


GitHub: https://github.com/chatsapi/ChatsAPI
ライブラリ: https://pypi.org/project/chatsapi/
人工知能は業界を変革しましたが、それを効果的に導入することは依然として困難な課題です。複雑なフレームワーク、遅い応答時間、急峻な学習曲線が、企業と開発者の両方にとって障壁となっています。 ChatsAPI をご利用ください。これは、比類のないスピード、柔軟性、シンプルさを実現するように設計された、画期的な高性能 AI エージェント フレームワークです。
この記事では、ChatsAPI のユニークな点、それがゲームチェンジャーである理由、そして開発者が比類のない簡単さと効率でインテリジェントなシステムを構築できるようにする方法を明らかにします。
ChatsAPI は単なる AI フレームワークではありません。それは AI 主導のインタラクションにおける革命です。その理由は次のとおりです:
速度: 応答時間がミリ秒未満である ChatsAPI は、世界最速の AI エージェント フレームワークです。 HNSWlib を利用した検索により、大規模なデータセットであっても、ルートと知識を超高速で取得できます。
効率: SBERT と BM25 のハイブリッド アプローチは、セマンティックな理解を従来のランキング システムと組み合わせて、速度と精度の両方を保証します。
LLM とのシームレスな統合
ChatsAPI は、OpenAI、Gemini、LlamaAPI、Ollama などの最先端の大規模言語モデル (LLM) をサポートしています。これにより、LLM をアプリケーションに統合する複雑さが簡素化され、より良いエクスペリエンスの構築に集中できるようになります。
動的ルートマッチング
ChatsAPI は自然言語理解 (NLU) を使用して、比類のない精度でユーザーのクエリを事前定義されたルートに動的に照合します。
@trigger などのデコレーターを使用してルートを簡単に登録します。
ユースケースがどれほど複雑であっても、@extract でパラメーター抽出を使用して入力処理を簡素化します。
高パフォーマンスのクエリ処理
従来の AI システムは速度か精度のいずれかで苦労していますが、ChatsAPI は両方を実現します。膨大なナレッジ ベースから最適な一致を見つける場合でも、大量のクエリを処理する場合でも、ChatsAPI は優れています。
柔軟なフレームワーク
ChatsAPI は、次のものを構築しているかどうかにかかわらず、あらゆるユースケースに適応します。
開発者によって開発者のために設計された ChatsAPI は以下を提供します:
ChatsAPI はその中核として、次の 3 段階のプロセスを通じて動作します。
結果は?高速、正確、そして驚くほど使いやすいシステムです。
カスタマーサポート
非常に高速なクエリ解決により顧客との対話を自動化します。 ChatsAPI により、ユーザーは関連性のある回答を即座に得ることができるため、満足度が向上し、運用コストが削減されます。
ナレッジベース検索
ユーザーが意味を理解して膨大なナレッジ ベースを検索できるようにします。ハイブリッド SBERT-BM25 アプローチにより、正確でコンテキストを認識した結果が保証されます。
会話型 AI
ユーザー入力をリアルタイムで理解し、それに適応する会話型 AI エージェントを構築します。 ChatsAPI はトップ LLM とシームレスに統合し、自然で魅力的な会話を提供します。
他のフレームワークは柔軟性やパフォーマンスを約束しますが、ChatsAPI のように両方を実現できるものはありません。私たちは次のようなフレームワークを作成しました:
ChatsAPI を使用すると、開発者は複雑さやパフォーマンスの低下に悩まされることなく、AI の可能性を最大限に引き出すことができます。
ChatsAPI を始めるのは簡単です:
pip install chatsapi
from chatsapi import ChatsAPI
chat = ChatsAPI()
@chat.trigger("Hello")
async def greet(input_text):
return "Hi there!"
from chatsapi import ChatsAPI
chat = ChatsAPI()
@chat.trigger("Need help with account settings.")
@chat.extract([
("account_number", "Account number (a nine digit number)", int, None),
("holder_name", "Account holder's name (a person name)", str, None)
])
async def account_help(chat_message: str, extracted: dict):
return {"message": chat_message, "extracted": extracted}
Run your message (with no LLM)
@app.post("/chat")
async def message(request: RequestModel, response: Response):
reply = await chat.run(request.message)
return {"message": reply}
import os
from dotenv import load_dotenv
from fastapi import FastAPI, Request, Response
from pydantic import BaseModel
from chatsapi.chatsapi import ChatsAPI
# Load environment variables from .env file
load_dotenv()
app = FastAPI() # instantiate FastAPI or your web framework
chat = ChatsAPI( # instantiate ChatsAPI
llm_type="gemini",
llm_model="models/gemini-pro",
llm_api_key=os.getenv("GOOGLE_API_KEY"),
)
# chat trigger - 1
@chat.trigger("Want to cancel a credit card.")
@chat.extract([("card_number", "Credit card number (a 12 digit number)", str, None)])
async def cancel_credit_card(chat_message: str, extracted: dict):
return {"message": chat_message, "extracted": extracted}
# chat trigger - 2
@chat.trigger("Need help with account settings.")
@chat.extract([
("account_number", "Account number (a nine digit number)", int, None),
("holder_name", "Account holder's name (a person name)", str, None)
])
async def account_help(chat_message: str, extracted: dict):
return {"message": chat_message, "extracted": extracted}
# request model
class RequestModel(BaseModel):
message: str
# chat conversation
@app.post("/chat")
async def message(request: RequestModel, response: Response, http_request: Request):
session_id = http_request.cookies.get("session_id")
reply = await chat.conversation(request.message, session_id)
return {"message": f"{reply}"}
# set chat session
@app.post("/set-session")
def set_session(response: Response):
session_id = chat.set_session()
response.set_cookie(key="session_id", value=session_id)
return {"message": "Session set"}
# end chat session
@app.post("/end-session")
def end_session(response: Response, http_request: Request):
session_id = http_request.cookies.get("session_id")
chat.end_session(session_id)
response.delete_cookie("session_id")
return {"message": "Session ended"}
await chat.query(request.message)
従来の LLM (API) ベースのメソッドは、通常、リクエストごとに約 4 秒かかります。対照的に、ChatsAPI は、LLM API 呼び出しを行わずに、リクエストを 1 秒未満、多くの場合はミリ秒以内に処理します。
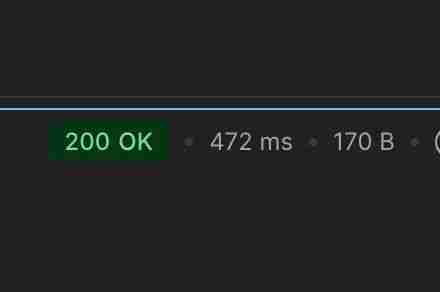
チャット ルーティング タスクを 472 ミリ秒以内に実行します (キャッシュなし)
チャット ルーティング タスクを 21 ミリ秒以内に実行します (キャッシュ後)

チャット ルーティング データ抽出タスクを 862 ミリ秒以内に実行します (キャッシュなし)

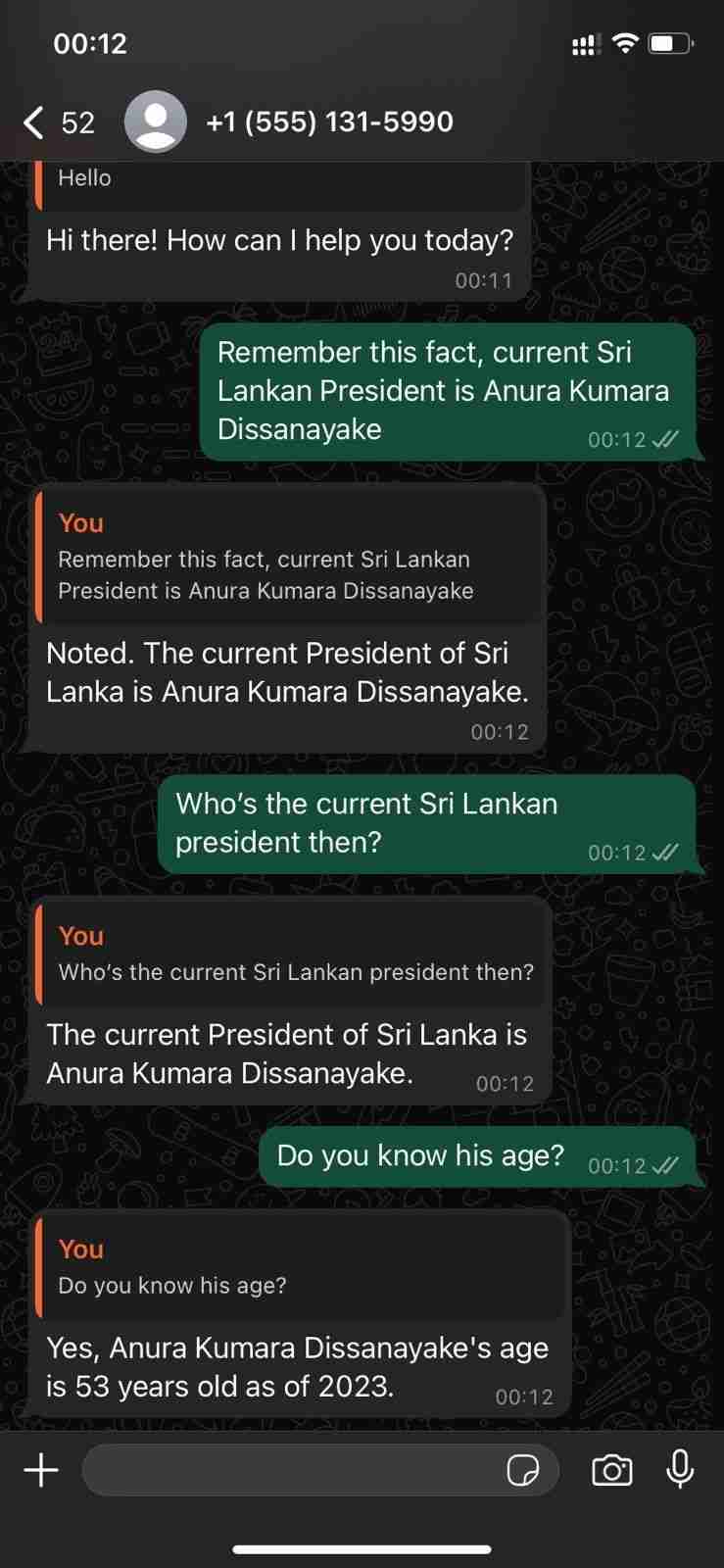
WhatsApp Cloud API を使用した会話機能の実証
ChatsAPI — 機能階層

ChatsAPI は単なるフレームワークではありません。それは、AI システムの構築と操作方法におけるパラダイム シフトです。 ChatsAPI は、速度、精度、使いやすさを組み合わせることで、AI エージェント フレームワークの新しいベンチマークを設定します。
今すぐ革命に参加して、ChatsAPI が AI の状況を変革する理由をご覧ください。
始める準備はできましたか?今すぐ ChatsAPI を始めて、AI 開発の未来を体験してください。
以上がChatsAPI — 世界最速の AI エージェント フレームワークの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



