

カールに関しては、Baidu にアクセスしてください。私は直接ケースに行きます。
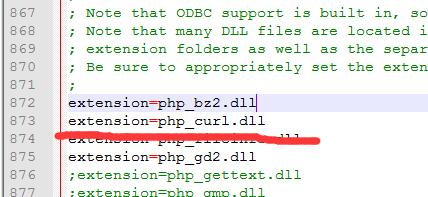
まず、curl 拡張機能を有効にし、php.ini ファイルで Curl 拡張機能をオンにします。つまり、extension=php_curl.dll のセミコロンをキャンセルします。
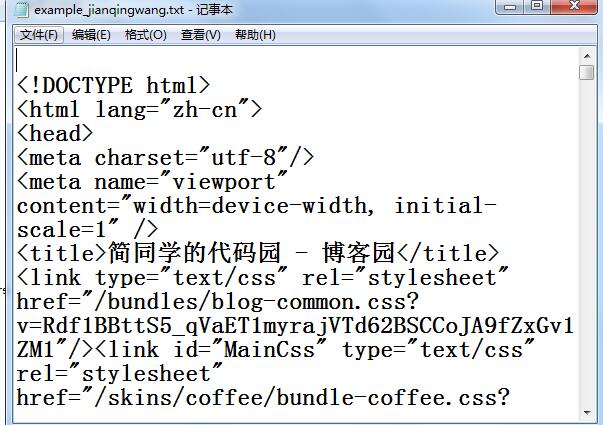
例:curl を使用して Web サイトのコンテンツを収集し、それを txt ドキュメントに出力します:
目標: このブログのトップページを取得してドキュメントに出力します
効果:
例: Web サイトのコンテンツをキャプチャして直接出力
目標: http://www.cnblogs.com/jianqingwang/ を取得し、直接出力します
// 1. 初期化
$ch =curl_init();
// 2. URL を含むオプションを設定します
curl_setopt($ch, CURLOPT_URL, "http:// www.cnblogs.com/jianqingwang/");
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 0);//0 に変更すると出力はなくなります
curl_setopt($ch, CURLOPT_HEADER, 0);
// 3. HTML ドキュメントを実行してコンテンツを取得します
$output =curl_exec($ch);
// 4. Curl ハンドルを解放します
curl_close($ch);
? >
効果:

注: ここでのインターフェイスは少し異なります。CSS アドレスと画像アドレスは両方とも相対パスであるため、画像と CSS は無効です。
例:

















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



