


過去数年で、Transformer アーキテクチャは大きな成功を収め、視覚的なタスクの処理に優れた Vision Transformer (ViT) などの多数の亜種も生み出しました。この記事で紹介するボディ トランスフォーマー (BoT) は、ロボットの戦略学習に非常に適したトランスフォーマーの亜種です。
物理エージェントが動作の修正と安定化を実行するとき、多くの場合、それが感じた外部刺激の位置に基づいて空間反応を与えることがわかっています。たとえば、これらの刺激に対する人間の反応回路は脊髄神経回路のレベルにあり、特に単一のアクチュエータの反応を担当します。ローカルでの修正実行は効率的な動作の主要な要素であり、これはロボットにとっても特に重要です。
しかし、以前の学習アーキテクチャでは通常、センサーとアクチュエーターの間の空間的相関関係が確立されていませんでした。ロボット戦略では、主に自然言語とコンピューター ビジョン向けに開発されたアーキテクチャが使用されるため、ロボット本体の構造を効果的に活用できないことがよくあります。
ただし、この点においては、Transformer には依然として大きな可能性があり、Transformer は長いシーケンスの依存関係を効果的に処理でき、大量のデータを容易に吸収できることが研究によって示されています。 Transformer アーキテクチャは、もともと非構造化自然言語処理 (NLP) タスク用に開発されました。これらのタスク (言語翻訳など) では、通常、入力シーケンスが出力シーケンスにマッピングされます。
この観察に基づいて、カリフォルニア大学バークレー校のピーター・アッビール教授が率いるチームは、ロボット本体上のセンサーとアクチュエーターの空間的位置に注目を加えるボディートランスフォーマー (BoT) を提案しました。

論文のタイトル: Body Transformer: Leveraging Robot Improvement for Policy Learning
論文のアドレス: https://arxiv.org/pdf/2408.06316v1
プロジェクトのウェブサイト: https://sferrazza .cc/bot_site
コードアドレス: https://github.com/carlosferrazza/BodyTransformer
具体的には、BoT はロボット本体をグラフにモデル化し、そのノードがセンサーとアクチュエーターになります。次に、アテンション層で高度にスパースなマスクを使用して、各ノードがそのすぐ隣以外の部分に注意を払わないようにします。構造的に同一の複数の BoT レイヤーを接続すると、アーキテクチャの表現機能を損なうことなく、グラフ全体からの情報がまとめられます。 BoT は模倣学習と強化学習の両方で優れたパフォーマンスを発揮し、一部では戦略学習の「ゲームチェンジャー」であると考えられています。
Body Transformer
ロボット学習戦略が元の Transformer アーキテクチャをバックボーンとして使用する場合、ロボットの身体構造によって提供される有用な情報は通常無視されます。しかし実際には、この構造情報はトランスに強力な誘導バイアスを与える可能性があります。チームは、元のアーキテクチャの表現機能を維持しながら、この情報を活用しました。
Body Transformer (BoT) アーキテクチャは、マスクされた注意に基づいています。このアーキテクチャの各層では、ノードはそれ自体とその隣接ノードに関する情報のみを参照できます。このように、情報はグラフの構造に従って流れ、上流層はローカル情報に基づいて推論を実行し、下流層はより離れたノードからよりグローバルな情報を収集します。
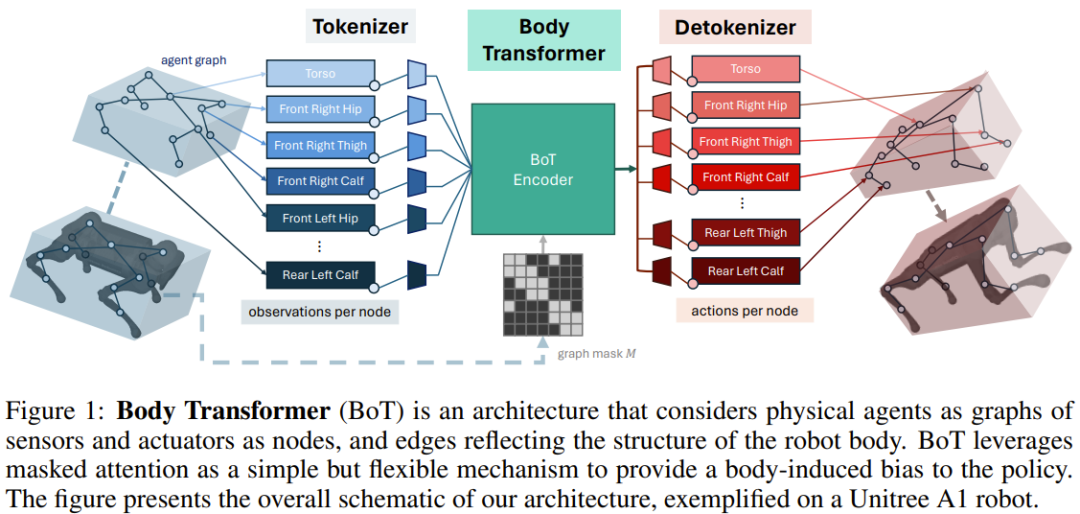
図 1 に示すように、BoT アーキテクチャには次のコンポーネントが含まれています:
1.tokenizer: センサー入力を対応するノード エンベディングに投影します。
2.Transformer エンコーダー: 入力エンベディングを処理し、出力を生成します。同じ次元の特徴;
3.detokenizer: 非トークン化、つまり特徴をアクション (または強化学習の批判トレーニングに使用される値) にデコードします。
トークナイザー
チームは、観測ベクトルをローカル観測で構成されるグラフにマッピングすることを選択しました。
実際には、グローバル量をロボット本体のルート要素に割り当て、ローカル量を対応する四肢を表すノードに割り当てます。この割り当ては、以前の GNN メソッドと似ています。
次に、線形層を使用して、ローカル状態ベクトルを埋め込みベクトルに投影します。各ノードの状態は、そのノード固有の学習可能な線形射影に入力され、その結果、n 個の埋め込みのシーケンスが生成されます。ここで、n はノード数 (またはシーケンスの長さ) を表します。これは、通常、マルチタスク強化学習でさまざまな数のノードを処理するために単一の共有学習可能な線形射影のみを使用する以前の研究とは異なります。
BoT エンコーダー
チームが使用するバックボーン ネットワークは標準のマルチレイヤー Transformer エンコーダーであり、このアーキテクチャには 2 つのバリエーションがあります:
BoT-Hard: グラフの構造を反映するバイナリ マスクを使用して各レイヤーをマスクします。具体的には、マスクの構築方法は M = I_n + A です。ここで、I_n は n 次元単位行列、A はグラフに対応する隣接行列です。図 2 に例を示します。これにより、各ノードは自分自身とそのすぐ隣のノードだけを見ることができ、問題にかなりのスパース性を導入することができます。これは、計算コストの観点から特に魅力的です。
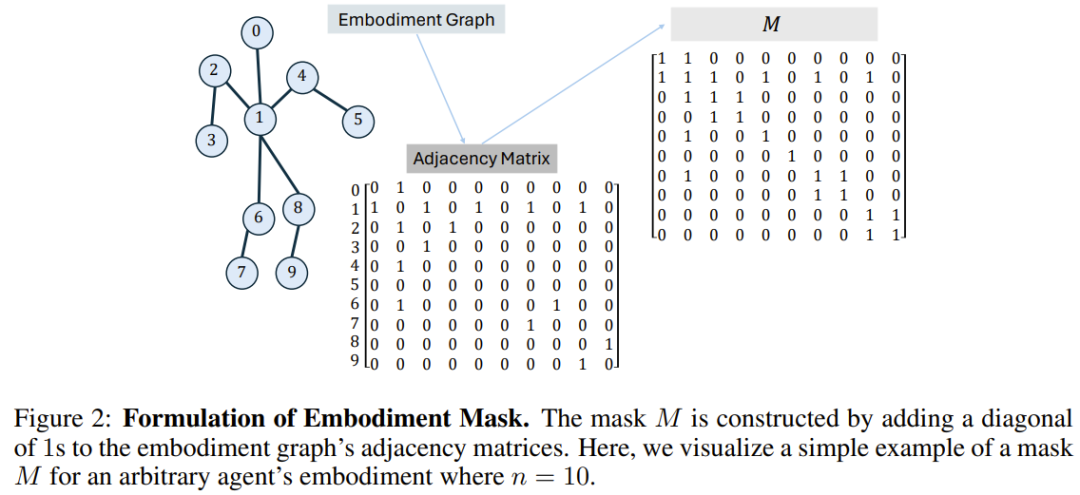
BoT-Mix: マスクされたアテンション (BoT-Hard など) を持つレイヤーとマスクされていないアテンションを持つレイヤーを織り交ぜます。
detokenizer
Transformer エンコーダーによって出力された特徴は線形層に供給され、ノードのリムに関連付けられたアクションに投影されます。これらのアクションは、対応するアクチュエーターのリムへの近接性に基づいて割り当てられます。 。繰り返しますが、これらの学習可能な線形投影レイヤーはノードごとに別個です。 BoT が強化学習設定の重要なアーキテクチャとして使用されている場合、デトークナイザーはアクションではなく値を出力し、その値が身体部分全体で平均化されます。
実験
チームは、模倣学習および強化学習設定における BoT のパフォーマンスを評価しました。図 1 と同じ構造を維持し、エンコーダの有効性を判断するために BoT エンコーダをさまざまなベースライン アーキテクチャに置き換えただけです。
これらの実験の目的は、次の質問に答えることです:
マスクされた注意は模倣学習のパフォーマンスと汎化能力を向上させることができますか?
元の Transformer アーキテクチャと比較して、BoT はプラスのスケーリング傾向を示すことができますか?
BoT は強化学習フレームワークと互換性がありますか? パフォーマンスを最大化するための合理的な設計の選択肢は何ですか?
BoT 戦略は現実世界のロボットタスクに適用できますか?
マスクされた注意の計算上の利点は何ですか?
模倣学習実験
チームは、MoCapAct データセットを通じて定義された身体追跡タスクにおける BoT アーキテクチャの模倣学習パフォーマンスを評価しました。
結果は図 3a に示されており、BoT は常に MLP および Transformer のベースラインよりも優れたパフォーマンスを示していることがわかります。これらのアーキテクチャに対する BoT の利点は、目に見えない検証ビデオ クリップでさらに増大することは注目に値します。これは、身体認識誘導バイアスが汎化機能の向上につながる可能性があることを証明しています。
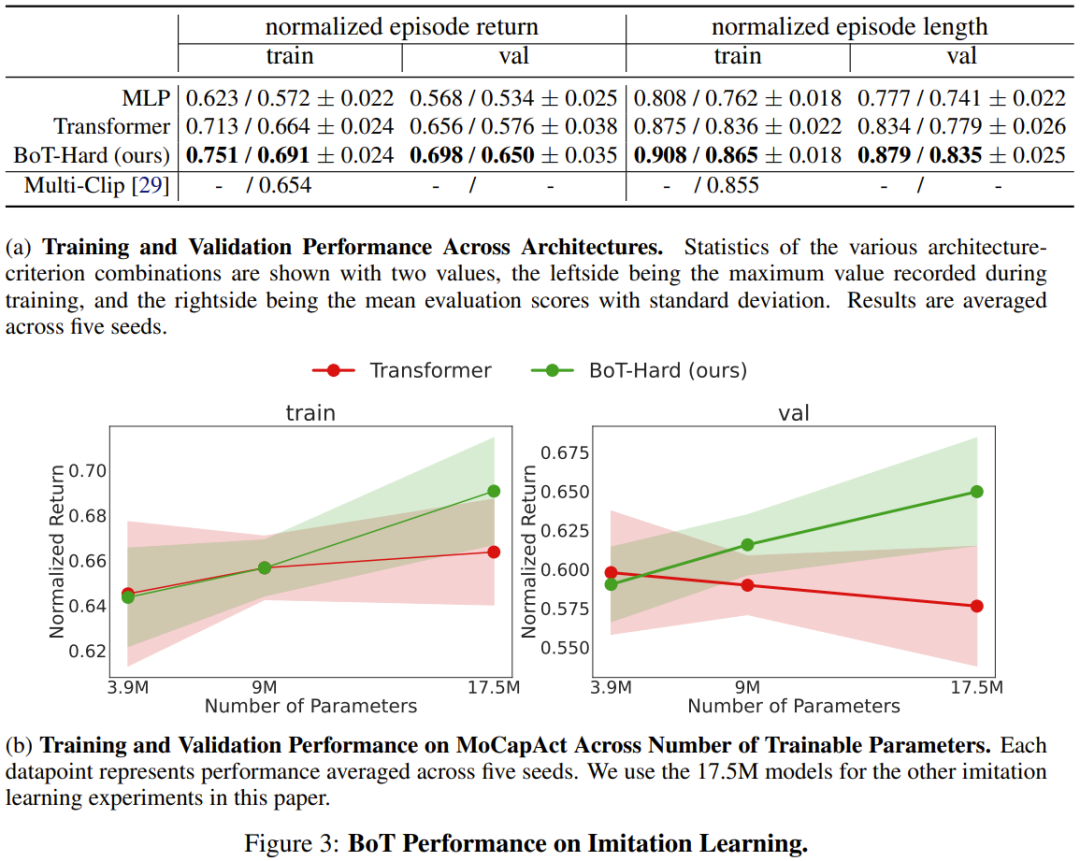
そして、図 3b は、Transformer ベースラインと比較して、トレーニングおよび検証ビデオ クリップの両方のパフォーマンスが向上し、トレーニング可能なパラメーターの数が増加する傾向があることを示しています。トレーニング データを過学習させますが、この過学習は実施形態のバイアスによって引き起こされます。さらなる実験例を以下に示します。詳細については元の論文を参照してください。


強化学習実験
チームは、Isaac Gym での 4 つのロボット制御タスクにおける BoT の強化学習パフォーマンスと、PPO を使用したベースラインを評価しました。 4 つのタスクは、Humanoid-Mod、Humanoid-Board、Humanoid-Hill、および A1-Walk です。
図 5 は、MLP、Transformer、BoT (ハードおよびミックス) のトレーニング中の評価ロールアウトの平均プロット リターンを示しています。ここで、実線は平均値に対応し、影付きの領域は 5 つのシードの標準誤差に対応します。
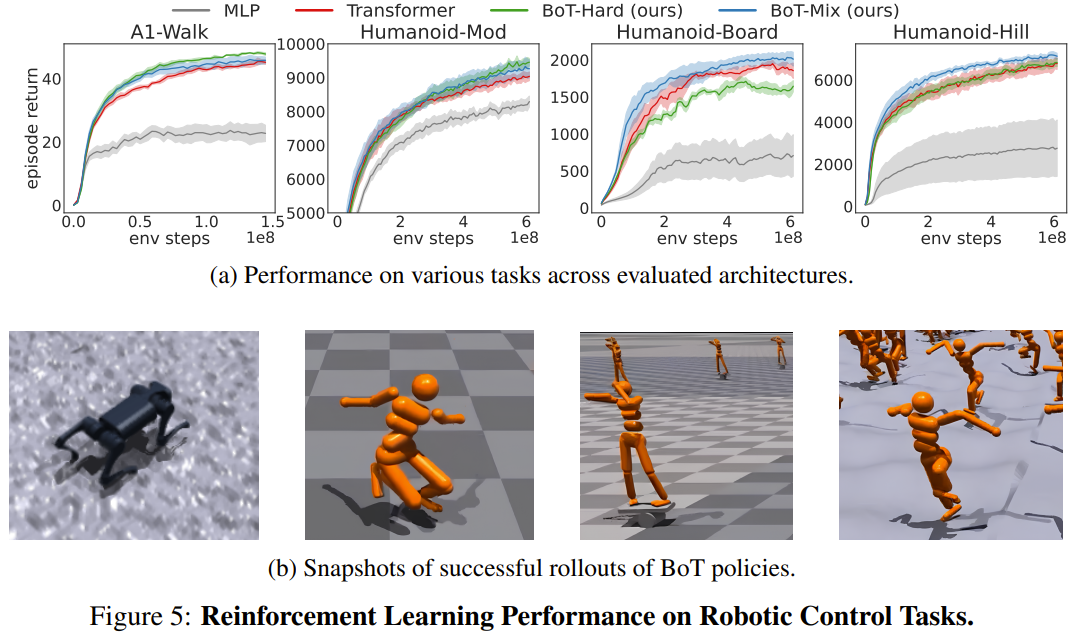

結果は、サンプル効率と漸近パフォーマンスの点で、BoT-Mix が MLP およびオリジナルの Transformer ベースラインよりも一貫して優れていることを示しています。これは、ロボット本体からのバイアスをポリシー ネットワーク アーキテクチャに統合することの有用性を示しています。
一方、BoT-Hard は、単純なタスク (A1-Walk および Humanoid-Mod) では元の Transformer よりも優れたパフォーマンスを発揮しますが、より困難な探索タスク (Humanoid-Board および Humanoid-Hill) ではパフォーマンスが低下します。マスクされた注意が遠くの体の部分からの情報の伝播を妨げることを考えると、BoT-Hard の情報通信における強い制限は、強化学習探索の効率を妨げる可能性があります。
現実世界での実験
Persekitaran sukan simulasi Isaac Gym sering digunakan untuk memindahkan strategi pembelajaran pengukuhan daripada persekitaran maya kepada persekitaran sebenar tanpa memerlukan pelarasan dunia sebenar. Untuk mengesahkan sama ada seni bina yang baru dicadangkan sesuai untuk aplikasi dunia sebenar, pasukan itu menggunakan dasar BoT yang dilatih di atas kepada robot Unitree A1. Seperti yang anda boleh lihat daripada video di bawah, seni bina baharu boleh digunakan dengan pasti dalam penggunaan dunia sebenar.

Analisis Pengiraan
Pasukan juga menganalisis kos pengiraan seni bina baharu, seperti ditunjukkan dalam Rajah 6. Keputusan penskalaan perhatian bertopeng yang baru dicadangkan dan perhatian konvensional pada panjang jujukan yang berbeza (bilangan nod) diberikan di sini.
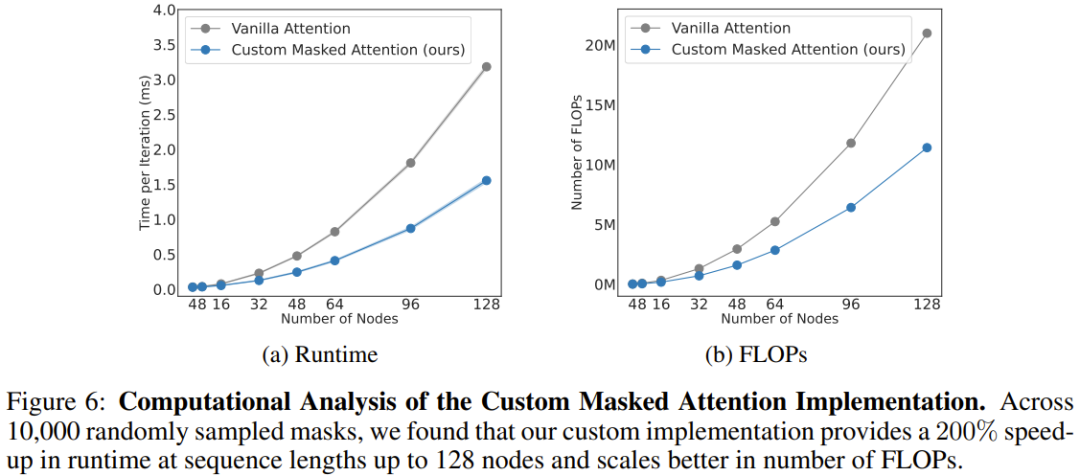
Dapat dilihat apabila terdapat 128 nod (bersamaan dengan robot humanoid dengan lengan yang tangkas), perhatian baru boleh meningkatkan kelajuan sebanyak 206%.
Secara keseluruhannya, ini menunjukkan bahawa berat sebelah terbitan badan dalam seni bina BoT bukan sahaja meningkatkan prestasi keseluruhan ejen fizikal, tetapi juga mendapat manfaat daripada penyamaran secara semula jadi jarang dari seni bina. Kaedah ini boleh mengurangkan masa latihan algoritma pembelajaran dengan ketara melalui selari yang mencukupi.
以上がロボット戦略学習のゲームチェンジャー?バークレーはボディトランスフォーマーを提案の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。





























![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



