


1. インデックスの基本
インデックスの種類:
1. 通常のインデックス: 任意のデータ型に作成されます
2. 固有のインデックス: インデックス値を一意になるように制限します
3. フルテキスト インデックス: にのみ作成できますchar、varchar 、テキスト型フィールドでは、主にテキスト クエリの速度を向上させるために使用されます。 MyISAM エンジンのサポート。
4. 単一列インデックス: テーブル内の単一フィールドのインデックスを作成します
5. 複数列インデックス: 複数のフィールドのインデックスを作成します
6. 空間インデックス: システムに次のような効率を提供するために空間パラメータを使用して作成されます制御データの取得
インデックス作成の基本 操作:
CREATE TABLE t_user1(id INT ,
userName VARCHAR(20),
PASSWORD VARCHAR(20),
INDEX (userName)
);
CREATE TABLE t_user2(id INT ,
userName VARCHAR(20),
PASSWORD VARCHAR(20),
UNIQUE INDEX index_userName(userName)
);
CREATE TABLE t_user3(id INT ,
userName VARCHAR(20),
PASSWORD VARCHAR(20),
INDEX index_userName_password(userName,PASSWORD)//多列索引
);
CREATE INDEX index_userName ON t_user4(userName);--对已经创建的表指定索引
CREATE UNIQUE INDEX index_userName ON t_user4(userName);
CREATE INDEX index_userName_password ON t_user4(userName,PASSWORD);
ALTER TABLE t_user5 ADD INDEX index_userName(userName);--修改索引
ALTER TABLE t_user5 ADD UNIQUE INDEX index_userName(userName);
ALTER TABLE t_user5 ADD INDEX index_userName_password(userName,PASSWORD);
DROP INDEX index_userName ON t_user5;
DROP INDEX index_userName_password ON t_user5; インデックスを追加すると、クエリの効率が向上し、テーブル全体のデータ クエリを回避できます。代わりに、インデックスを検索してターゲット データを見つけます。 select t.name from user t where t.id=5、actor_id 列にインデックスが作成されている場合、mysql はそのインデックスを使用して id=5 の行を検索します。つまり、最初にインデックスの値で検索します。を返し、その値のデータ行を含むすべての行を返します。
インデックスに複数の列が含まれる場合、MySQL はインデックスの左端のプレフィックス列のみを効率的に使用できるため、列の順序も非常に重要です。さらに、インデックスの作成と保守にもシステム リソースが必要です。これには、クエリ効率を向上させるために効率的なインデックスを作成する方法が含まれます。
2. MySQL インデックス タイプ
一般に、データ インデックス自体も非常に大きく、すべてをメモリに保存することは不可能であるため、インデックスはインデックス ファイルの形式でディスクに保存されることがよくあります。この場合、メモリ アクセスと比較して、インデックス検索プロセス中にディスク I/O の消費が発生するため、インデックスの構造構成により、検索プロセス中のディスク I/O アクセスの数を最小限に抑える必要があります。これには、データベースのインデックスを整理して保存するための高品質のデータ構造が必要です。
一般的なインデックス タイプはデータ構造アルゴリズムを利用します。たとえば、B ツリーは MySQL のインデックス タイプであり、動的検索ツリーでもあります。Binary Search Tree、Balanced Binary Search Tree、Red Red-Black Tree、バイナリ ツリー構造です。 B ツリー/B+ ツリー/B* ツリー (B~ツリー)。
これらの MySQL インデックス タイプはデータ構造アルゴリズムの実装に基づいているため、一般的な開発は基礎に基づいて適用され始めます。異なるデータ構造に基づいて作成されたインデックスの用途も異なります。 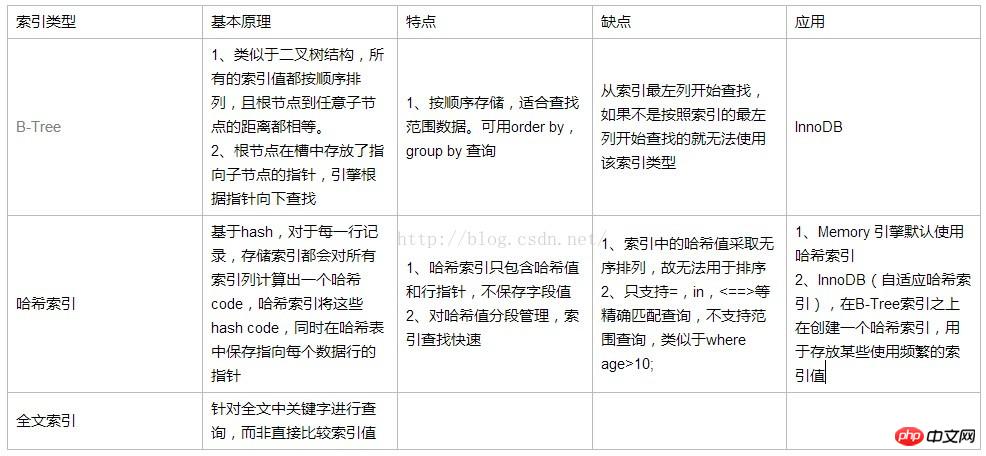
3. インデックスの使用に関するよくある誤解
1. 独立した列インデックス
エラーの使用方法 : この条件では、t.age+1=5 である t.name を選択します。 1=5 の場合、mysql は age カラムにインデックスが作成されても、クエリ時にインデックス クエリを使用せず、テーブル全体をスキャンします。
間違った使い方: select t.name from user t where TO_DAYS(`CURRENT_DATE`())-TO_DAYS(date_col) 正しい原則: 常にインデックスを置く列の比較演算子の片側。
2. 複数列インデックス
よくある間違い: 列を含まない独立したインデックスを作成するか、間違った順序で複数列インデックスを作成するか、単に where 条件内のすべての列にインデックスを作成します。
正しい使い方: さまざまなインデックスタイプに適切なインデックス順序を選択します たとえば、t.staffId=2 およびcustom_id=7 のユーザー t から t.name を選択します
上記のクエリに応答して、次のようにします。 (staffId,custom_id) を作成するか、これら 2 つの列の順序を逆にする必要があります。
4. 概要
以前に取り組んだ Java クラウド プラットフォーム プロジェクトを検討し、ORM フレームワークを使用していましたが、そのときはカスケード クエリが遅かったため、JDBC と ORM を組み合わせたフォーム プログラミングを使用しました。再度インデックスを最適化する必要があります。通常、作成されるインデックスは単一列インデックスのみを使用し、主キーを使用して作成されます。ただし、クエリに時間がかかる問題が発生した場合は、テーブル構造の最適化が必要です。最適化とクエリの最適化は連携して行う必要がありますが、ORM に依存してフレームワークを再選択または再最適化しても問題は解決できません。
上記は、MySQL データベースの最適化 (4) - MySQL インデックスの最適化の内容です。さらに関連する内容については、PHP 中国語 Web サイト (m.sbmmt.com) に注目してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



