


はじめに
•概要
•変数を宣言すると舞台裏で何が起こっているのでしょうか?
•ヒープとスタック
•値型と参照型
•どれが値型でどれが参照型でしょうか?
•ボックス化とボックス化解除
•ボックス化とボックス化解除のパフォーマンスの問題
1. 概要
この記事では、ヒープ、スタック、値型、参照型、ボックス化およびボックス化解除の 6 つの重要な概念について説明します。この記事では、まず、変数を定義するときにシステム内で発生する変更について説明し、次にストレージ デュオ、つまりヒープとスタックに焦点を移します。後で、値の型と参照型を検討し、これら 2 つの型に関する重要な基本について説明します。
この記事では、ボックス化およびボックス化解除のプロセスによって生じるパフォーマンスへの影響を示す簡単なコードを使用します。よく読んでください。

2. 変数を宣言すると舞台裏で何が起こっているのでしょうか?
.NET アプリケーションで変数を定義すると、RAM 内でその変数にメモリ ブロックが割り当てられます。このメモリには、変数の名前、変数のデータ型、変数の値の 3 つの情報が含まれています。
上記はメモリ内で何が起こるかを簡単に説明していますが、変数が正確にどのタイプのメモリに割り当てられるかはデータ型によって異なります。 .NET には、スタックとヒープという 2 種類の割り当て可能なメモリがあります。次のいくつかのセクションでは、これら 2 種類のストレージについて詳しく理解していきます。
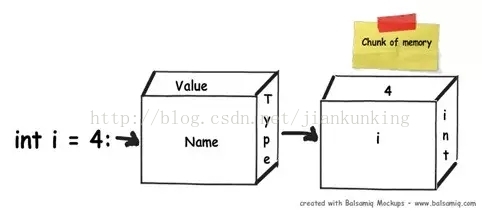
3. ストレージ デュオ: ヒープとスタック
スタックとヒープを理解するために、次のコードを使用して舞台裏で何が起こっているかを理解しましょう。
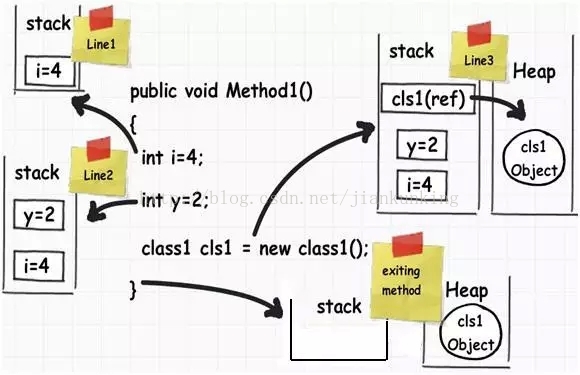
public void Method1()
{
// Line 1
int i=4;
// Line 2
int y=2;
//Line 3
class1 cls1 = new class1();
}たった 3 行のコードで、行ごとにどのように実行されるかを理解できます。
•行 1: この行が実行されると、コンパイラーはスタック上に小さなメモリを割り当てます。スタックは、アプリケーションが実行中のメモリを必要としているかどうかを追跡する役割を果たします
• 行 2: ここで 2 番目のステップが実行されます。名前が示すように、スタックは、最初のステップで作成されたメモリ割り当ての上に、ここで小さなメモリ割り当てを積み重ねます。スタックは、互いに積み重ねられた部屋またはボックスと考えることができます。スタックでは、データは LIFO (Last In First Out) ロジック ルールに従って割り当ておよび割り当て解除されます。言い換えれば、最初にスタックに入るデータ項目が最後にスタックから取り出される可能性があります。
• 3 行目: 3 行目では、オブジェクトを作成します。この行が実行されると、.NET はスタック上にポインタを作成し、実際のオブジェクトは「ヒープ」と呼ばれるメモリ領域に格納されます。 「ヒープ」は実行中のメモリを監視するものではなく、いつでもアクセスできる単なるオブジェクトの集まりです。スタックとは異なり、ヒープは動的なメモリ割り当てに使用されます。
•ここでもう 1 つ注意すべき重要な点は、オブジェクトの参照ポインタがスタック上に割り当てられることです。 たとえば、宣言ステートメント Class1 cls1; は、実際には Class1 のインスタンスにメモリを割り当てず、スタック上に変数 cls1 の参照ポインタを作成するだけです (そしてそのデフォルトの位置を null に設定します)。新しいキーワードが見つかった場合にのみ、ヒープ上のオブジェクトにメモリが割り当てられます。
•この Method1 メソッドを終了するとき (楽しいところ): 実行制御ステートメントがメソッド本体から終了し始めます。この時点で、スタック上の変数に割り当てられたすべてのメモリ領域がクリアされます。つまり、上記の例では、int 型に関連するすべての変数が、「LIFO」後入れ先出し方式でスタックから 1 つずつポップされます。
•この時点ではヒープ内のメモリ ブロックは解放されないことに注意してください。ヒープ内のメモリ ブロックは後でガベージ コレクターによってクリーンアップされます。
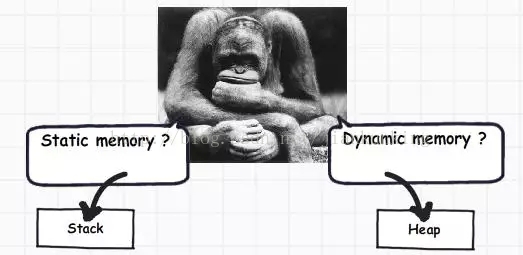
さて、開発者の友人の多くは、なぜ 2 つの異なるタイプのストレージがあるのか不思議に思っているはずです。すべてのメモリ ブロックを 1 種類のストレージだけに割り当てることができないのはなぜですか?
よく見てみると、プリミティブ データ型は複雑ではなく、「int i = 0」のような値を保持しているだけです。オブジェクト データ型はさらに複雑で、他のオブジェクトまたは他のプリミティブ データ型を参照します。言い換えれば、それらは他の複数の値への参照を保持しており、これらの値は 1 つずつメモリに格納する必要があります。オブジェクト型には動的メモリが必要ですが、プリミティブ型には静的メモリが必要です。要件が動的メモリの場合は、ヒープ上にメモリを割り当てます。そうでない場合は、スタック上にメモリを割り当てます。
4. 値型と参照型
スタックとヒープの概念を理解したので、次は値型と参照型の概念を理解します。値型はデータとメモリの両方を同じ場所に保持しますが、参照型は実際のメモリ領域へのポインタを持ちます。
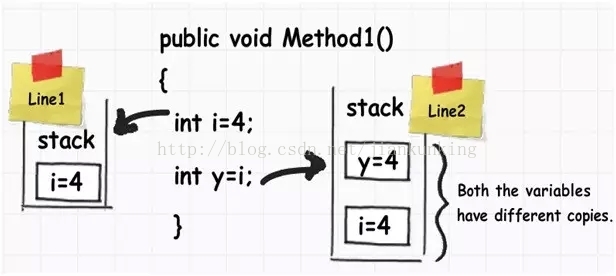
下の図では、i という名前の整数データ型と、その値が j という名前の別の整数データ型に割り当てられていることがわかります。それらの値はスタックに保存されます。
int 型の値を int 型の別の値に代入すると、実際にはまったく異なるコピーが作成されます。つまり、一方の値を変更しても、もう一方の値は変更されません。したがって、このような種類のデータ型は「値型」と呼ばれます。
オブジェクトを作成し、このオブジェクトを別のオブジェクトに割り当てると、以下のコード スニペットに示すように、両方とも同じメモリ領域を指します。したがって、obj を obj1 に割り当てると、両方ともヒープ内の同じ領域を指します。言い換えれば、この時点でいずれかを変更すると、もう一方も影響を受けるということです。これが、これらが「参照型」と呼ばれる理由でもあります。
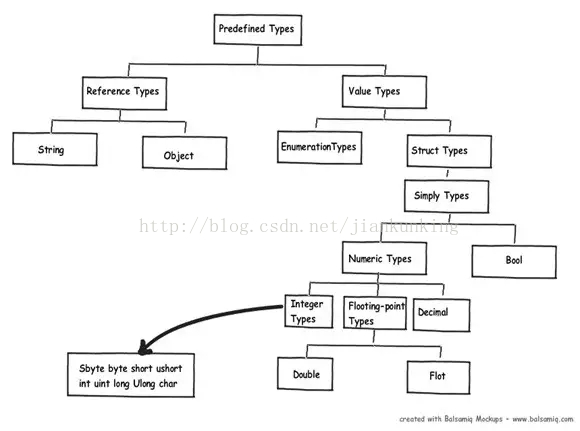
5. どれが値型でどれが参照型ですか?
.NET では、変数がスタックに格納されるかヒープに格納されるかは、その変数が属するデータ型に完全に依存します。たとえば、「String」または「Object」は参照型ですが、他の .NET プリミティブ データ型はスタック上に割り当てられます。次の図は、.NET プリセット タイプのどれが値タイプであり、どれが参照タイプであるかを詳細に示しています。
6. 梱包と開梱
これで、すでに多くの理論的基礎ができました。ここで、上記の知識が実際のプログラミングでどのように使用されるかを理解します。アプリケーションにおける最大の意味の 1 つは、データがスタックからヒープに、またはその逆に移動されるときに発生するパフォーマンス消費の問題を理解することです。
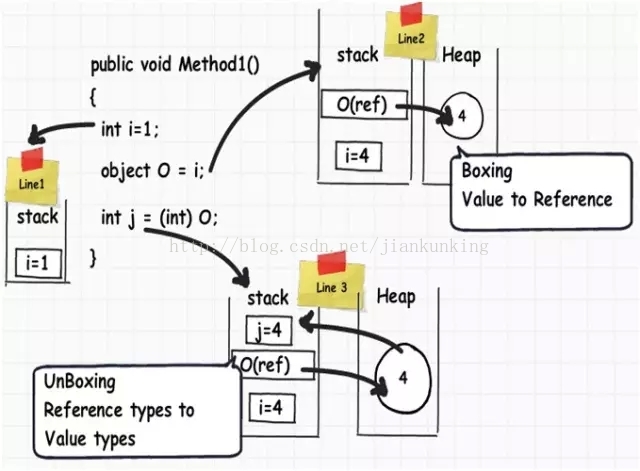
次のコード スニペットを考えてみましょう。値型を参照型に変換すると、データはスタックからヒープに移動されます。逆に、参照型を値型に変換すると、データもヒープからスタックに移動されます。
スタックからヒープに移動する場合でも、ヒープからスタックに移動する場合でも、システムのパフォーマンスに何らかの影響を与えることは避けられません。
そこで、2 つの新しい用語が出てきました。データが値型から参照型に変換されるときのプロセスは「ボックス化」と呼ばれ、参照型から値型に変換するプロセスは「アンボックス化」と呼ばれます。 」。
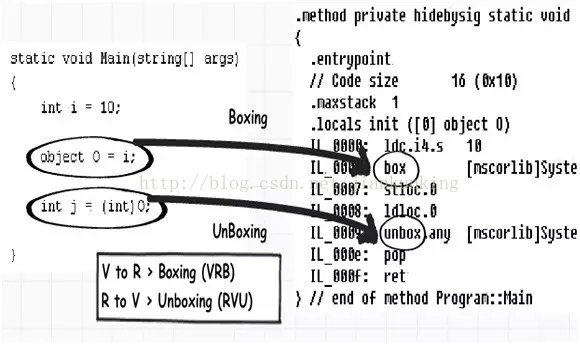
上記のコードをコンパイルして ILDASM (IL の逆コンパイル ツール) で表示すると、IL コードでのボックス化とアンボックス化がどのように見えるかがわかります。以下の図は、サンプルコードをコンパイルした後に生成される IL コードを示しています。
7. ボックス化とアンボックス化のパフォーマンスの問題
ボックス化とアンボックス化のパフォーマンスへの影響を理解するために、以下の図に示すように 2 つの関数メソッドを 10,000 回サイクルしました。最初のメソッドにはボックス化操作があり、もう 1 つはボックス化操作がありません。 Stopwatch オブジェクトを使用して時間の消費を監視します。
ボックス化操作を使用したメソッドは完了までに 3542 ミリ秒かかりましたが、ボックス化操作を使用しないメソッドは 2477 ミリ秒しかかからず、1 秒以上の差がありました。さらに、この値はサイクル数が増加するにつれて増加します。言い換えれば、ボックス化およびボックス化解除操作を避けるように努める必要があります。プロジェクトでボックスアンドボックスが必要な場合は、それが絶対に必要な操作であるかどうかを慎重に検討し、そうでない場合は使用しないようにしてください。

上記のコード スニペットはボックス化解除操作を示していませんが、その効果はボックス化解除にも適用されます。コードを記述してボックス化解除を実装し、ストップウォッチを通じてその時間の消費をテストできます。
上記は、.NET の 6 つの重要な概念です: スタック、ヒープ、値の型、参照型、ボックス化とボックス化解除 その他の関連コンテンツについては、PHP 中国語 Web サイト (m.sbmmt.com) に注目してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



