


Scrapy を使用して Web サイトをクロールすると、創造性を発揮したり、スクレイピングしようとしているページを操作したりする必要があるあらゆる種類のシナリオにすぐに遭遇します。これらのシナリオの 1 つは、無限スクロール ページをクロールする必要がある場合です。このタイプの Web サイト ページでは、ソーシャル メディア フィードのようにページを下にスクロールすると、より多くのコンテンツが読み込まれます。
この種のページをクロールする方法は間違いなく複数あります。私が最近これに取り組んだ方法の 1 つは、ページの長さが増加しなくなるまで (つまり、一番下までスクロールする) スクロールを続けることでした。この投稿では、このプロセスを段階的に説明します。
この投稿は、Scrapy プロジェクトが設定および実行されており、変更して実行できる Spider があることを前提としています。
この統合では、scrapy-playwright プラグインを使用して、Playwright for Python を Scrapy と統合します。 Playwright は、Web ページと対話してデータを抽出するために使用されるヘッドレス ブラウザ自動化ライブラリです。
私は Python パッケージのインストールと管理に uv を使用してきました。
次に、UV から直接仮想環境を使用します。
uv venv source .venv/bin/activate
次のコマンドを使用して、scrapy-playwright プラグインと Playwright を仮想環境にインストールします。
uv pip install scrapy-playwright
Playwright で使用するブラウザをインストールします。たとえば、Chromium をインストールするには、次のコマンドを実行できます:
playwright install chromium
必要に応じて、Firefox などの他のブラウザをインストールすることもできます。
注: 以下の Scrapy コードと Playwright の統合は Chromium でのみテストされています。
settings.py ファイルまたはスパイダーのcustom_settings 属性を更新して、DOWNLOAD_HANDLERS および PLAYWRIGHT_LAUNCH_OPTIONS 設定を含めます。
# settings.py
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
DOWNLOAD_HANDLERS = {
"http": "scrapy_playwright.handler.ScrapyPlaywrightDownloadHandler",
"https": "scrapy_playwright.handler.ScrapyPlaywrightDownloadHandler",
}
PLAYWRIGHT_LAUNCH_OPTIONS = {
# optional for CORS issues
"args": [
"--disable-web-security",
"--disable-features=IsolateOrigins,site-per-process",
],
# optional for debugging
"headless": False,
},
PLAYWRIGHT_LAUNCH_OPTIONS の場合、headless オプションを False に設定すると、ブラウザー インスタンスを開いてプロセスの実行を監視できます。これは、デバッグや初期スクレイパーの構築に適しています。
Web セキュリティを無効にし、オリジンを分離するために追加の引数を渡します。これは、CORS の問題があるサイトをクロールする場合に便利です。
たとえば、CORS が原因で、必要な JavaScript アセットが読み込まれなかったり、ネットワーク要求が行われなかったりする状況が考えられます。特定のページ操作 (ボタンのクリックなど) が期待どおりに機能しないが、他のすべてが期待どおりに機能する場合は、ブラウザー コンソールでエラーをチェックすることで、これをより迅速に切り分けることができます。
"PLAYWRIGHT_LAUNCH_OPTIONS": {
"args": [
"--disable-web-security",
"--disable-features=IsolateOrigins,site-per-process",
],
"headless": False,
}
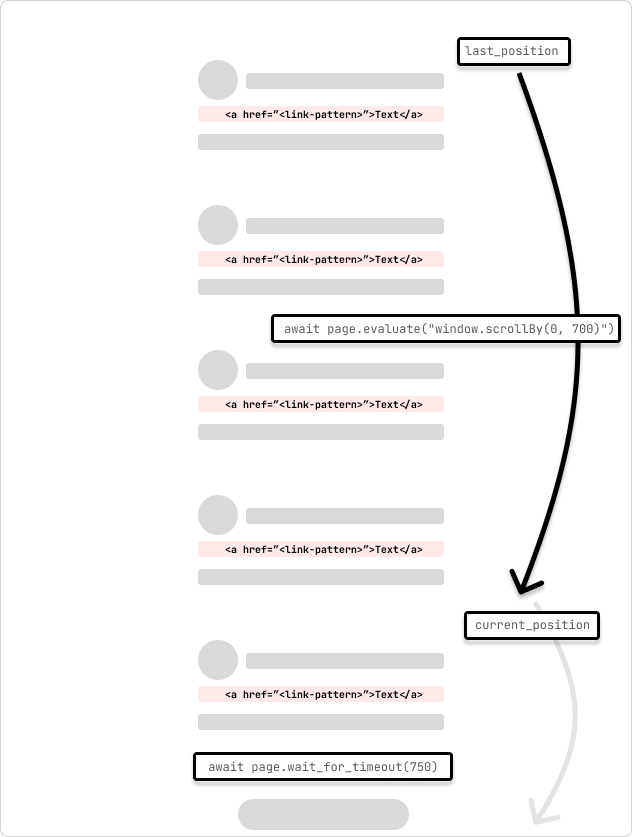
これは、無限スクロール ページをクロールするスパイダーの例です。スパイダーはページを 700 ピクセルずつスクロールし、リクエストが完了するまで 750 ミリ秒待ちます。スパイダーは、ループを通過する際にスクロール位置が変わらないことによって示されるページの一番下に到達するまでスクロールを続けます。
設定を 1 か所に保持するために、custom_settings を使用してスパイダー自体の設定を変更しています。これらの設定を settings.py ファイルに追加することもできます。
# /<project>/spiders/infinite_scroll.py
import scrapy
from scrapy.spiders import CrawlSpider
from scrapy.selector import Selector
class InfinitePageSpider(CrawlSpider):
"""
Spider to crawl an infinite scroll page
"""
name = "infinite_scroll"
allowed_domains = ["<allowed_domain>"]
start_urls = ["<start_url>"]
custom_settings = {
"TWISTED_REACTOR": "twisted.internet.asyncioreactor.AsyncioSelectorReactor",
"DOWNLOAD_HANDLERS": {
"https": "scrapy_playwright.handler.ScrapyPlaywrightDownloadHandler",
"http": "scrapy_playwright.handler.ScrapyPlaywrightDownloadHandler",
},
"PLAYWRIGHT_LAUNCH_OPTIONS": {
"args": [
"--disable-web-security",
"--disable-features=IsolateOrigins,site-per-process",
],
"headless": False,
},
"LOG_LEVEL": "INFO",
}
def start_requests(self):
yield scrapy.Request(
url=f"{self.start_urls[0]}",
meta=dict(
playwright=True,
playwright_include_page=True,
),
callback=self.parse,
)
async def parse(
self,
response,
):
page = response.meta["playwright_page"]
page.set_default_timeout(10000)
await page.wait_for_timeout(5000)
try:
last_position = await page.evaluate("window.scrollY")
while True:
# scroll by 700 while not at the bottom
await page.evaluate("window.scrollBy(0, 700)")
await page.wait_for_timeout(750) # wait for 750ms for the request to complete
current_position = await page.evaluate("window.scrollY")
if current_position == last_position:
print("Reached the bottom of the page.")
break
last_position = current_position
except Exception as error:
print(f"Error: {error}")
pass
print("Getting content")
content = await page.content()
print("Parsing content")
selector = Selector(text=content)
print("Extracting links")
links = selector.xpath("//a[contains(@href, '/<link-pattern>/')]//@href").getall()
print(f"Found {len(links)} links...")
print("Yielding links")
for link in links:
yield {"link": link}
私が学んだことの 1 つは、2 つのページやサイトは同じではないため、ページと、ページへのリクエストのネットワーク往復の遅延を考慮して、スクロール量と待ち時間を調整する必要がある場合があるということです。完了。スクロール位置とリクエストが完了するまでにかかる時間を確認することで、これをプログラムで動的に調整できます。
ページの読み込みでは、アセットが読み込まれてページがレンダリングされるまで少し長く待機します。 Playwright ページは、response.meta オブジェクトの parse コールバック メソッドに渡されます。これは、ページを操作したり、ページをスクロールしたりするために使用されます。これは、scrapy.Request 引数で playwright=True および playwright_include_page=True オプションを使用して指定されます。
def start_requests(self):
yield scrapy.Request(
url=f"{self.start_urls[0]}",
meta=dict(
playwright=True,
playwright_include_page=True,
),
callback=self.parse,
)
このスパイダーは、page.evaluate とScrollBy() JavaScript メソッドを使用してページを 700 ピクセルずつスクロールし、リクエストが完了するまで 750 ミリ秒待ちます。次に、Playwright ページのコンテンツが Scrapy セレクターにコピーされ、ページからリンクが抽出されます。その後、リンクは Scrapy パイプラインに渡されて処理を続行します。
ページリクエストが重複したコンテンツの読み込みを開始する状況では、コンテンツがすでに読み込まれているかどうかを確認するチェックを追加して、ループから抜け出すことができます。または、スクロールのロード数がわかっている場合は、一定数のスクロールにバッファーを加えた後にループから抜け出すカウンターを追加できます。
It's also possible that the page may have an element that you can scroll to (i.e. "Load more") that will trigger the next set of content to load. You can use the page.evaluate method to scroll to the element and then click it to load the next set of content.
...
try:
while True:
button = page.locator('//button[contains(., "Load more")]')
await button.wait_for()
if not button:
print("No 'Load more' button found.")
break
is_disabled = await button.is_disabled()
if is_disabled:
print("Button is disabled.")
break
await button.scroll_into_view_if_needed()
await button.click()
await page.wait_for_timeout(750)
except Exception as error:
print(f"Error: {error}")
pass
...
This method is useful when you know the page has a button that will load the next set of content. You can also use this method to click on other elements that will trigger the next set of content to load. The scroll_into_view_if_needed method will scroll the button or element into view if it is not already visible on the page. This is one of those scenarios when you will want to double-check the page actions with headless=False to see if the button is being clicked and the content is being loaded as expected before running a full crawl.
Note: As mentioned above, confirm that the page assets(.js) are loading correctly and that the network requests are being made so that the button (or element) is mounted and clickable.
Web crawling is a case-by-case scenario and you will need to adjust the code to fit the page that you are trying to scrape. The above code is a starting point to get you going with crawling infinite scroll pages with Scrapy and Playwright.
Hopefully, this helps to get you unblocked! ?
Subscribe to get my latest content by email -> Newsletter
以上がScrapy と Playwright を使用した無限スクロールによるページのクロールの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



