中国のAIは、GPT-4、Claude、Grokのような挑戦的な主要なモデルで、DeepSeek-V3やQWEN 2.5などの費用対効果の高いオープンソースの代替品を備えた大幅な進歩を遂げています。 これらのモデルは、効率、アクセシビリティ、および強力なパフォーマンスのために優れています。 多くの人が寛容な商業ライセンスの下で運営されており、開発者や企業への訴えを拡大しています。
このグループへの最新の追加である
Minimax-Text-01は、前例のない400万のトークンコンテキストの長さを備えた新しい標準を設定します。この拡張されたコンテキスト機能は、効率性とオープンソースの商業的に寛容なライセンスのためのハイブリッド注意アーキテクチャと組み合わせて、高コストなしでイノベーションを促進します。
Minimax-Text-01の機能を掘り下げましょう
目次
ハイブリッドアーキテクチャ
混合物の混合(MOE)戦略-
トレーニングとスケーリング戦略-
トレーニング後の最適化
-
キーイノベーション-
コアアカデミックベンチマーク-
一般的なタスクベンチマーク-
推論タスクベンチマーク-
数学とコーディングタスクベンチマーク-
-
Minimax-Text-01
を開始します
重要なリンク-
結論-
- ハイブリッドアーキテクチャ
Minimax-Text-01は、稲妻の注意、ソフトマックスの注意、およびエクスパーの混合物(MOE)を統合することにより、効率とパフォーマンスのバランスを巧みにバランスさせます。
 7/8線形注意(Lightning Atterness-2):
7/8線形注意(Lightning Atterness-2):
この線形注意メカニズムは、長いコンテキスト処理に理想的なO(n²d)からO(d²n)に計算の複雑さを大幅に減らします。 入力変換にはSiluの活性化、注意スコアの計算にはマトリックス操作、RMSNORMとSIGMOIDを正規化とスケーリングに使用します。
- 1/8ソフトマックスの注意:伝統的な注意メカニズム、注意ヘッド寸法の半分にロープ(回転位置の埋め込み)を組み込み、パフォーマンスを犠牲にすることなく長さの外挿を可能にします。
混合物の混合(MOE)戦略-
Minimax-Text-01のユニークなMOEアーキテクチャは、DeepSeek-V3:のようなモデルと区別しています。
-
トークンドロップ戦略:deepseekのドロップレスアプローチとは異なり、専門家間のバランストークン分布を維持するために補助損失を採用しています。
- グローバルルーター:専門家グループ間のワークロード分布のトークン割り当てを最適化します。
トップKルーティング:- トークンごとにトップ2の専門家を選択します(DeepSeekのTop-8 1共有エキスパートと比較して)
エキスパート構成:
32人の専門家(vs. deepseekの256 1共有)を利用して、9216(vs. deepseekの2048)の隠された次元を持つ。 レイヤーあたりの総アクティブ化されたパラメーターは、DeepSeek(18,432)と同じままです。
-
トレーニングとスケーリング戦略
トレーニングインフラストラクチャ:
約2000 H100 GPUをレバレッジし、エキスパートテンソル並列性(ETP)や線形注意シーケンスパラレズム(LASP)などの高度な並列性技術を採用しています。 8x80GB H100ノードでの効率的な推論のために8ビット量子化用に最適化。
- トレーニングデータ:WSD様学習率スケジュールを使用して、約12兆トークンでトレーニングされています。 データは、高品質のソースと低品質のソースのブレンドで構成され、高品質のデータのためのグローバルな重複排除と4倍の繰り返しがありました。
ロングコンテキストトレーニング:- 3段階的アプローチ:フェーズ1(128Kコンテキスト)、フェーズ2(512Kコンテキスト)、およびフェーズ3(1Mコンテキスト)、線形補間を使用して、コンテキストの長さのスケーリング中に分布シフトを管理します。
トレーニング後の最適化
-
反復的な微調整:
監視付き微調整(SFT)および補強学習(RL)のサイクル。
ロングコンテキストの微調整:
段階的アプローチ:ショートテキストSFT→ロングコンテキストSFT→ショートコンテキストRL→長いコンテキストRL、優れた長いコンテキストパフォーマンスには重要です。
- キーイノベーション
- deepnorm:残留接続のスケーリングとトレーニングの安定性を強化するポストノームアーキテクチャ。
バッチサイズのウォームアップ:
最適なトレーニングダイナミクスのために、バッチサイズが16mから128mのトークンに徐々に増加します。
効率的な並列性:リングの注意を利用して、長いシーケンスとパディングの最適化のメモリオーバーヘッドを最小限に抑えて、無駄な計算を減らす。
-
コアアカデミックベンチマーク
-
(一般的なタスク、推論タスク、数学およびコーディングタスクのベンチマーク結果を示すテーブルは、元の入力テーブルを反映しています。)
-
(追加の評価パラメーターリンクの残り)
Minimax-Text-01
を開始します
(hugging hugging face transformersを使用してminimax-text-01を使用するためのコード例は同じままです。)
重要なリンク
チャットボット
Minimax-Text-01は、長いコンテキストおよび汎用タスクで最先端のパフォーマンスを達成する印象的な機能を実証しています。改善の領域は存在しますが、そのオープンソースの性質、費用対効果、革新的なアーキテクチャにより、AI分野の重要なプレーヤーになります。 これは、メモリ集約型で複雑な推論アプリケーションに特に適していますが、コーディングタスクのさらなる改良が有益である可能性があります。
以上が4Mトークン? Minimax-Text-01はDeepSeek V3を上回りますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。



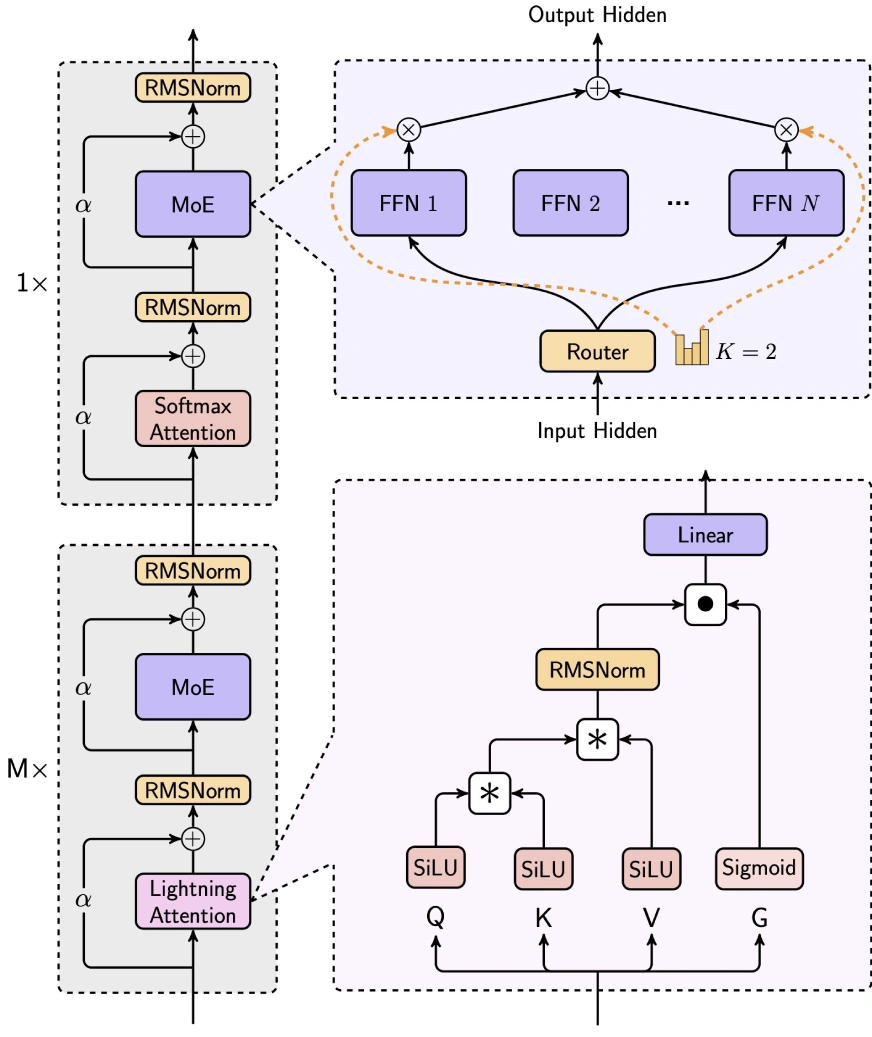 7/8線形注意(Lightning Atterness-2):
7/8線形注意(Lightning Atterness-2):















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



