Llama 3.1がついに登場しましたが、ソースはMeta公式ではありません。 今日、新しいLlama大型モデルのリークのニュースがRedditで話題になりましたベースモデルに加えて、8B、70B、最大パラメータ405Bのベンチマーク結果も含まれています。 
下の図は、OpenAI GPT-4oを使用したLlama 3.1とLlama 3 8B/70Bの各バージョンの比較結果を示しています。ご覧のとおり、70B バージョンでも複数のベンチマークで GPT-4o を上回っています。 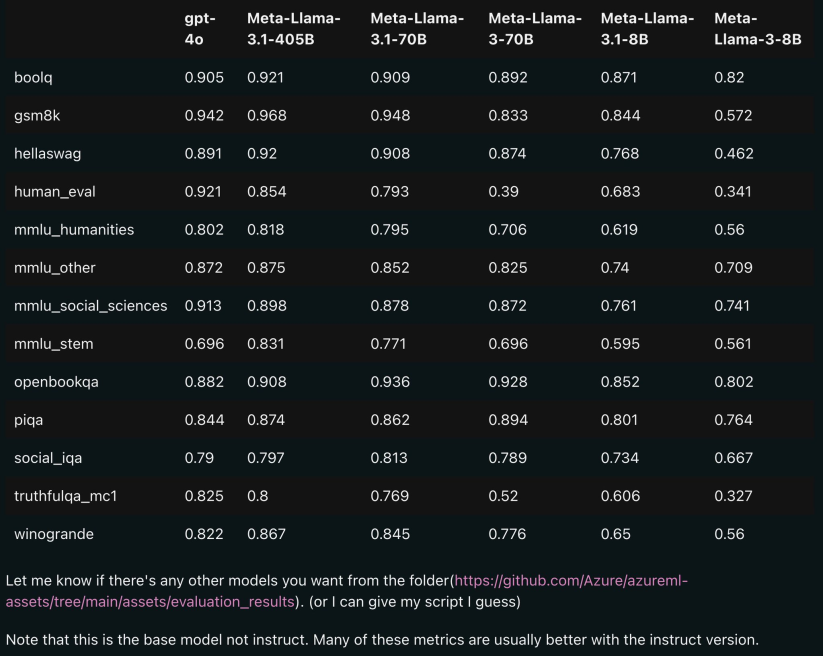
バージョン 3.1 の 8B および 70B モデルは 405B から派生したものであるため、前世代と比較してパフォーマンスが大幅に向上しました。
一部のネチズンは、オープンソース モデルが GPT4o や Claude Sonnet 3.5 などのクローズド ソース モデルを超え、複数のベンチマークで SOTA に到達したのはこれが初めてだと述べています。
同時に、Llama 3.1のモデルカードがリークされ、その詳細がリークされました(モデルカードに記された日付は、7月23日のリリースに基づいていることを示しています)。
誰かが次のハイライトを要約しました:
モデルはトレーニングに公開ソースからの15T以上のトークンを使用し、事前トレーニングデータの期限は2023年12月です
微調整データには公開データが含まれます。利用可能な命令微調整データセット (Llama 3 とは異なります) と 1,500 万の合成サンプル
-
モデルは、英語、フランス語、ドイツ語、ヒンディー語、イタリア語、ポルトガル語、スペイン語、タイ語を含む複数の言語をサポートしています。 ineedリークされたGitHubリンクは現在404ですが、一部のネチズンはダウンロードリンクを提供しています(ただし、安全のために、今夜の公式チャネルの発表を待つことをお勧めします):
-
しかし、これは結局のところ 1000 億レベルのモデルです。ダウンロードする前に十分なハードディスク容量を準備してください:
以下は Llama 3.1 モデルです。カード内の重要な内容:

Meta Llama 3.1 多言語大規模言語モデル (LLM) コレクションは、事前トレーニングされ、命令が微調整された生成モデルのセットで、それぞれのサイズは 8B、70B、および 405B (テキスト入力/テキスト出力) です。 Llama 3.1 コマンドで微調整されたテキスト専用モデル (8B、70B、405B) は、多言語会話のユースケース向けに最適化されており、一般的な業界ベンチマークにおいて、利用可能な多くのオープンおよびクローズドソース チャット モデルよりも優れたパフォーマンスを発揮します。  モデル アーキテクチャ: Llama 3.1 は、最適化された Transformer アーキテクチャの自己回帰言語モデルです。微調整されたバージョンでは、SFT と RLHF を使用して、使いやすさとセキュリティの設定を調整します。
モデル アーキテクチャ: Llama 3.1 は、最適化された Transformer アーキテクチャの自己回帰言語モデルです。微調整されたバージョンでは、SFT と RLHF を使用して、使いやすさとセキュリティの設定を調整します。
 サポートされている言語: 英語、ドイツ語、フランス語、イタリア語、ポルトガル語、ヒンディー語、スペイン語、タイ語。
サポートされている言語: 英語、ドイツ語、フランス語、イタリア語、ポルトガル語、ヒンディー語、スペイン語、タイ語。
モデルカード情報から、
Llama 3.1 シリーズモデルのコンテキスト長は 128k であると推測できます。すべてのモデル バージョンでは、グループ化クエリ アテンション (GQA) を使用して推論のスケーラビリティを向上させています。

使用目的。 Llama 3.1 は、多言語のビジネス アプリケーションと研究を目的としています。命令調整されたテキストのみのモデルはアシスタントのようなチャットに適していますが、事前トレーニングされたモデルはさまざまな自然言語生成タスクに適応できます。 Llama 3.1 モデル セットは、合成データの生成や蒸留など、モデル出力を活用して他のモデルを改善する機能もサポートしています。 Llama 3.1 コミュニティ ライセンスでは、これらの使用例が許可されています。 Llama 3.1 は、サポートされている 8 つの言語よりも幅広い言語セットをトレーニングします。開発者は、Llama 3.1 コミュニティ ライセンス契約および利用規定に準拠することを条件として、サポートされている 8 言語以外の言語に合わせて Llama 3.1 モデルを微調整することができ、そのような場合には他の言語が確実に使用されるようにする責任があります。安全かつ責任ある方法 言語ラマ 3.1。 ソフトウェアとハードウェアのインフラストラクチャ 1 つ目はトレーニング要素で、Llama 3.1 は事前トレーニング用にカスタム トレーニング ライブラリ、メタカスタマイズされた GPU クラスター、実稼働インフラストラクチャを使用し、さらに微調整されています。実稼働インフラストラクチャ、注釈および評価。 2 つ目は、Llama 3.1 トレーニングでは、H100-80GB (TDP は 700W) タイプのハードウェアで合計 3930 万 GPU 時間の計算を使用します。ここで、トレーニング時間は各モデルのトレーニングに必要な合計 GPU 時間、消費電力は電力効率を考慮して調整された各 GPU デバイスのピーク電力容量です。 温室効果ガス排出に関するトレーニング。地理的ベースラインに基づくラマ 3.1 訓練期間中の温室効果ガス総排出量は、11,390 トン CO2e と推定されます。 2020 年以来、メタは世界的な事業全体で温室効果ガス排出量ネットゼロを維持し、電力使用の 100% を再生可能エネルギーで賄い、その結果、研修期間中の市場ベースの温室効果ガス総排出量は CO2e トン 0 トンとなりました。 トレーニングのエネルギー使用量と温室効果ガス排出量を決定するために使用される方法は、次の論文に記載されています。 Meta はこれらのモデルを公開しているため、他のユーザーはエネルギー使用量や温室効果ガス排出量のトレーニングの負担を負う必要がありません。 論文アドレス: https://arxiv.org/pdf/2204.05149概要: Llama 3.1は、公開ソースからの約1.5兆のトークンデータを使用して実施されました。トレーニング。微調整データには、公開されている命令データセットと、合成的に生成された 2,500 万を超えるサンプルが含まれています。 データの鮮度: 事前トレーニング データの期限は 2023 年 12 月です。 このセクションでは、Meta がアノテーションベンチマークにおける Llama 3.1 モデルのスコア結果を報告します。すべての評価で、Meta は内部評価ライブラリを使用します。 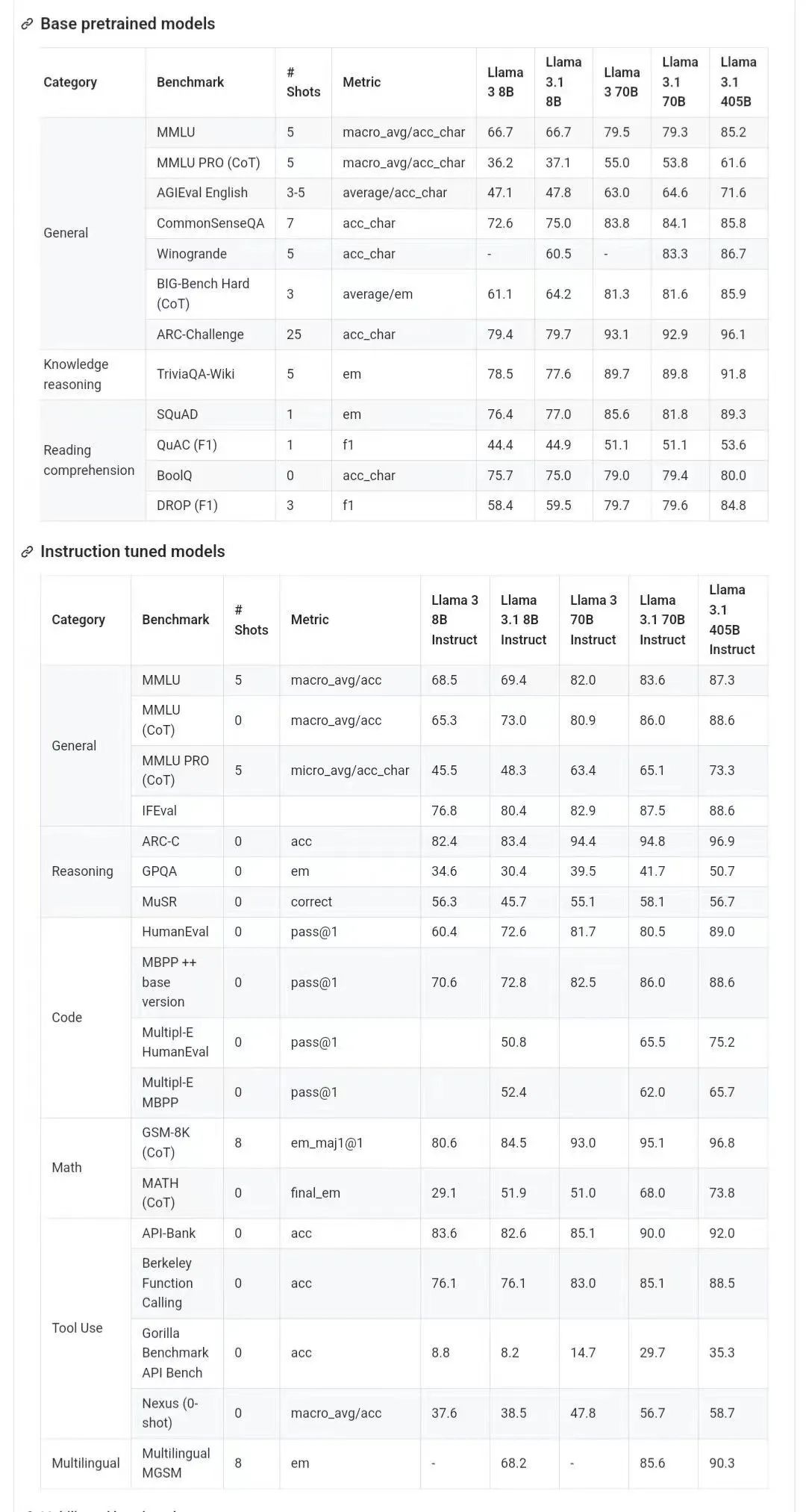
Llama 研究チームは、セキュリティ微調整の堅牢性を研究するための貴重なリソースを研究コミュニティに提供し、開発者にさまざまな用途に安全で堅牢な既製モデルを提供することに尽力しています。安全な AI システムを展開する開発者の作業負荷を軽減します。 研究チームは、潜在的なセキュリティ リスクを軽減するために、ベンダーから人間が生成したデータと合成データを組み合わせた多面的なデータ収集アプローチを使用しています。研究チームは、高品質のプロンプトと応答を慎重に選択するための大規模言語モデル (LLM) ベースの分類器を多数開発し、それによってデータ品質管理を強化しました。 Llama 3.1 は無害なプロンプトと拒否トーンのモデル拒否を非常に重視していることは言及する価値があります。研究チームは、境界プロンプトと敵対的プロンプトをセキュア データ ポリシーに導入し、トーン ガイドラインに従うようにセキュア データ レスポンスを修正しました。 Llama 3.1 モデルは、単独で展開するように設計されていませんが、必要に応じて追加の「安全ガードレール」を提供し、人工知能システム全体の一部として展開する必要があります。開発者はエージェントシステムを構築する際に、システムのセキュリティ対策を導入する必要があります。 このリリースでは、より長いコンテキスト ウィンドウ、多言語入出力、サードパーティ ツールとの開発者統合の可能性などの新機能が導入されていることに注意してください。これらの新機能を使用して構築する場合は、すべての生成 AI ユースケースに一般的に適用されるベスト プラクティスを考慮することに加えて、次の問題にも特別な注意を払う必要があります: ツールの使用: 標準的なソフトウェア開発と同様、開発者は、LLM を選択したツールやサービスと統合する責任があります。この機能を使用する際の安全性とセキュリティの制限を理解するために、ユースケースに応じた明確なポリシーを作成し、使用するサードパーティ サービスの完全性を評価する必要があります。 多言語: Lama 3.1は、英語に加えて、フランス語、ドイツ語、ヒンディー語、イタリア語、ポルトガル語、スペイン語、タイ語の7つの言語をサポートしています。 Llama は他の言語でテキストを出力できる場合がありますが、このテキストはセキュリティとヘルパビリティのパフォーマンスのしきい値を満たしていない可能性があります。 Llama 3.1 の核となる価値観は、オープン性、包括性、有用性です。すべての人に役立つように設計されており、さまざまなユースケースに適しています。したがって、Llama 3.1 は、あらゆる背景、経験、視点を持つ人々がアクセスできるように設計されています。 Llama 3.1 は、不必要な判断や規範を挿入することなく、ユーザーとそのニーズを中心に据えており、また、ある文脈では問題があるように見えるコンテンツでも、他の文脈では価値のある目的に役立つ可能性があるという認識を反映しています。 Llama 3.1 はすべてのユーザーの尊厳と自主性を尊重し、特にイノベーションと進歩を促進する自由な思考と表現の価値を尊重します。 しかし、Llama 3.1 は新しいテクノロジーであり、他の新しいテクノロジーと同様に、その使用にはリスクが伴います。これまでに実施されたテストでは、すべての状況をカバーできていません。したがって、すべての LLM と同様に、Llama 3.1 の潜在的な出力を事前に予測することはできず、場合によっては、モデルがユーザー プロンプトに対して不正確、偏り、または不快な反応を示す可能性があります。したがって、Llama 3.1 モデルのアプリケーションを展開する前に、開発者はモデルの特定のアプリケーションに合わせてセキュリティ テストと微調整を実行する必要があります。 モデルカードソース: https://pastebin.com/9jGkYbXY参考情報: https://x.com/op7418/status/1815340034717069728 https: //x.com/iScienceLuvr/status/1815519917715730702https://x.com/mattshumer_/status/1815444612414087294以上がGPT4o レベルを超える初のオープンソース モデル! Llama 3.1 がリーク: 4,050 億のパラメータ、ダウンロード リンク、モデル カードが利用可能の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。



















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



