


小型モデルの台頭。
先月、Meta は Llama 3.1 シリーズのモデルをリリースしました。これには、Meta のこれまでで最大のモデルである 405B と 2 つの小型モデルが含まれます。パラメータの量はそれぞれ 700 億と 80 億です。
Llama 3.1 は、オープンソースの新時代の到来を告げるものと考えられています。ただし、新世代モデルはパフォーマンスが強力ですが、導入時には依然として大量のコンピューティング リソースが必要です。
したがって、業界では別の傾向が現れています。それは、多くの言語タスクで十分なパフォーマンスを発揮し、導入が非常に安価な小規模言語モデル (SLM) を開発することです。
最近、NVIDIA の研究により、構造化された重み枝刈りと知識の蒸留を組み合わせることで、最初は大きなモデルから徐々に小さな言語モデルを取得できることが示されました。 # ##### ## ## ## ## #、Meta のチーフ AI サイエンティストである Jann LECun 氏もこの研究を賞賛しました。

Llama-3.1-Minitron 4B は、Minitron 4B、Phi-2 2.7B、Gemma2 2.6B、Qwen2-1.5B など、同様のサイズの最先端のオープンソース モデルよりも優れたパフォーマンスを発揮します。
この研究の関連論文は先月早くも発表されました。

紙のリンク: https://www.arxiv.org/pdf/2407.14679
# # 論文タイトル: 剪定と知識の蒸留によるコンパクト言語モデル
論文タイトル: 剪定と知識の蒸留によるコンパクト言語モデル
NVIDIA では、枝刈りと古典的な知識の抽出を組み合わせた方法を使用して大規模なモデルを構築しています。次の図は、単一モデルの枝刈りおよび抽出のプロセス (上) とモデルの枝刈りおよび抽出のチェーンを示しています (下)。 )。具体的なプロセスは次のとおりです:
1. NVIDIA は 15B モデルから開始し、各コンポーネント (レイヤー、ニューロン、ヘッド、エンベディング チャネル) の重要性を評価し、モデルをソートおよびプルーニングして作成します。目標サイズに達しました: 8B モデル。 2 次に、元のモデルを教師、枝刈りしたモデルを生徒として、モデル蒸留を使用して軽い再トレーニングを実行しました。 3. トレーニング後、小さいモデル (8B) を開始点として取り、それを枝刈りしてより小さい 4B モデルに蒸留します。 ### ## 注意すべき点は、モデルを枝刈りする前に、モデルのどの部分が重要であるかを理解する必要があるということです。 NVIDIA は、1024 サンプルの小さなキャリブレーション データセットを使用して、関連するすべての次元 (深度、ニューロン、ヘッド、埋め込みチャネル) の情報を同時に計算する、アクティベーション ベースの純粋な重要性評価戦略を提案しています。必要なのは順方向伝播のみです。このアプローチは、勾配情報に依存しバックプロパゲーションを必要とする戦略よりもシンプルでコスト効率が高くなります。 枝刈り中、特定の軸または軸の組み合わせについて枝刈りと重要度推定を繰り返し交互に行うことができます。実証研究では、単一の重要度推定値を使用するだけで十分であり、反復推定では追加の利点がもたらされないことが示されています。古典知識の蒸留を用いた再トレーニング
Figure 2 below shows the distillation process, where the N-layer student model (the pruned model) is distilled from the M-layer teacher model (the original unpruned model). The student model is learned by minimizing a combination of embedding output loss, logit loss, and Transformer encoder-specific losses mapped to student blocks S and teacher blocks T. Figure 2: Distillation training loss.

Best practices for pruning and distillationNVIDIA pruning and knowledge distillation based on compact language model Based on extensive ablation research, I summarized my learning results into the following structured compression best practices.
The first is to adjust the size.To train a set of LLMs, the largest one is trained first, and then iteratively pruned and distilled to obtain smaller LLMs. If a multi-stage training strategy is used to train the largest model, it is best to prune and retrain the model obtained in the last stage of training.
# # teacher fine-tuning
Depth-only pruning
Width-only pruning
Accuracy Benchmark
Performance Benchmark
# #teacher fine-tuning
In order to reduce from 8B to 4B, NVIDIA pruned 16 layers (50%). They first evaluate the importance of each layer or group of consecutive sub-layers by removing them from the model and observe an increase in LM loss or a decrease in accuracy in downstream tasks.
Figure 5 below shows the LM loss values on the validation set after removing 1, 2, 8 or 16 layers. For example, the red plot for layer 16 indicates the LM loss that occurs if the first 16 layers are removed. Layer 17 indicates that LM loss also occurs if the first layer is retained and layers 2 to 17 are deleted. Nvidia observes: The starting and ending layers are the most important.
Figure 5: The importance of depth-only pruning the middle layer.
However, NVIDIA observes that this LM loss is not necessarily directly related to downstream performance.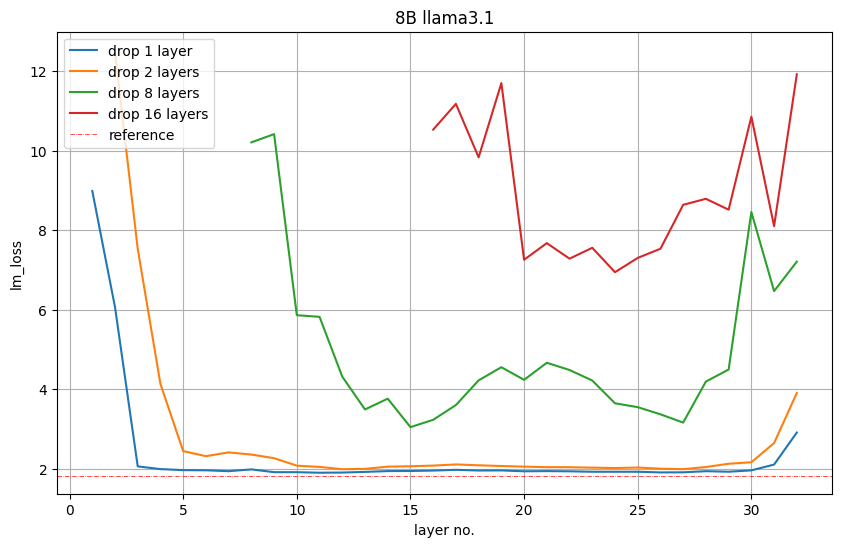
Accuracy.
 Width-only pruning
Width-only pruning
NVIDIA prunes embedding (hidden) and MLP along the width axis Intermediate dimensions to compress Llama 3.1 8B. Specifically, they use the previously described activation-based strategy to compute importance scores for each attention head, embedding channel, and MLP hidden dimension.After importance estimation, NVIDIA chose
to prune the MLP middle dimension from 14336 to 9216.
Prune hidden size from 4096 to 3072.It is worth mentioning that after single-sample pruning, the LM loss of width pruning is higher than that of depth pruning. However, after a brief retraining period, the trend reversed.
Accuracy Benchmark
NVIDIA distilled the model using the following parameters
Peak learning rate = 1e-4
Minimum learning rate = 1e-5
40 steps linear warm-up
Cosine Decay Plan
Global batch size = 1152
Table 1 below shows the Llama-3.1-Minitron 4B model variants (width pruning and depth pruning) similar to the original Llama 3.1 8B model, others Performance comparison of large and small models on benchmarks across multiple domains. Overall, NVIDIA once again confirmed the effectiveness of a wide pruning strategy compared to deep pruning that follows best practices.

Table 1: Accuracy comparison of Minitron 4B base model compared to base models of similar scale.
To verify whether the distilled model can become a powerful instruction model, NVIDIA used NeMo-Aligner to fine-tune the Llama-3.1-Minitron 4B model.
They used Nemotron-4 340B training data and evaluated on IFEval, MT-Bench, ChatRAG-Bench and Berkeley Function Calling Leaderboard (BFCL) to test instruction following, role-playing, RAG and function calling capabilities. Finally, it was confirmed that the Llama-3.1-Minitron 4B model can be a reliable instruction model, outperforming other baseline SLMs.

Table 2: Accuracy comparison of aligned Minitron 4B base model with similarly sized aligned models.
Performance Benchmarks
NVIDIA optimized the Llama 3.1 8B and Llama-3.1-Minitron 4B models using NVIDIA TensorRT-LLM, an open source toolkit for optimizing LLM inference.
The next two figures show the throughput requests per second of different models at FP8 and FP16 precision under different use cases, expressed as the input sequence length/output sequence length (ISL/OSL) combination of the batch size of 32 for the 8B model and The batch size of the 4B model is an input sequence length/output sequence length (ISL/OSL) combination of 64, thanks to the smaller weights allowing a larger batch size on an NVIDIA H100 80GB GPU.
The Llama-3.1-Minitron-4B-Depth-Base variant is the fastest, with an average throughput of about 2.7 times that of Llama 3.1 8B, while the Llama-3.1-Minitron-4B-Width-Base variant has an average throughput of Approximately 1.8 times that of Llama 3.1 8B. Deployment in FP8 also improves the performance of all three models by approximately 1.3x compared to BF16.


80GB GPU.
Conclusion
Pruning and classical knowledge refining is a very cost-effective method to progressively obtain LLMs of smaller sizes, achieving higher accuracy than training from scratch in all domains . This is a more efficient and data-efficient approach than fine-tuning on synthetic data or pre-training from scratch.
Llama-3.1-Minitron 4B is NVIDIA’s first attempt at using the state-of-the-art open source Llama 3.1 series. To use the SDG fine-tuning of Llama-3.1 with NVIDIA NeMo, see the /sdg-law-title-generation section on GitHub.
For more information, please see the following resources:
https://arxiv.org/abs/2407.14679
https://github.com/NVlabs/Minitron
https:// huggingface.co/nvidia/Llama-3.1-Minitron-4B-Width-Base
https://huggingface.co/nvidia/Llama-3.1-Minitron-4B-Depth-Base
Reference links:
https://developer.nvidia.com/blog/how-to-prune-and-distill-llama-3-1-8b-to-an-nvidia-llama-3-1-minitron-4b -model/
以上がNvidia はプルーニングと蒸留を試しています。Llama 3.1 8B のパラメータを半分にして、同じサイズでより良いパフォーマンスを実現しています。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。





























![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



