


インターネットの発展に伴い、あらゆる面でデータがますます増えており、これは過去 2 年間でビッグデータへの要求が高まっていることからもわかります。
私たちが取り組んでいるプロジェクトは大規模なものではありませんが、業務量が多いため、かなりの量のデータがあります。
データが多すぎるとパフォーマンスの問題が発生しやすくなり、この問題を解決するために通常はクラスタリングやシャーディングなどが簡単に考えられます。
しかし、ある時点でクラスタリングやシャーディングを使用する必要がなくなり、データのパーティショニングも適切に使用できるようになります。
パーティションとは何ですか?
MySQL がパーティショニング機能を有効にしていない場合、データベース内の単一のテーブルの内容は単一のファイルの形式でファイル システムに保存されます。パーティショニング機能が有効になっている場合、MySQL は 1 つのテーブルの内容を複数のファイルに分割し、ユーザーが指定したルールに従ってファイル システムに保存します。パーティショニングには、水平パーティショニングと垂直パーティショニングに分けられます。水平パーティショニングはテーブル データを行ごとに異なるデータ ファイルに分割し、垂直パーティショニングはテーブル データを列ごとに異なるデータ ファイルに分割します。シャーディングは、完全性、再構成可能性、および分離性の原則に従う必要があります。完全性とは、すべてのデータがフラグメントにマップされる必要があることを意味します。再構成可能性とは、すべてのシャード データをグローバル データに再構築できる必要があることを意味します。非結合性とは、(意図的に冗長化しない限り) 異なるシャード上にデータの重複がないことを意味します。
おそらく様々な配慮から、使用したテーブルはレンジパーティショニングを使用していますが、データベースは他人によって管理されていますが、このテーブルを使用するため、簡単な調査を行うことにしました。
私の知る限り、パーティショニングを使用したい場合は、テーブル構造を作成するときにステートメントを使用してパーティションを作成する必要があり、後で変更することはできません。
たとえば、id、name、age の 3 つのフィールドを持つ単純な emp テーブルを作成し、id に基づいてパーティション化します。正しいテーブル作成ステートメントは基本的に次のとおりです。
CREATE TABLE emp( id INT NOT NULL, NAME VARCHAR(20), age INT) PARTITION BY RANGE(ID)( PARTITION p0 VALUES LESS THAN (6), PARTITION p1 VALUES LESS THAN (11), PARTITION pmax VALUES LESS THAN maxvalue );
ここでは、テーブル全体のデータを 3 つの領域に分割するように設定しています。id が 6 未満のものを 1 つの領域とし、id が 6 未満のものを領域名とします。 6 と 11 は 1 つのエリア (エリア名 p1) に属し、次に 11 より大きい ID を持つすべてのエリア (エリア名 pmax) に属します。
基本的に次のように文法を整理します:
create table tablename( 字段名 数据类型...) partition by range(分区依赖的字段名)( partition 分取名 values less than (分区条件的值),...)
ここで注意する必要があるのは、例の最後の行である、パーティション pmax 値が maxvalue 未満であることです。この文では、パーティション名を表す pmax のみを指定できます。残りのワードは、上記の分割条件の最大値を表します。
これにより、すべてのデータがデータベースに正常に保存されるようになります。そうでない場合は、ID が 11 以上のデータはデータベースに保存されず、エラーが報告されます。
テーブル構造が作成された後、分割が成功したかどうかをテストするために、テーブルにデータを挿入しました。ステートメントは次のとおりです。
INSERT INTO emp VALUES(1,'test1',22);INSERT INTO emp VALUES(2,'test2',25);INSERT INTO emp VALUES(3,'test3',27); INSERT INTO emp VALUES(4,'test4',20);INSERT INTO emp VALUES(5,'test5',22);INSERT INTO emp VALUES(6,'test6',25); INSERT INTO emp VALUES(7,'test7',27);INSERT INTO emp VALUES(8,'test8',20);INSERT INTO emp VALUES(9,'test9',22); INSERT INTO emp VALUES(10,'test10',25);INSERT INTO emp VALUES(11,'test11',27);INSERT INTO emp VALUES(12,'test12',20); INSERT INTO emp VALUES(13,'test13',22);INSERT INTO emp VALUES(14,'test14',25);INSERT INTO emp VALUES(15,'test15',27); INSERT INTO emp VALUES(16,'test16',20);INSERT INTO emp VALUES(17,'test17',30);INSERT INTO emp VALUES(18,'test18',40); INSERT INTO emp VALUES(19,'test19',20);
データの挿入が完了した後、データが次のとおりであるかどうかを確認します。 ID は対応するパーティションに保存され、使用できます。 パーティションをクエリするコマンドは次のとおりです:
SELECT partition_name,partition_expression,partition_description,table_rows FROM information_schema.PARTITIONS WHERE table_schema = SCHEMA() AND table_name='emp'
クエリの結果は図に示すとおりです: 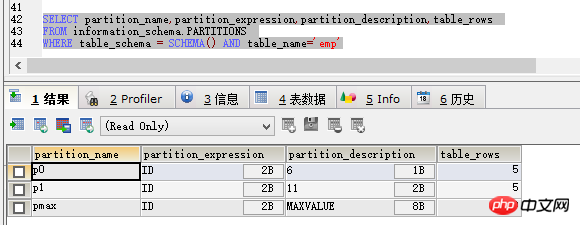
partition_name がパーティション名、partition_expression であることがわかります。はパーティションが依存するフィールド、partition_description はパーティションの状態として理解でき、table_rows はパーティション内の現在の状態を表します。一定量のデータがあります。
上記のデータから分割が成功していることが分かりますが、上記の分割により挿入できない問題は回避できましたが、新たな問題が発生しました。
つまり、最後の pmax 領域のデータが非常に大きくなる可能性があり、その結果、データが不均一で不均衡になり、最後の領域のデータをクエリするときにパフォーマンスの問題が発生する可能性があります。したがって、解決策は大きく分けて3つあります:
まず、パーティションフィールドのデータ、例えばここでのIDを制御でき、それがいつどのような値になるか明確にわかっていれば、pmaxを使用せずに開始できますが、パーティションを定期的に追加します。たとえば、ここに p0 と p1 が存在する場合、id が 11 に達しようとしているときに、p2、p3、またはそれ以上を追加できます。パーティションを追加するステートメントの例は次のとおりです:
ALTER TABLE emp ADD PARTITION(PARTITION p2 VALUES LESS THAN (16))
構文は次のとおりです:
alter table tablename add partition(partition 分区名 values lessthan (分区条件))
上記の方法はデータの不均衡の問題を解決できますが、隠れた危険もあります。後続のパーティション、またはパーティションが依存するフィールド値が予想を超える場合、データをデータベースに保存できないという問題が発生する可能性があります。このように、これを解決するには 2 つの方法があります:
まず、mysql のトランザクション メカニズムとストアド プロシージャを使用して、mysql のスケジュールされたタスクを作成し、データベース システムに特定の時間にパーティションを追加させることができます。このようにすると基本的に最初の方法で挙げたような問題は発生しませんが、この方法はMySQLのトランザクションやストアドプロシージャに対するある程度の理解が必要であり、操作が難しいです。
このメソッドは知っていますが、まだ実装していません。トランザクションとストアド プロシージャについて詳しく学習した後で、関連する例を示します。
上記のスケジュールされたタスクの方法に加えて、パーティションを分割する別の方法があります。つまり、以前に pmax パーティションがあったテーブル構造を引き続き使用し、split Partition ステートメントを使用して pmax を分割します。例は次のとおりです:
ALTER TABLE emp REORGANIZE PARTITION pmax INTO( PARTITION p2 VALUES LESS THAN (16), PARTITION pmax VALUES LESS THAN maxvalue )
然后我们再用查询分区情况的语句查询,便可以看到结果变成这样: 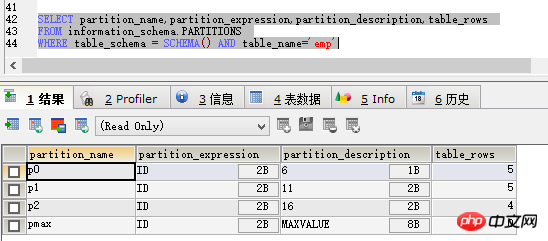
很显然,多出来了一个p2分区,拆分成功的同事不影响其他的功能。
那么这里分区拆分的语法整理如下:
alter table tablename reorganize partition 要拆分的分区名 into( partition 拆分后的分区名1 values less than (条件), partition 拆分后的分区名2 values lessthan (条件),...)
好了,到这里基本上算是完成了,但是我们知道数据库一般的操作都是增删改查,我们这里已经有了增改查,却自然也不能少了删。
按理说正常的生产环境的数据库应该是不能随意删除数据的,但是并不代表就不能删,反而有的时候还必须要删。
就比如我们项目中那个库,由于数据量太大,即便是分区了也依旧会在大量数据的情况下变慢。而与此同时,我们是按时间分区的,实际使用过程中只需要用到几天的数据,那么实际上很早以前的数据是可以删除不要的,或者说备份以后删除这个表的,这样就需要用到删除语句。
当然了,删除可以用delete,但是这样的话分区信息还在库中,实际上也是没必要要的,完全可以直接删除分区,因为删除分区的时候也同时会删除这个区内的所有数据。
示例之前我们先查一下之前插入的所有数据,如图: 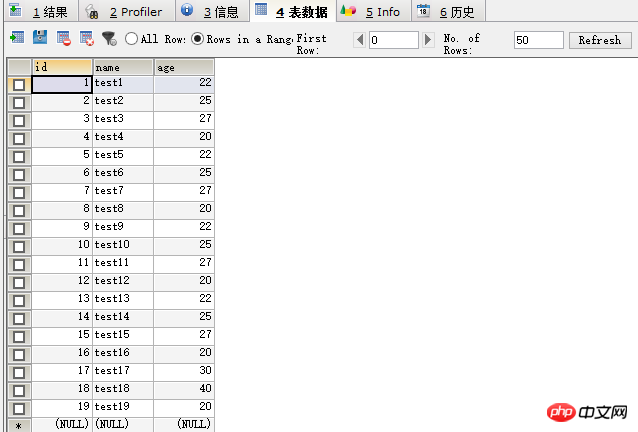
这里示例删除p0分区代码如下:
ALTER TABLE emp DROP PARTITION p0
然后先用查询分区的代码看一下,如图 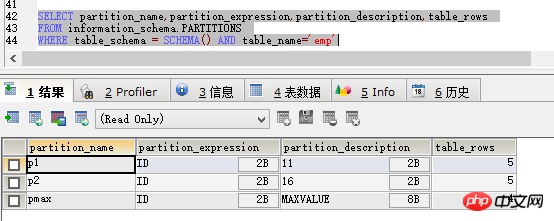
可以看到p0区不见了,在select * 一下,如图: 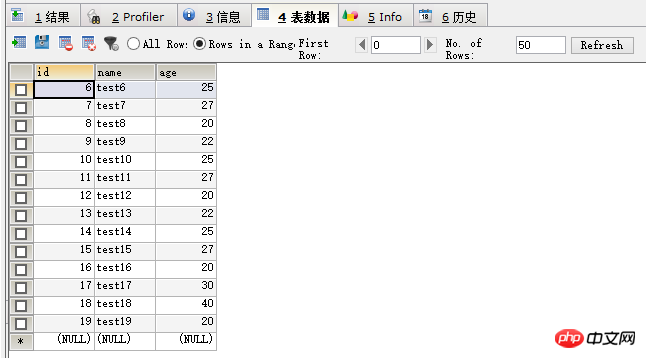
可以看到id小于6的数据已经没有了,数据删除成功。
以上就是mysql分区之range分区的详细介绍的内容,更多相关内容请关注PHP中文网(m.sbmmt.com)!
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



