPHP 5.1 ワールドプレミアビデオチュートリアル (PHP エキスパートになるための 60 日間のオンライン トレーニング コース)" href="//m.sbmmt.com/ja/course/812.html">最新の ThinkPHP 5.1 ワールドプレミアビデオチュートリアル (PHP エキスパートになるための 60 日間のオンライン トレーニング コース)</a>
<div class="wzrthreerb">
<div >1422719 回の学習</div>
<div class="courseICollection" data-id="812">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="//m.sbmmt.com/ja/course/286.html" title="JAVA 初心者向けビデオチュートリアル" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/068/62590a2bacfd9379.png" alt="JAVA 初心者向けビデオチュートリアル"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="JAVA 初心者向けビデオチュートリアル" href="//m.sbmmt.com/ja/course/286.html">JAVA 初心者向けビデオチュートリアル</a>
<div class="wzrthreerb">
<div >2531408 回の学習</div>
<div class="courseICollection" data-id="286">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="//m.sbmmt.com/ja/course/504.html" title="Little Turtle のゼロベースの Python 学習入門ビデオ チュートリアル" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/068/62590a67ce3a6655.png" alt="Little Turtle のゼロベースの Python 学習入門ビデオ チュートリアル"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="Little Turtle のゼロベースの Python 学習入門ビデオ チュートリアル" href="//m.sbmmt.com/ja/course/504.html">Little Turtle のゼロベースの Python 学習入門ビデオ チュートリアル</a>
<div class="wzrthreerb">
<div >507117 回の学習</div>
<div class="courseICollection" data-id="504">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="//m.sbmmt.com/ja/course/901.html" title="Web フロントエンド開発の簡単な紹介" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/067/64be28a53a4f6310.png" alt="Web フロントエンド開発の簡単な紹介"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="Web フロントエンド開発の簡単な紹介" href="//m.sbmmt.com/ja/course/901.html">Web フロントエンド開発の簡単な紹介</a>
<div class="wzrthreerb">
<div >215766 回の学習</div>
<div class="courseICollection" data-id="901">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="//m.sbmmt.com/ja/course/234.html" title="PSビデオチュートリアルをゼロからマスターする" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/068/62611f57ed0d4840.jpg" alt="PSビデオチュートリアルをゼロからマスターする"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="PSビデオチュートリアルをゼロからマスターする" href="//m.sbmmt.com/ja/course/234.html">PSビデオチュートリアルをゼロからマスターする</a>
<div class="wzrthreerb">
<div >889202 回の学習</div>
<div class="courseICollection" data-id="234">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
</ul>
<ul class="three" style="display: none;">
<li>
<a target="_blank" href="//m.sbmmt.com/ja/course/1648.html" title="[Web フロントエンド] Node.js クイック スタート" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png" alt="[Web フロントエンド] Node.js クイック スタート"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="[Web フロントエンド] Node.js クイック スタート" href="//m.sbmmt.com/ja/course/1648.html">[Web フロントエンド] Node.js クイック スタート</a>
<div class="wzrthreerb">
<div >7402 回の学習</div>
<div class="courseICollection" data-id="1648">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="//m.sbmmt.com/ja/course/1647.html" title="海外のWeb開発フルスタックコースの完全なコレクション" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/067/6628cc96e310c937.png" alt="海外のWeb開発フルスタックコースの完全なコレクション"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="海外のWeb開発フルスタックコースの完全なコレクション" href="//m.sbmmt.com/ja/course/1647.html">海外のWeb開発フルスタックコースの完全なコレクション</a>
<div class="wzrthreerb">
<div >5788 回の学習</div>
<div class="courseICollection" data-id="1647">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="//m.sbmmt.com/ja/course/1646.html" title="Go言語実践GraphQL" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/067/662221173504a436.png" alt="Go言語実践GraphQL"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="Go言語実践GraphQL" href="//m.sbmmt.com/ja/course/1646.html">Go言語実践GraphQL</a>
<div class="wzrthreerb">
<div >4888 回の学習</div>
<div class="courseICollection" data-id="1646">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="//m.sbmmt.com/ja/course/1645.html" title="550W ファンマスターが JavaScript をゼロから段階的に学習します" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/067/662077e163124646.png" alt="550W ファンマスターが JavaScript をゼロから段階的に学習します"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="550W ファンマスターが JavaScript をゼロから段階的に学習します" href="//m.sbmmt.com/ja/course/1645.html">550W ファンマスターが JavaScript をゼロから段階的に学習します</a>
<div class="wzrthreerb">
<div >690 回の学習</div>
<div class="courseICollection" data-id="1645">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="//m.sbmmt.com/ja/course/1644.html" title="Python マスター Mosh、基礎知識ゼロの初心者でも 6 時間で始められる" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/067/6616418ca80b8916.png" alt="Python マスター Mosh、基礎知識ゼロの初心者でも 6 時間で始められる"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="Python マスター Mosh、基礎知識ゼロの初心者でも 6 時間で始められる" href="//m.sbmmt.com/ja/course/1644.html">Python マスター Mosh、基礎知識ゼロの初心者でも 6 時間で始められる</a>
<div class="wzrthreerb">
<div >24506 回の学習</div>
<div class="courseICollection" data-id="1644">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
</ul>
</div>
<script>
var mySwiper = new Swiper('.swiper2', {
autoplay: false,//可选选项,自动滑动
slidesPerView : 'auto',
})
$('.wzrthreeTab>div').click(function(e){
$('.wzrthreeTab>div').removeClass('check')
$(this).addClass('check')
$('.wzrthreelist>ul').css('display','none')
$('.'+e.currentTarget.dataset.id).show()
})
</script>
</div>
<div class="wzrFour">
<div class="wzrfour-title">
<div>最新のダウンロード</div>
<a href="//m.sbmmt.com/ja/xiazai">詳細>
</a>
</div>
<script>
$(document).ready(function(){
var sjyx_banSwiper = new Swiper(".sjyx_banSwiperwz",{
speed:1000,
autoplay:{
delay:3500,
disableOnInteraction: false,
},
pagination:{
el:'.sjyx_banSwiperwz .swiper-pagination',
clickable :false,
},
loop:true
})
})
</script>
<div class="wzrfourList swiper3">
<div class="wzrfourlTab swiper-wrapper">
<div class="check swiper-slide" data-id="onef">ウェブエフェクト <div></div></div>
<div class="swiper-slide" data-id="twof">公式サイト<div></div></div>
<div class="swiper-slide" data-id="threef">サイト素材<div></div></div>
<div class="swiper-slide" data-id="fourf">フロントエンドテンプレート<div></div></div>
</div>
<ul class="onef">
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a target="_blank" title="jQuery エンタープライズ メッセージ フォームの連絡先コード" href="//m.sbmmt.com/ja/toolset/js-special-effects/8071">[フォームボタン] jQuery エンタープライズ メッセージ フォームの連絡先コード</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a target="_blank" title="HTML5 MP3 オルゴール再生効果" href="//m.sbmmt.com/ja/toolset/js-special-effects/8070">[プレイヤーの特殊効果] HTML5 MP3 オルゴール再生効果</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a target="_blank" title="HTML5 クールなパーティクル アニメーション ナビゲーション メニューの特殊効果" href="//m.sbmmt.com/ja/toolset/js-special-effects/8069">[メニューナビゲーション] HTML5 クールなパーティクル アニメーション ナビゲーション メニューの特殊効果</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a target="_blank" title="jQuery ビジュアル フォームのドラッグ アンド ドロップ編集コード" href="//m.sbmmt.com/ja/toolset/js-special-effects/8068">[フォームボタン] jQuery ビジュアル フォームのドラッグ アンド ドロップ編集コード</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a target="_blank" title="VUE.JS 模倣 Kugou 音楽プレーヤー コード" href="//m.sbmmt.com/ja/toolset/js-special-effects/8067">[プレイヤーの特殊効果] VUE.JS 模倣 Kugou 音楽プレーヤー コード</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a target="_blank" title="古典的な HTML5 プッシュ ボックス ゲーム" href="//m.sbmmt.com/ja/toolset/js-special-effects/8066">[html5特殊効果] 古典的な HTML5 プッシュ ボックス ゲーム</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a target="_blank" title="画像効果を追加または削減するための jQuery スクロール" href="//m.sbmmt.com/ja/toolset/js-special-effects/8065">[画像の特殊効果] 画像効果を追加または削減するための jQuery スクロール</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a target="_blank" title="CSS3 個人アルバム カバー ホバー ズーム効果" href="//m.sbmmt.com/ja/toolset/js-special-effects/8064">[フォトアルバム効果] CSS3 個人アルバム カバー ホバー ズーム効果</a>
</div>
</li>
</ul>
<ul class="twof" style="display:none">
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/ja/toolset/website-source-code/8328" title="室内装飾クリーニングおよび修理サービス会社のウェブサイトのテンプレート" target="_blank">[フロントエンドテンプレート] 室内装飾クリーニングおよび修理サービス会社のウェブサイトのテンプレート</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/ja/toolset/website-source-code/8327" title="フレッシュカラーの個人履歴書ガイドページテンプレート" target="_blank">[フロントエンドテンプレート] フレッシュカラーの個人履歴書ガイドページテンプレート</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/ja/toolset/website-source-code/8326" title="デザイナーのクリエイティブな仕事の履歴書 Web テンプレート" target="_blank">[フロントエンドテンプレート] デザイナーのクリエイティブな仕事の履歴書 Web テンプレート</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/ja/toolset/website-source-code/8325" title="現代のエンジニアリング建設会社のウェブサイトのテンプレート" target="_blank">[フロントエンドテンプレート] 現代のエンジニアリング建設会社のウェブサイトのテンプレート</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/ja/toolset/website-source-code/8324" title="教育サービス機関向けのレスポンシブ HTML5 テンプレート" target="_blank">[フロントエンドテンプレート] 教育サービス機関向けのレスポンシブ HTML5 テンプレート</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/ja/toolset/website-source-code/8323" title="オンライン電子書籍ストア モールのウェブサイト テンプレート" target="_blank">[フロントエンドテンプレート] オンライン電子書籍ストア モールのウェブサイト テンプレート</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/ja/toolset/website-source-code/8322" title="IT テクノロジーがインターネット企業の Web サイト テンプレートを解決します" target="_blank">[フロントエンドテンプレート] IT テクノロジーがインターネット企業の Web サイト テンプレートを解決します</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/ja/toolset/website-source-code/8321" title="パープルスタイル外国為替取引サービスウェブサイトテンプレート" target="_blank">[フロントエンドテンプレート] パープルスタイル外国為替取引サービスウェブサイトテンプレート</a>
</div>
</li>
</ul>
<ul class="threef" style="display:none">
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/ja/toolset/website-materials/3078" target="_blank" title="かわいい夏の要素のベクター素材 (EPS+PNG)">[PNG素材] かわいい夏の要素のベクター素材 (EPS+PNG)</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/ja/toolset/website-materials/3077" target="_blank" title="4 つの赤い 2023 卒業バッジ ベクター素材 (AI+EPS+PNG)">[PNG素材] 4 つの赤い 2023 卒業バッジ ベクター素材 (AI+EPS+PNG)</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/ja/toolset/website-materials/3076" target="_blank" title="歌う鳥と花がいっぱいのカートデザイン春のバナーベクター素材(AI+EPS)">[バナー画像] 歌う鳥と花がいっぱいのカートデザイン春のバナーベクター素材(AI+EPS)</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/ja/toolset/website-materials/3075" target="_blank" title="金色の卒業帽ベクター素材(EPS+PNG)">[PNG素材] 金色の卒業帽ベクター素材(EPS+PNG)</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/ja/toolset/website-materials/3074" target="_blank" title="黒と白のスタイルの山アイコン ベクター素材 (EPS+PNG)">[PNG素材] 黒と白のスタイルの山アイコン ベクター素材 (EPS+PNG)</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/ja/toolset/website-materials/3073" target="_blank" title="異なる色のマントと異なるポーズを持つスーパーヒーローのシルエットベクター素材(EPS+PNG)">[PNG素材] 異なる色のマントと異なるポーズを持つスーパーヒーローのシルエットベクター素材(EPS+PNG)</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/ja/toolset/website-materials/3072" target="_blank" title="フラット スタイルの植樹祭バナー ベクター素材 (AI+EPS)">[バナー画像] フラット スタイルの植樹祭バナー ベクター素材 (AI+EPS)</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/ja/toolset/website-materials/3071" target="_blank" title="9つのコミックスタイルの爆発するチャットバブルベクター素材(EPS+PNG)">[PNG素材] 9つのコミックスタイルの爆発するチャットバブルベクター素材(EPS+PNG)</a>
</div>
</li>
</ul>
<ul class="fourf" style="display:none">
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/ja/toolset/website-source-code/8328" target="_blank" title="室内装飾クリーニングおよび修理サービス会社のウェブサイトのテンプレート">[フロントエンドテンプレート] 室内装飾クリーニングおよび修理サービス会社のウェブサイトのテンプレート</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/ja/toolset/website-source-code/8327" target="_blank" title="フレッシュカラーの個人履歴書ガイドページテンプレート">[フロントエンドテンプレート] フレッシュカラーの個人履歴書ガイドページテンプレート</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/ja/toolset/website-source-code/8326" target="_blank" title="デザイナーのクリエイティブな仕事の履歴書 Web テンプレート">[フロントエンドテンプレート] デザイナーのクリエイティブな仕事の履歴書 Web テンプレート</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/ja/toolset/website-source-code/8325" target="_blank" title="現代のエンジニアリング建設会社のウェブサイトのテンプレート">[フロントエンドテンプレート] 現代のエンジニアリング建設会社のウェブサイトのテンプレート</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/ja/toolset/website-source-code/8324" target="_blank" title="教育サービス機関向けのレスポンシブ HTML5 テンプレート">[フロントエンドテンプレート] 教育サービス機関向けのレスポンシブ HTML5 テンプレート</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/ja/toolset/website-source-code/8323" target="_blank" title="オンライン電子書籍ストア モールのウェブサイト テンプレート">[フロントエンドテンプレート] オンライン電子書籍ストア モールのウェブサイト テンプレート</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/ja/toolset/website-source-code/8322" target="_blank" title="IT テクノロジーがインターネット企業の Web サイト テンプレートを解決します">[フロントエンドテンプレート] IT テクノロジーがインターネット企業の Web サイト テンプレートを解決します</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/ja/toolset/website-source-code/8321" target="_blank" title="パープルスタイル外国為替取引サービスウェブサイトテンプレート">[フロントエンドテンプレート] パープルスタイル外国為替取引サービスウェブサイトテンプレート</a>
</div>
</li>
</ul>
</div>
<script>
var mySwiper = new Swiper('.swiper3', {
autoplay: false,//可选选项,自动滑动
slidesPerView : 'auto',
})
$('.wzrfourlTab>div').click(function(e){
$('.wzrfourlTab>div').removeClass('check')
$(this).addClass('check')
$('.wzrfourList>ul').css('display','none')
$('.'+e.currentTarget.dataset.id).show()
})
</script>
</div>
</div>
</div>
<footer>
<div class="footer">
<div class="footertop">
<img src="/static/imghw/logo.png" alt="">
<p>福祉オンライン PHP トレーニング,PHP 学習者の迅速な成長を支援します!</p>
</div>
<div class="footermid">
<a href="//m.sbmmt.com/ja/about/us.html">私たちについて</a>
<a href="//m.sbmmt.com/ja/about/disclaimer.html">免責事項</a>
<a href="//m.sbmmt.com/ja/update/article_0_1.html">Sitemap</a>
</div>
<div class="footerbottom">
<p>
© php.cn All rights reserved
</p>
</div>
</div>
</footer>
<input type="hidden" id="verifycode" value="/captcha.html">
<script>layui.use(['element', 'carousel'], function () {var element = layui.element;$ = layui.jquery;var carousel = layui.carousel;carousel.render({elem: '#test1', width: '100%', height: '330px', arrow: 'always'});$.getScript('/static/js/jquery.lazyload.min.js', function () {$("img").lazyload({placeholder: "/static/images/load.jpg", effect: "fadeIn", threshold: 200, skip_invisible: false});});});</script>
<script src="/static/js/common_new.js"></script>
<script type="text/javascript" src="/static/js/jquery.cookie.js?1734092802"></script>
<script src="https://vdse.bdstatic.com//search-video.v1.min.js"></script>
<link rel='stylesheet' id='_main-css' href='/static/css/viewer.min.css?2' type='text/css' media='all'/>
<script type='text/javascript' src='/static/js/viewer.min.js?1'></script>
<script type='text/javascript' src='/static/js/jquery-viewer.min.js'></script>
<script type="text/javascript" src="/static/js/global.min.js?5.5.53"></script>
</body>
</html>



