


大きなモデルは、現実世界についての独自の理解を形成することができます!
MIT の研究によると、モデルの能力が高まるにつれて、現実の理解は単純な模倣を超える可能性があります。
たとえば、大きなモデルが匂いを嗅いだことがない場合、それは匂いを理解できないことを意味しますか?
研究により、理解を容易にするためにいくつかの概念を自発的にシミュレートできることが判明しました。
この研究は、将来、大規模モデルが言語と世界をより深く理解できるようになると期待されていることを意味します。この論文は、トップカンファレンスICML 24に採択されました。

この論文の著者は、中国人の博士課程学生 Charles Jin と、その指導教員である MIT コンピュータ人工知能研究所 (CSAIL) の Martin Rinard 教授です。
この研究では、著者は大規模なモデルにコードテキストのみを学習するように依頼したところ、モデルがその背後にある意味を徐々に理解していることがわかりました。
リナード教授は、この研究は現代の人工知能の中核となる問題に直接取り組んでいると述べました -
大規模モデルの能力は単に大規模な統計的相関によるものなのか、それともモデルが扱う現実の問題の有意義な理解を生み出すのかと? ?
△出典:MIT公式ウェブサイト
同時に、この研究は多くの議論を引き起こしました。
一部のネチズンは、大型モデルは人間とは異なる言語理解をするかもしれないが、この研究は少なくともモデルが訓練データを記憶するだけではないことを示していると述べた。

大規模モデルに純粋なコードを学習させましょう
大規模モデルが意味レベルの理解を生み出すことができるかどうかを調査するために、著者はプログラム コードとそれに対応する入力と出力で構成される合成データ セットを構築しました。
これらのコード プログラムは、Karel と呼ばれる教育言語で書かれており、主に 2D グリッド世界でナビゲートするロボットのタスクを実装するために使用されます。
このグリッドの世界は 8x8 のグリッドで構成されており、各グリッドには障害物、マーカー、またはオープン スペースを含めることができます。ロボットはグリッド間を移動し、マーカーの配置/ピックアップなどの操作を実行できます。
カレル言語には、move (1 歩進む)、turnLeft (左に 90 度回転)、turnRight (右に 90 度回転)、pickMarker (マーカーを拾う)、putMarker (マーカーを配置) の 5 つの原始操作が含まれており、プログラムは次で構成されます。これらの原始的な操作のシーケンス。
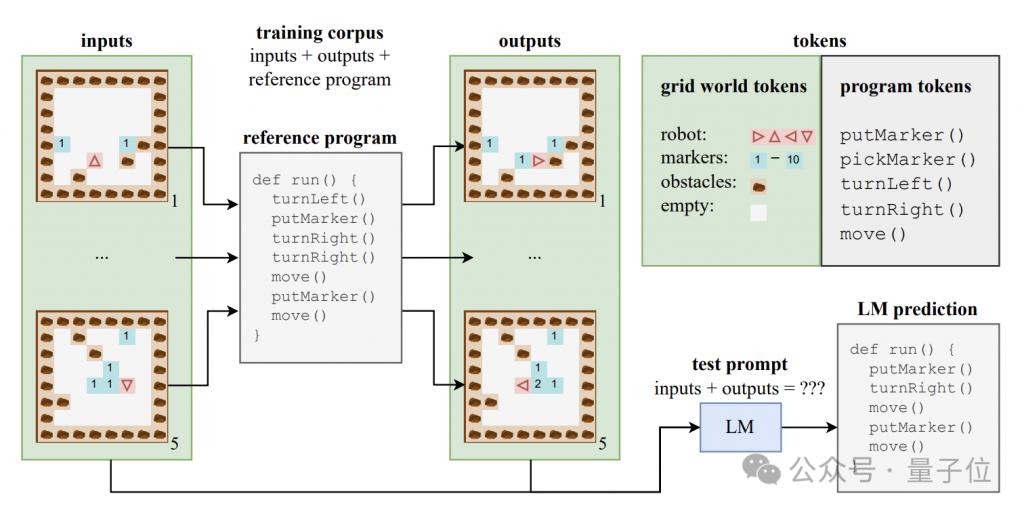
著者は、500,000 のカレル プログラムを含むトレーニング セットをランダムに生成し、各プログラムの長さは 6 ~ 10 でした。
各トレーニング サンプルは、5 つの入力状態、5 つの出力状態、および完全なプログラム コードの 3 つの部分で構成されます。入力状態と出力状態は特定の形式の文字列にエンコードされます。
このデータを使用して、著者らは標準の Transformer アーキテクチャの CodeGen モデルのバリアントをトレーニングしました。
トレーニング プロセス中、モデルは各サンプルの入出力情報とプログラム プレフィックスにアクセスできますが、プログラム実行の完全な軌跡と中間状態を確認することはできません。
トレーニング セットに加えて、著者はモデルの汎化パフォーマンスを評価するために 10,000 個のサンプルを含むテスト セットも構築しました。
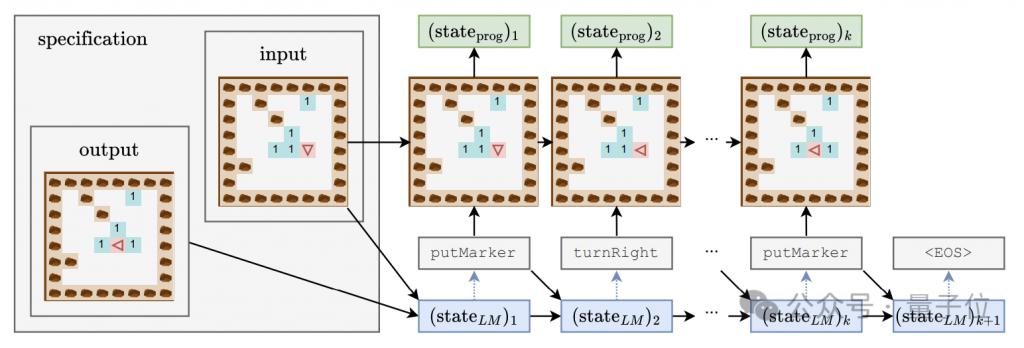
言語モデルがコードの背後にあるセマンティクスを把握しているかどうかを研究し、同時にモデルの「思考プロセス」を深く理解するために、著者は線形分類器と単一/二重隠れ層MLP。
検出器の入力はプログラムトークンの生成過程における言語モデルの隠れた状態であり、予測ターゲットはプログラム実行の中間状態であり、特にロボットの向き(方向)、初期位置に対するオフセットを含みます。 (位置)、障害物に正面を向いているか(障害物)、この3つの特徴です。
生成モデルのトレーニング プロセス中、著者は 4000 ステップごとに上記 3 つの特徴を記録し、検出器のトレーニング データ セットを形成するために生成モデルの隠れた状態も記録しました。
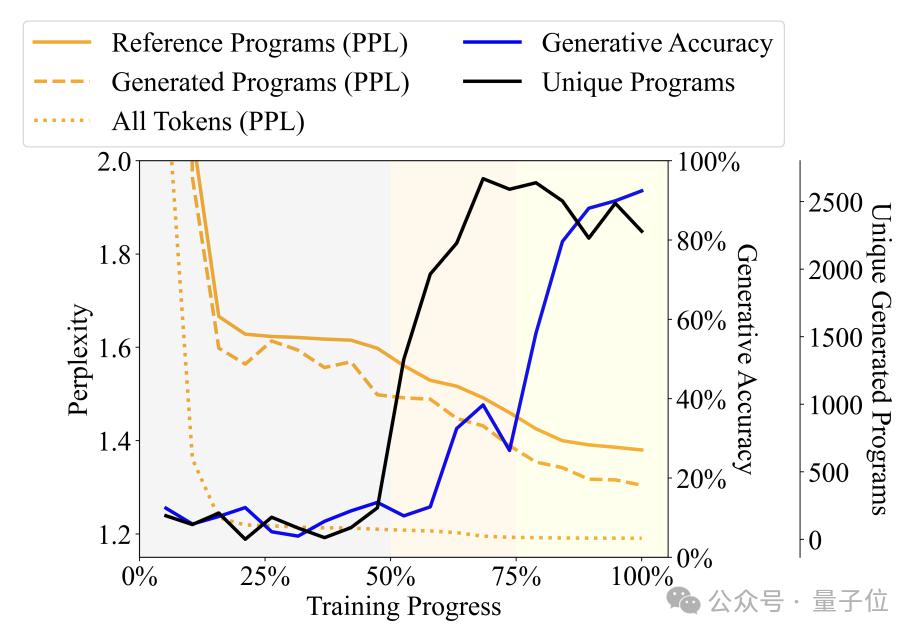
大規模モデル学習の 3 段階
言語モデルによって生成されたプログラムの多様性、複雑さ、その他の指標の変化をトレーニング プロセスとともに観察することにより、著者はトレーニング プロセスを 3 つの段階に分割しました -
せせらぎ (ナンセンス) ステージ: 出力プログラムの反復性が高く、検出器の精度が不安定です。
文法習得段階: プログラムの多様性が急速に増加し、生成精度がわずかに増加し、混乱が減少します。これは、言語モデルがプログラムの構文構造を学習したことを示しています。
意味の獲得段階: プログラムの多様性と構文構造の習熟度は安定していますが、生成精度と検出器のパフォーマンスは大幅に向上しており、言語モデルがプログラムの意味を学習していることを示しています。
具体的には、喃語段階はトレーニング プロセス全体の最初の 50% を占めます。たとえば、トレーニングが約 20% に達すると、どのような仕様が入力されても、モデルは固定プログラム (「pickMarker」を 9 回繰り返す) のみを生成します。 。
文法習得段階はトレーニング プロセスの 50% から 75% にあり、カレル プログラムにおけるモデルの複雑さは大幅に低下しています。これは、言語モデルがカレル プログラムの統計的特性によりよく適応し始めていることを示しています。生成されたプログラムの精度はそれほど向上していません (約 10% から約 25%) が、依然としてタスクを正確に完了できません。
セマンティック獲得段階は、プログラムの精度が約 25% から 90% 以上に大幅に向上しました。
さらなる実験により、検出器は時刻 t における同時タイム ステップを予測できるだけでなく、後続のタイム ステップのプログラム実行ステータスも予測できることがわかりました。
たとえば、生成モデルが時間 t にトークン「move」を生成し、時間 t+1 に「turnLeft」を生成すると仮定します。
同時に、時間 t でのプログラムの状態は、ロボットが北を向いており、座標 (0,0) に位置していることですが、時間 t+1 では、ロボットは西を向いていることになります。順位は変わらず。
検出器が時刻 t の言語モデルの隠れ状態から、ロボットが時刻 t+1 に西を向くことをうまく予測できた場合、それは、「turnLeft」を生成する前に、隠れ状態に既にこの効果が含まれていることを意味します。操作ステータス変更情報。
この現象は、モデルが生成されたプログラム部分の意味を理解しているだけでなく、生成の各ステップで、次に生成されるコンテンツをすでに予測および計画しており、予備的な未来志向の推論スキルを示していることを示しています。
しかし、この発見はこの研究に新たな疑問をもたらしました -
実験で観察された精度の向上は本当に生成モデルの向上なのか、それとも検出器自身の推論の結果なのでしょうか?
この疑問を解決するために、著者は意味検出介入実験を追加しました。
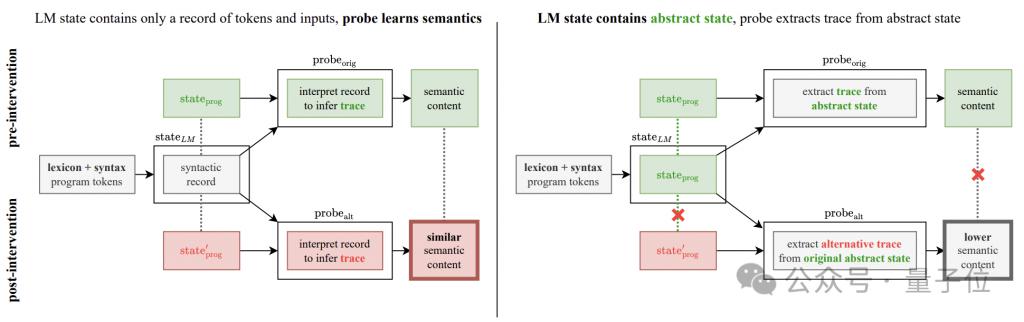
実験の基本的な考え方は、プログラム操作の意味解釈ルールを変更することであり、「反転」と「敵対的」の2つの方法に分けられます。
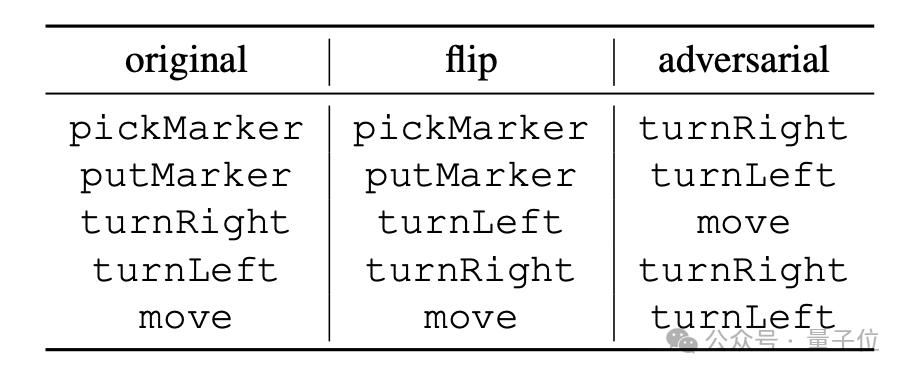
「flip」は命令の意味を強制的に反転します。たとえば、「turnRight」は「turn left」と強制的に解釈されます。ただし、この種の反転を実行できるのは「turnLeft」と「turnRight」だけです。 「敵対的」は強制することです。 以下の表に示すように、すべての命令に対応するセマンティクスがランダムにシャッフルされます。
 生成モデルの隠れ状態が意味情報ではなくプログラムの構文構造のみをエンコードしている場合でも、検出器は同じパフォーマンスで隠れ状態から変更された意味情報を抽出できるはずです。
生成モデルの隠れ状態が意味情報ではなくプログラムの構文構造のみをエンコードしている場合でも、検出器は同じパフォーマンスで隠れ状態から変更された意味情報を抽出できるはずです。
逆に、検出器のパフォーマンスが大幅に低下した場合、検出器によって示されたパフォーマンスの向上は、生成モデルの隠れ状態が実際のセマンティクスをエンコードしているためであることを意味します。
実験結果は、両方の新しいセマンティクスの下で検出器のパフォーマンスが大幅に低下することを示しています。
「敵対的」モードでは特により顕著であり、これは、このモードのセマンティクスが元のセマンティクスと大幅に異なるという特徴とも一致します。
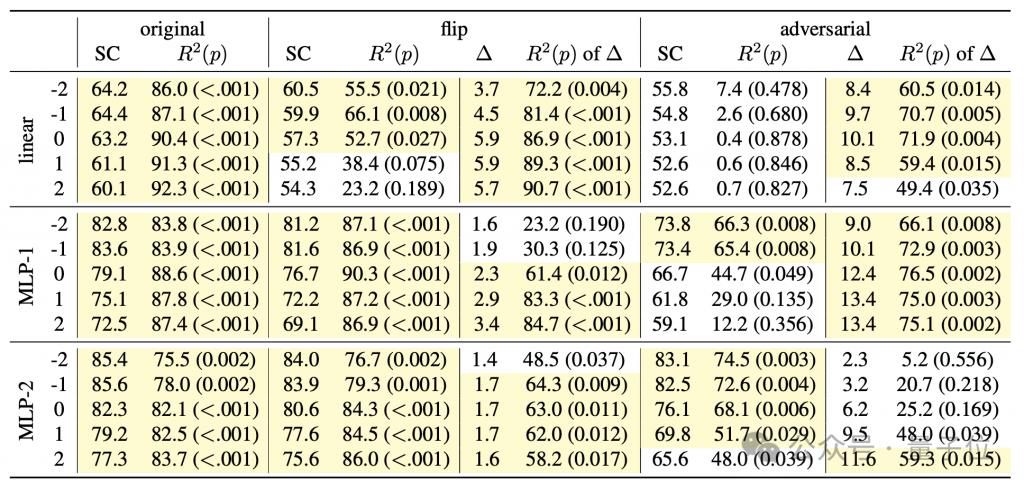 これらの結果は、検出器が「意味論的マッピングを自ら学習する」可能性を強く排除し、生成モデルが実際にコードの意味を把握していることをさらに裏付けています。
これらの結果は、検出器が「意味論的マッピングを自ら学習する」可能性を強く排除し、生成モデルが実際にコードの意味を把握していることをさらに裏付けています。
論文アドレス:
https://icml.cc/virtual/2024/poster/34849
参考リンク:
[ 1 ] https://news.mit.edu/2024/llms-develop-own-言語能力としての現実理解改善-0814
[ 2 ] https://www.reddit.com/r/LocalLLaMA/comments/1esxkin/llms_develop_their_own_ Understanding_of_reality/
以上が大きなモデルは独自の言語を理解しています。 MITの論文で大規模モデルの「思考プロセス」が明らかにの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。





























![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



