ここで説明するのは最も基本的な関数だけです。レコード: フィールドの定義と取得データの保存。 Record は Store と連携することもでき、Store は Record の変更を追跡できます。 C# の DataTable と同様に、内部 DataRow への変更を追跡できます。 Extjs は、フロントエンド開発をほぼバックエンド開発に変えます。これらのコンテンツは、ストアの導入時に後日紹介されます。
2. データ プロキシ
Ext.data.DataProxy はデータ プロキシの抽象基本クラスであり、DataProxy の一般的なパブリック インターフェイスを実装します。 DataProxy の最も重要な一般メソッドは doRequest です。このメソッドを実行すると、さまざまな特定のデータ ソースからデータが読み取られます。 DataProxy から継承される特定の Proxy クラスは次のとおりです。
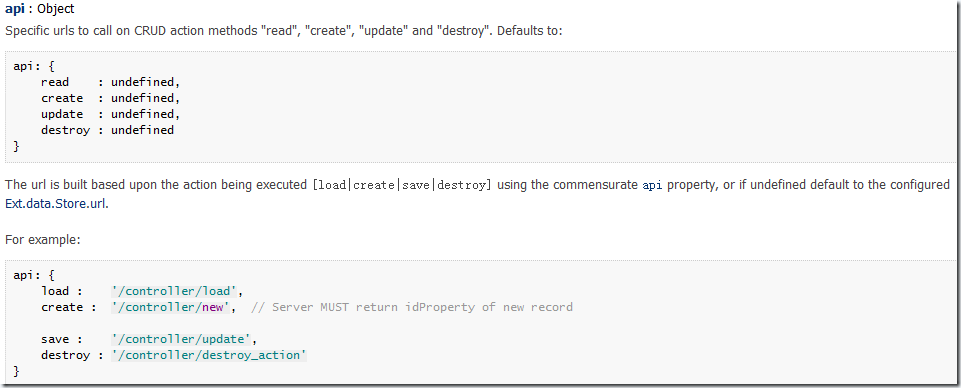
これは、http リクエストを通じてリモート サーバーからデータを取得する、最も一般的に使用されるプロキシです。 HttpProxy の最も重要な設定項目は、データを取得するための URL の設定です。 HttpProxy はデータの取得をサポートするだけでなく、データの CRUD 操作もサポートします。 DataProxy の api 属性は、これら 4 つの操作に対応する URL を構成するために使用されます。構成されていない場合は、HttpProxy の url 属性が使用されます。例:
api: {
read: '/controller/load',
create : '/controller/new', // サーバーは新しいレコードの idProperty を返さなければなりません
save : '/controller/update',
destroy : '/controller/ destroy_action'
}
extjs の公式ドキュメントはここで非常に曖昧であることに注意してください:
4 つの操作のうちの最初の操作は読み取りまたはロードですか? ? ?
API を構成した後、doRequest メソッドを実行できます。doRequest メソッドのパラメータは比較的複雑です。
doRequest( String action, Ext.data.Record/Ext.data.Record[] rs 、オブジェクト パラメータ、Ext.data.DataReader リーダー、関数コールバック、オブジェクト スコープ、オブジェクト arg) には次の意味があります: action: 実行される操作の種類を示します。作成、読み取り、更新、破棄のいずれかになります。 rs: 長い間見ても、このパラメータの用途がわかりませんでした... ソースコードを見ると、url rs.id という式が含まれていることがわかりました。おそらくこれです。 MVC アーキテクチャ プログラムの URL をより適切に構築するために使用されていましたか?それを無視して null に設定してください。 params: このオブジェクトの属性:値のペアは、post/get のパラメーターとしてサーバーに渡されます。これは非常に便利です。
reader: DataReader、サーバーから返されたデータを解析して Record の配列にします。より詳細な説明は次のとおりです。
callback: サーバーデータの読み取り後に実行される関数。この関数は、次の 3 つのパラメータを受け取ります。 r Ext.Record[]、サーバーからリーダーを通じて返される配列。これは、実際のテストでは、アクションが読み取られた場合にのみ当てはまるようです。 options: は arg パラメータの値です。 success: 成功したかどうかにかかわらず、ブール値。これもサーバーによって返されます。
scope: スコープ
arg: いくつかの追加パラメータがコールバックの options パラメータに渡されます。
httpproxy を使用して基本的な CRUD 操作を完了する以下の例を完成させましょう。まずサーバー側のコードを見てみましょう:
<%@ WebHandler Language ="C#" Class="dataproxy" %>
using System.Web;
using System.Collections.Generic; 🎜>public class dataproxy : IHttpHandler {
static List db = new List();
{
db.Add(new Student { Id = " 1", 名前 = "李 ", 電話 = "1232" });
db.Add(新しい学生 { ID = "2", 名前 = "王", 電話 = "5568" });
db.Add(新しい学生 { ID = "3", 名前 = "チェン", 電話 = "23516" });
db.Add(新しい学生 { ID = "4", 名前 = "朱", 電話= "45134" });
db.Add(new Student { Id = "5", Name = "Zhou", Telephone = "3455" });
}
public void ProcessRequest (HttpContext context) ) {
string id = context.Request.Params["id"];
string action=context.Request.Params["action"];
string result = "{success:false}";
if (action = = "create")
{
}
else if (action == "read")
{
foreach (データベース内の学生 stu)
{
if (stu .Id == id)
{
result = "{success:true,r:[['" stu.Id "','" stu.Name "','" stu.Telephone "']] }";
break;
}
}
else if (action == "update")
{
}
else if (action == "削除")
{
}
context.Response.ContentType = "text/plain"
context.Response.Write(result);
public bool IsReusable {
get {
return false;
}
}
クラス Student
{
文字列 ID;パブリック文字列 ID
{
get { return id; }
set { id = 値; }
}
文字列名
{
get { 名前を返す; }
set { name = 値; }
}
パブリック文字列 電話
{
get { 電話を返す }
set { Telephone = value; }
}
}
}
データベースを模倣するために静的なリストを使用します。処理関数では 4 つの状況がそれぞれ処理されます。最終的なクライアントは ArrayReader を使用してデータを解析するため、上記のコードは読み取りコードを実装して配列を返すだけです。サーバー側のコードは説明する必要はありません。非常に単純です。クライアント側のコードを見てみましょう。
コード
コードは次のとおりです:
ここで説明する必要があることがいくつかあります。まず、サーバー側のコードと一致する Student's Record を定義します。次に、ArrayReader が定義されます。ArrayReader は、配列内のデータを読み取ります。このデータ形式は、json データ内のどの属性値を読み取るかを指定します。どのフィールドが主キーであるかを示す配列リテラル ).idIndex も指定する必要があります。フィールドは理解しやすく、レコードのフィールドが読み取られます。配列内の順序は、レコードのフィールド順序に対応する必要があります。それ以外の場合は、レコードのマッピング属性を通じて指定できます。たとえば、{name:'Telephone',mapping:4} は、4 番目の値を読み取ることを意味します。配列を入力し、それを [電話] フィールドに入力します。 以下は httpProxy の定義と API の設定です。次に、フォームを作成します:

ボタンを 4 つ追加します。まず、Read ボタンの処理関数を作成します。doRequest の 1 つのパラメーターは「read」で、2 番目のパラメーターはその用途が理解できないため null です。3 番目のパラメーターは、クエリ対象の ID の値をサーバーに渡します。および 3 番目のパラメータ 4 つのパラメータはリーダーであり、5 番目のパラメータのコールバックはここでサーバーの戻り値を処理します。最後のパラメータを arrayReader に設定したため、この関数のオプション パラメータの値は実際には arrayReader であることに注意してください。なぜこれを行う必要があるのでしょうか? 第一に、最後のパラメータの用途を説明するためです。第二に、ArrayReader には public successProperty 構成項目がないことに注意してください。つまり、このコールバックの success パラメーターは常に未定義です。最初はサーバー側のコードが間違っているのではないかと思いましたが、ソース コードをデバッグしたところ、それが処理されていないことがわかりました。成功属性。おそらく ArrayReader はこの環境で使用するように設計されていないのでしょう。しかし、デモンストレーションとして、このように使用してみましょう。実際、成功パラメータは処理されませんが、それでも自分で処理できます。 arrayReader 内には、解析された json オブジェクトである arrayData 属性があります。返された json 文字列に success 属性がある場合、このオブジェクトにも success 属性があるため、同じ方法でサーバーの戻り値を取得できます。 、返されたデータをサーバーで処理することもできます。もちろん、この使用法はドキュメントには記載されておらず、デモンストレーションのみを目的としています。このコールバックの最初のパラメータに特に注意してください。ドキュメントでは Record[] と記載されていますが、実際にはオブジェクトであり、そのレコード属性は Record[] です。私が言えるのは、extjs のこの部分のドキュメントがひどいということだけです。幸いなことに、コードのこの部分は非常に優れており、興味のある友人はそれをデバッグして、より深く理解するために見ることができます。 OK、すべての準備が整ったので、「読み取り」ボタンをクリックすると、結果が表示されます:

この記事は一旦終了します。他のいくつかの操作も原理的には似ていますが、この例を単に使用して説明するのは不適切であると突然気づきました。削除サーバーも更新サーバーもデータを返す必要がなく、doRequest は返されたデータを解析するために DataReader の使用を強制するため、非常に不便です。おそらく、表形式のデータを操作するときに doRequest の他のメソッドが機能することになるでしょう。単一オブジェクトの CRUD の場合、下位レベルの Ext.ajax メソッド (別の記事で説明) を直接使用するか、form メソッドを使用して処理できます。
この記事は、Extjs データ モデルの機能と原理を簡単に紹介したものにすぎません。実際には、コードを効率的に編成してサーバーとクライアント間でデータを転送する方法は別のトピックです。 Extjs は依然として非常に柔軟であり、クライアントとサーバー間の通信規約は依然としてプログラマーによって決定できます。
長すぎます…次の章に進んでください…





















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



