前述の各メソッドで言及されていない側面が 1 つあります。それは、ソース コード内の $break と $ continue です。これら 2 つの変数は事前定義されており、その機能は通常のループの Break ステートメントと continue ステートメントと同等です。効率上の理由から、一部の操作ではコレクション (配列に限定されません) を完全に走査する必要がないため、break と continue は依然として必要です。
ループの場合、ループを終了する次の方法を比較します:
var array_1 = [1,2,3]
var array_2 = ['a','b','c']; for( var i = 0, len = array_1.length; i < len; i ){
for(var j = 0, len_j = array_1.length; i < len_j; j ){
if( 'c ' === array_2[j]){
break;
}
console.log(array_2[j])
}
}
}); // a,b,a,b,a,b
(function(){
for(var i = 0, len = array_1.length; i
try{
for(var j = 0, len_j = array_1.length; i < len_j; j ){
if('c' === array_2[j]){
throw new Error();
}
console.log(array_2[j]);
}
}catch(e){
console.log('1 レベルのループを終了');
}
})();//a,b,'ループの 1 レベルを終了',a,b,'ループの 1 レベルを終了',a,b,'ループの 1 レベルを終了'
(function() {
try{
for(var i = 0, len = array_1.length; i < len; i ){
for(var j = 0, len_j = array_1.length長さ; i < len_j ; j ){
if('c' === array_2[j]){
throw new Error();
console.log(array_2[j] ]);
}
}
}catch(e){
console.log('1 レベルのループを終了'); // a,b,'ループの 1 レベルを終了' レイヤ ループ'
対応するループ レベルでエラー トラップを配置すると、対応するループを中断できます。ブレーク、ブレークラベル(goto)の機能を実現できます。このようなアプリケーション要件の 1 つは、割り込みを外部に移動できることです。これは、Enumerable の要件を正確に満たしています。
Enumerable に戻ります。各 (each = function(iterator, context){}) メソッドの本質はループであるため、その最初のパラメーターの反復子にはループが含まれていないため、break ステートメントは直接呼び出されます。構文エラーが報告されるため、プロトタイプのソース コードでは上記の 2 番目の方法が使用されます。
コードをコピー
iterator.call(context, value,index );
}); }catch( e){
if(e != $break){
throw e;
}
}
1 回 イテレータの実行中に $break がスローされると、ループは中断されます。 $break でない場合は、対応するエラーがスローされ、プログラムはより安定します。ここでの $break の定義には特別な要件はありませんが、好みに応じて変更できますが、あまり意味がありません。
Enumerable の一部のメソッドは、一部の最新のブラウザーに実装されています (Chrome ネイティブ メソッドの配列を参照)。比較表は次のとおりです。
これらのメソッドを実装する場合、ネイティブ メソッドを借用して効率を向上させることができます。ただし、ソース コードはネイティブ部分を借用していません。これは、おそらく Enumerable を Array 部分に加えて他のオブジェクトに混合する必要があるためです。
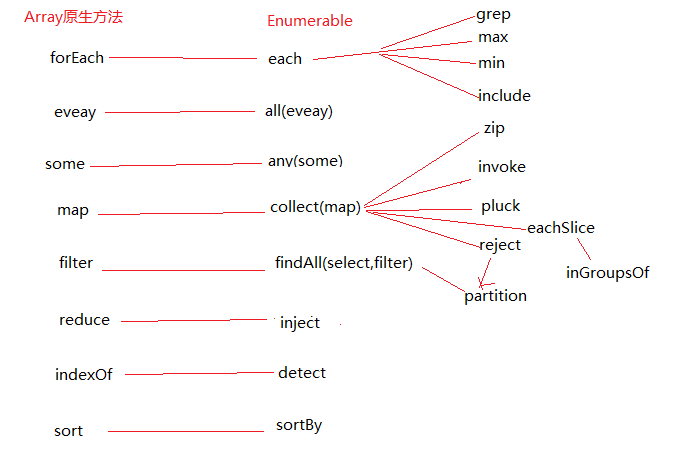
上の図を見ると、それぞれの重要性が明確にわかります。マップの本質はやはりそれぞれですが、それぞれがコレクションの各項目を順番に処理し、マップもそれぞれに基づいています。処理された結果を返します。 Enumerable 内では、map はcollect メソッドのエイリアスであり、もう 1 つのエイリアスは select であり、collect という名前が内部的に使用されます。
検出: all | any | include
これら 3 つのメソッドは、元のコレクションの処理を含まず、戻り値はすべてブール型です。
 all : Enumerable 内のすべての要素が true と同等の場合は true を返し、それ以外の場合は false を返します
all : Enumerable 内のすべての要素が true と同等の場合は true を返し、それ以外の場合は false を返します
コードをコピー
コードは次のとおりです。
function all(iterator, context) {
var result = true; this.each(function(value,index) { 結果 = 結果 && !!iterator.call(コンテキスト, 値, インデックス); 結果を返します all メソッドの場合、内部の 2 つのパラメータは必要ないため、実際のパラメータなしでイテレータを置き換え、元の値を直接返す関数が内部的に提供されています。名前は Prototype.K です。 Prototype.K はライブラリの先頭で定義され、Prototype.K = function(x){return x;} という関数です。なお、allメソッドでは、1つの項目の処理結果がfalseである限り、処理全体を破棄(ブレーク)できるため、この記事の冒頭でループを中断する方法を採用しています。最終的な形式は次のとおりです:
Prototype.K = function() {};
Enumerable.all = function(iterator, context) {
iterator = iterator ||
this.each(value) , インデックス) {
結果 = 結果 && !!iterator.call(context, value,index);
if (!result) throw $break;
>}
返される最終結果はブール型です。すべてから逸脱している場合は、結果を変更しましょう:
iterator = iterator ||
var results = [] ;
this.each(関数(値, インデックス) {
結果.push(コンテキスト, 値, インデックス));
結果を返す
}
このとき、結果は処理を中断せず、すべての結果を保存して返します。これがcollectメソッド、またはmapメソッドです。
any: Enumerable 内の 1 つ以上の要素が true に等しい場合は true を返し、それ以外の場合は false を返します。原理はすべて同様で、false が見つかった場合に動作を停止します。 true の場合は、それをやめてください。
コードをコピー
コードは次のとおりです。 function any(iterator, context) { iterator = iterator ||
var result = false;
this.each(function(value,index) {
if (result = !!iterator.call(context, value, Index))
throw $break;
});
return result;
include: 指定されたオブジェクトが Enumerable に存在するかどうかを判断し、それに基づいて比較します== 演算子 このメソッドの最適化の 1 つのステップは、indexOf メソッドを呼び出すことです。配列の場合、indexOf が -1 を返す場合、コレクションにindexOf メソッドが存在しない可能性があります。検索して比較するだけです。ここには検索と合計のアルゴリズムはなく、1 つずつ走査するだけです。書き直すのは簡単ですが、一般的には使用されないため、これを最適化するための労力は費やされていないと推定されます。したがって、結果が true の場合、結果が false の場合よりも効率が高くなります。これは運に依存します。
コードをコピー
コードは次のとおりです。 function include(object) { if (Object .isFunction(this.indexOf))//この判定関数はよく知られているはずですif (this.indexOf(object) != -1) return true;//indexOf がある場合は、
var が直接見つかりました = false;
this.each(function(value) {//ここで効率の問題があります
if (value == object) {
found = true;
throw $ Break;
}
});
return found;
データをフィルタリングするための一連のメソッドを示します。 max | min | detect は配列を返します。 max(iterator, context) には、引き続き 2 つのパラメーターを含めることができます。これを最初に処理してから、値を比較することができます。たとえば、オブジェクト配列に限定される必要がないことです。特定のルールに従って最大値を取得します:
コードをコピー
コードは次のとおりです:
ソース コードの実装は想像できます。直接比較すると、実装は次のようになります。
コードをコピー
コードは次のとおりです。
}
展開後、値はさらに value = (イテレータ処理後の戻り値) になります:
function max(iterator, context) {
iterator = iterator ||
var result;
this.each(function(value,index)) {
value = iterator.call(context, value,index);
if (result == null || value >= result)
result =
}; return result;
}
min も同じ原理です。 detect と any の原理は似ています。any は true が見つかった場合に true を返し、detect は true が見つかった場合に true の条件を満たす値を返します。ソースコードは掲載しません。 grep は見覚えのある Unix/Linux ツールであり、その機能も非常によく知られています。指定された正規表現に一致するすべての要素を返します。ただし、unix/linux は文字列のみを処理できます。ただし、範囲は拡張されていますが、基本的な形式は変わりません。コレクション内の各項目が文字列の場合、実装は次のようになります:
Enumerable.grep = function(filter) {
if(typeof filter == 'string'){
filter = new RegExp(filter); results = [];
this.each(function(value,index){
if(value.match(filter)){
results.push(value);
}
} )
return results;
};
ただし、より広範囲のアプリケーションを実現するには、処理対象のコレクションが必要です。考慮すべきは呼び出し形式です。上記の実装を見て、次の文に注目してください:
if(value.match(filter))
ここで、value は文字列、match は String のメソッドです。次に、サポートされる型を拡張する必要があります。またはそれぞれの値を与える match メソッドを追加するか、フォームを変換します。明らかに、最初のタイプのノイズは大きすぎるため、作成者は考えを変えました。
if (filter.match(value))
このように、フィルターにRegExp オブジェクトには match メソッドがないため、作成者はソース コードで RegExp オブジェクトを拡張しました。
RegExp.prototype.match = RegExp.prototype.test;上記の一致は文字列一致とは本質的に異なります。このようにして、値がオブジェクトの場合、フィルターはオブジェクトを検出するために対応する match メソッドを提供するだけで済みます。
コードをコピー
コードは次のとおりです。 function grep(filter,イテレータ、コンテキスト ) { イテレータ = Prototype.K;
var results = [];
if (Object.isString(filter))
filter = new RegExp .escape( filter));
this.each(function(value,index) {
if (filter.match(value))//ネイティブ フィルターには match メソッドがありません。
results .push( iterator.call(context, value,index));
return results;
結果を処理してから、これがイテレータパラメータの役割です。 max メソッドとは異なり、grep はメイン操作を実行するときに反復子を使用して結果を処理します。Max はメイン操作を実行する前に反復子を使用してソース データを処理します。 grep のフィルターが max のイテレーターを置き換えるためです。 findAll については、grep の拡張版です。 grep を読み込むと、findAll は非常に簡単になります。 Reject は findAll の双子のバージョンであり、まったく逆の効果があります。パーティションは findAll 拒否、親子バージョンを結合したものです。 Xiaoxi Shanzi [http://www.cnblogs.com/xesam/]
から転載する場合はその旨を明記してください。



















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



