


Dify は、オンラインで LLM ワークフローを構築するためのオープンソースの SaaS プラットフォームです。 API を使用して、アプリ上で会話型 AI エクスペリエンスを作成しています。 API 応答として TTS ストリームを取得して再生するのに苦労しました。ここでは、オーディオ ストリームを処理して正しく再生する方法を示します。
テキスト チャットに API エンドポイント https://api.dify.ai/v1/chat-messages を使用しています。 Dify アプリで Text to Speech 機能を有効にした場合、テキスト応答と同じストリームで音声データが返されます。
「機能を追加」ボタンを押して、テキスト読み上げ機能を追加します。
以下のcurlコマンドでAPIからのレスポンスを確認できます
ここでは TypeScript / JavaScript で説明しますが、同じロジックをプログラミング言語に適用できます。
まず、Dify がストリームにどのような種類のデータを使用しているかを理解しましょう。
Difyは以下のテキストデータ形式を使用しています。これは JSON 行に似ていますが、まったく同じではありません。
応答で、Dify はテキスト回答と音声データをプッシュします。
テキスト回答の例
音声データのサンプル行
イベントプロパティをチェックすることで、オーディオデータの JSON 行を区別できます。オーディオ JSON には tts_message が値として含まれます。オーディオ mp3 バイナリは、base64 形式で JSON の audio プロパティに保存されます。
TTS オーディオをリアルタイムで再生するときに発生する最初の問題は、JSON 行がパケットに分割されており、各パケットがそのままでは有効な JSON データではないことです。
真ん中でカットしたパック例
パケットはJSON行の途中から始まります。有効な JSON 行を取得するには、複数のパケットを結合する必要があります。
2 番目の問題は、JSON 内の音声データ チャンクが有効な音声データではないことです。 mp3のフレームの途中でデータが切れています
JSONとmp3の分割データを扱うには、何らかの賢い方法を行う必要があります。プロセスの流れは次のとおりです:
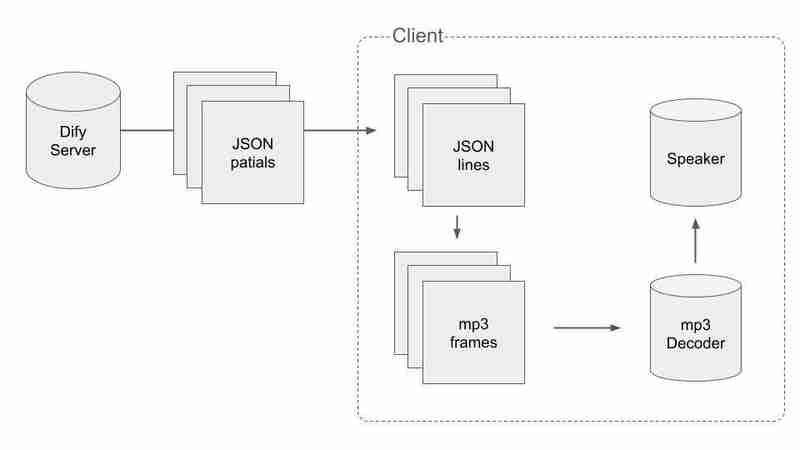
まず、有効な JSON データを取得し、パケットの受信中に JSON に分割する必要があります。最後に n が付いているパケットを取得した場合、それまでに受信したパケットの連結が途中で切れていないと言えます。擬似コードはこんな感じです
次に、オーディオチャンクをmp3フレームに分割する必要があります。オーディオチャンクをバイナリに連結し、その中の各 MP3 フレームを見つけます。
これは、mp3 フレームへの分割の完全な実装ではありません。実際のプロセスでは、オーディオ バイナリから mp3 フレームを抽出したときに残りのバイトがあり、その残りを次の反復でオーディオ バイトの先頭として使用する場合を考慮する必要があります。完全な実装については、私の Github リポジトリを確認してください。
以上がDify APIでリアルタイムスピーチを実現する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。





























![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



