


CSV ファイルを Django REST にアップロードする (特にアトミック設定の場合) のは簡単な作業ですが、これから共有するいくつかのトリックを見つけるまでは戸惑い続けました。
この記事では、(フロントエンドの代わりに) postman を使用し、写真経由でリクエストを送信するために postman で設定する必要がある内容も共有します。
私たちが望むもの
メソッド
pip install pandas
値のセルで、[ファイルを選択] ボタンをクリックし、CSV をアップロードします。以下のスクリーンショットを確認してください

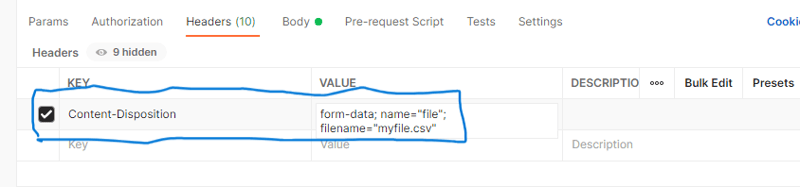
ヘッダーの下で、Content-Disposition と値を form-data に設定します。名前 = "ファイル";ファイル名 = "あなたのファイル名.csv"。 your_file_name.csv を実際のファイル名に置き換えます。以下のスクリーンショットを確認してください。
from rest_framework import status
from rest_framework.views import APIView
from rest_framework.parsers import FileUploadParser
from rest_framework.response import Response
from .models import BiodataModel
from django.db import transaction
import pandas as pd
class UploadCSVFile(APIView):
parser_classes = [FileUploadParser]
def post(self,request):
csv_file = request.FILES.get('file')
if not csv_file:
return Response({"error": "No file provided"}, status=status.HTTP_400_BAD_REQUEST)
# Validate file type
if not csv_file.name.endswith('.csv'):
return Response({"error": "File is not CSV type"}, status=status.HTTP_400_BAD_REQUEST)
df = pd.read_csv(csv_file, delimiter=',',skiprows=3,dtype=str).iloc[:-1]
df = df.where(pd.notnull(df), None)
bulk_data=[]
for index, row in df.iterrows():
try:
row_instance= BiodataModel(
name=row.get('name'),
age=row.get('age'),
address =row.get('address'))
row_instance.full_clean()
bulk_data.append(row_instance)
except Exception as e:
return Response({"error": f'Error at row {index + 2} -> {e}'}, status=status.HTTP_400_BAD_REQUEST)
try:
with transaction.atomic():
BiodataModel.objects.bulk_create(bulk_data)
except Exception as e:
return Response({"error": f'Bulk create error--{e}'}, status=status.HTTP_400_BAD_REQUEST)
return Response({"msg":"CSV file processed successfully"}, status=status.HTTP_201_CREATED)
上記のコードの説明:
コードは、必要なパッケージをインポートし、クラスベースのビューを定義し、パーサー クラス (FileUploadParser) を設定することから始まります。クラスの post メソッドの最初の部分は、request.FILES からファイルを取得し、その可用性を確認しようとします。
次に、マイナー検証で拡張子をチェックして CSV であることを確認します。
次の部分では、それを pandas データフレーム (スプレッドシートによく似ています) にロードします。
df = pd.read_csv(csv_file, delimiter=',',skiprows=3,dtype=str).iloc[:-1]
ローディング関数に渡される引数のいくつかについて説明します:
ハギプロウ
ロードされた CSV ファイルを読み取る際、この場合の CSV はネットワーク経由で渡されるため、ファイルの先頭と末尾にメタデータのようなものが追加されることに注意してください。これらは煩わしい場合があり、カンマ区切り値 (CSV) 形式ではないため、実際には解析時にエラーが発生する可能性があります。これは、メタデータとヘッダーを含む最初の 3 行をスキップして CSV の本文に直接配置するために、skiprows=3 を使用した理由を説明しています。 Skiprows を削除するか、より小さい数値を使用すると、次のようなエラーが発生する可能性があります: データのトークン化エラー。 C エラーが発生した場合、データがヘッダーから始まっていることに気づくかもしれません。
dtype=str
Panda は、特定の列のデータ型を推測することで賢明であることを証明することを好みます。すべての値を文字列として使用したかったので、 dtype=str
区切り文字
セルの分割方法を指定します。通常、デフォルトはカンマです。
iloc[:-1]
iloc を使用してデータフレームをスライスし、df の最後にあるメタデータを削除する必要がありました。
次に、次の行 df = df.where(pd.notnull(df), None) は、すべての NaNvalue を None に変換します。 NaN は、パンダが None を表すために使用する代用の値です。
次のブロックは少し難しいです。データフレーム内のすべての行をループし、BiodataModel で行データをインスタンス化し、一括作成では Django 検証をバイパスするため、full_clean() メソッドで (シリアライザー レベルではなく) モデル レベルの検証を実行し、作成操作を というリストに追加します。バルクデータ。はい、追加はまだ実行されていません!アトミックな操作 (バッチ レベルで) を実行しようとしているので、all または None が必要であることを思い出してください。行を個別に保存しても、all or none の動作は行われません。
それでは最後の重要な部分です。 transaction.atomic() ブロック (全か無かの動作を提供します) 内で、BiodataModel.objects.bulk_create(bulk_data) を実行して、すべての行を一度に保存します。
もう一つ。 for ループ内のインデックス変数と例外ブロックに注目してください。 Excel ファイルで見たときに、その値がその値が存在する行と正確に一致しなかったため、Exception ブロックのエラー メッセージで df.iterrows() から派生したインデックス変数に 2 を追加しました。 excel ブロックはあらゆるエラーをキャッチし、Excel で開いたときに正確な行番号を含むエラー メッセージを構築するため、アップロード者は Excel ファイル内の行を簡単に見つけることができます。
読んでいただきありがとうございます!!!
使用されるツールのバージョン
from rest_framework import status
from rest_framework.views import APIView
from rest_framework.parsers import FileUploadParser
from rest_framework.response import Response
from .models import BiodataModel
from django.db import transaction
import pandas as pd
class UploadCSVFile(APIView):
parser_classes = [FileUploadParser]
def post(self,request):
csv_file = request.FILES.get('file')
if not csv_file:
return Response({"error": "No file provided"}, status=status.HTTP_400_BAD_REQUEST)
# Validate file type
if not csv_file.name.endswith('.csv'):
return Response({"error": "File is not CSV type"}, status=status.HTTP_400_BAD_REQUEST)
df = pd.read_csv(csv_file, delimiter=',',skiprows=3,dtype=str).iloc[:-1]
df = df.where(pd.notnull(df), None)
bulk_data=[]
for index, row in df.iterrows():
try:
row_instance= BiodataModel(
name=row.get('name'),
age=row.get('age'),
address =row.get('address'))
row_instance.full_clean()
bulk_data.append(row_instance)
except Exception as e:
return Response({"error": f'Error at row {index + 2} -> {e}'}, status=status.HTTP_400_BAD_REQUEST)
try:
with transaction.atomic():
BiodataModel.objects.bulk_create(bulk_data)
except Exception as e:
return Response({"error": f'Bulk create error--{e}'}, status=status.HTTP_400_BAD_REQUEST)
return Response({"msg":"CSV file processed successfully"}, status=status.HTTP_201_CREATED)
以上がCSV ファイルを DJANGO REST にアップロードする方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



