


Die erste simulierte interaktive 3D-Gesellschaft, die speziell für verschiedene Roboter entwickelt wurde.
Erinnern Sie sich an Stanfords KI-Stadt? Dies ist eine virtuelle Umgebung, die von KI-Forschern in Stanford erstellt wurde. In dieser kleinen Stadt leben, arbeiten, knüpfen und verlieben sich ganz normal 25 KI-Agenten. Jeder Agent hat seine eigene Persönlichkeit und Hintergrundgeschichte. Das Verhalten und das Gedächtnis des Agenten werden durch große Sprachmodelle gesteuert, die die Erfahrungen des Agenten speichern und abrufen und auf der Grundlage dieser Erinnerungen Aktionen planen. (Siehe „Stanfords „virtuelle Stadt“ ist Open Source: 25 KI-Agenten erhellen „Westworld““)
In ähnlicher Weise hat kürzlich eine Gruppe von Forschern des Shanghai Artificial Intelligence Laboratory OpenRobotLab und anderer Institutionen eine Gruppe von Forschern hat auch eine virtuelle Stadt geschaffen. Unter ihnen leben jedoch Roboter und NPCs.  Mit 100.000 interaktiven Szenen und 89 verschiedenen Szenenkategorien ist diese Stadt die erste simulierte interaktive 3D-Gesellschaft, die speziell für verschiedene Roboter entwickelt wurde.
Mit 100.000 interaktiven Szenen und 89 verschiedenen Szenenkategorien ist diese Stadt die erste simulierte interaktive 3D-Gesellschaft, die speziell für verschiedene Roboter entwickelt wurde.

Die Autoren gaben an, dass sie diese Umgebung entworfen haben, um das Problem der Datenknappheit im Bereich der verkörperten Intelligenz zu lösen. Wie wir alle wissen, war die Erforschung des Skalierungsgesetzes im Bereich der verkörperten Intelligenz aufgrund der hohen Kosten für die Erhebung realer Daten schwierig. Daher wird das Simulation-to-Real-Paradigma (Sim2Real) zu einem entscheidenden Schritt bei der Erweiterung des verkörperten Modelllernens.
Die virtuelle Umgebung, die sie für Roboter entworfen haben, heißt GRUtopia. Das Projekt umfasst hauptsächlich:
1 Szenendatensatz. Enthält 100.000 interaktive, fein kommentierte Szenen, die frei zu Umgebungen im Stadtmaßstab kombiniert werden können. Im Gegensatz zu früheren Arbeiten, die sich hauptsächlich auf das Zuhause konzentrierten, deckt GRScenes 89 verschiedene Szenenkategorien ab und schließt damit die Lücke in serviceorientierten Umgebungen (in denen Roboter typischerweise zunächst eingesetzt werden).
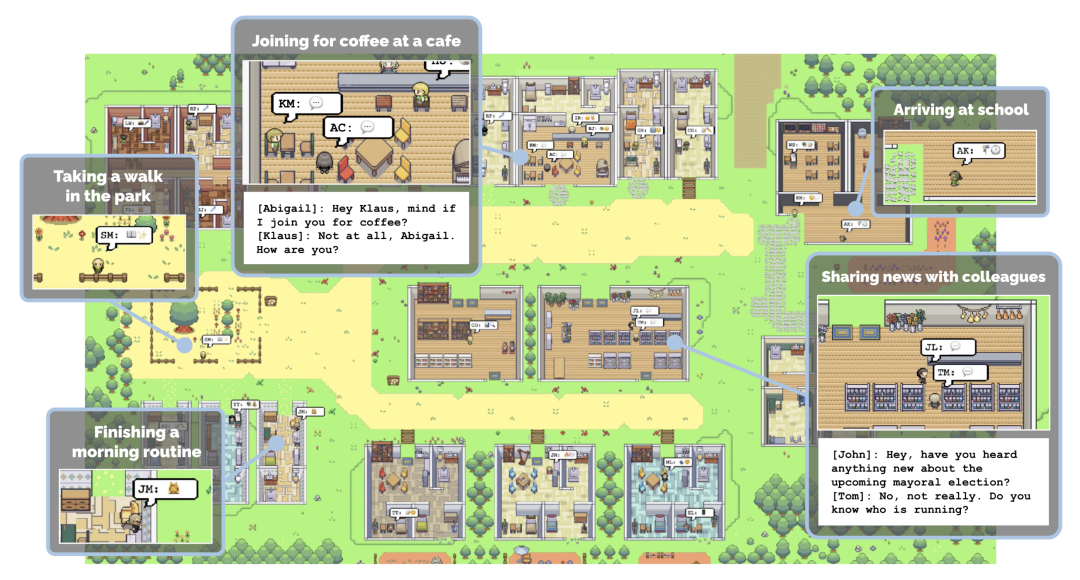
2. GREinwohner. Hierbei handelt es sich um ein durch ein großes Sprachmodell (LLM) gesteuertes Nicht-Spieler-Charaktersystem (NPC), das für soziale Interaktion, Aufgabengenerierung und Aufgabenzuweisung verantwortlich ist und dadurch soziale Szenarien für verkörperte KI-Anwendungen simuliert.
3. Benchmark GRBench. Es werden verschiedene Roboter unterstützt, der Schwerpunkt liegt jedoch auf Beinrobotern als Hauptagenten, und es werden mittelschwere Aufgaben vorgeschlagen, die Objektlokalisierungsnavigation, soziale Lokalisierungsnavigation und Lokalisierungsmanipulation umfassen.
Die Autoren hoffen, dass diese Arbeit den Mangel an qualitativ hochwertigen Daten in diesem Bereich lindern und eine umfassendere Bewertung der verkörperten KI-Forschung ermöglichen wird.

Papiertitel: GRUtopia: Dream General Robots in a City at Scale
Papieradresse: https://arxiv.org/pdf/2407.10943
Projektadresse: https://github .com/OpenRobotLab/GRUtopia
GRScenes: Vollständig interaktive Umgebungen im großen Maßstab
Um eine Plattform für die Schulung und Bewertung verkörperter Agenten aufzubauen, ist eine vollständig interaktive Umgebung mit verschiedenen Szenen- und Objektressourcen ein Muss. Unverzichtbar. Daher haben die Autoren einen großen synthetischen 3D-Szenendatensatz gesammelt, der verschiedene Objektressourcen als Grundlage der GRUtopia-Plattform enthält.
Vielfältige, realistische Szenen
Aufgrund der begrenzten Anzahl und Kategorie von Open-Source-3D-Szenendaten sammelte der Autor zunächst etwa 100.000 hochwertige synthetische Szenen von Designer-Websites, um verschiedene Szenenprototypen zu erhalten. Anschließend bereinigten sie diese Szenenprototypen, kommentierten sie mit Semantik auf Regions- und Objektebene und kombinierten sie schließlich zu Städten, die als grundlegende Spielwiese des Roboters dienten.
Wie in Abbildung 2-(a) gezeigt, enthält der vom Autor erstellte Datensatz zusätzlich zu gewöhnlichen Heimszenen auch 30 % anderer Szenenkategorien, wie z. B. Restaurants, Büros, öffentliche Orte, Hotels, Unterhaltung, usw. Die Autoren überprüften zunächst 100 fein kommentierte Szenen aus einem umfangreichen Datensatz für das Open-Source-Benchmarking. Diese 100 Szenen umfassen 70 Heimszenen und 30 Geschäftsszenen, wobei die Heimszene aus umfassenden Gemeinschaftsbereichen und anderen unterschiedlichen Bereichen besteht und die Geschäftsszenen gängige Typen wie Krankenhäuser, Supermärkte, Restaurants, Schulen, Bibliotheken und Büros abdecken.
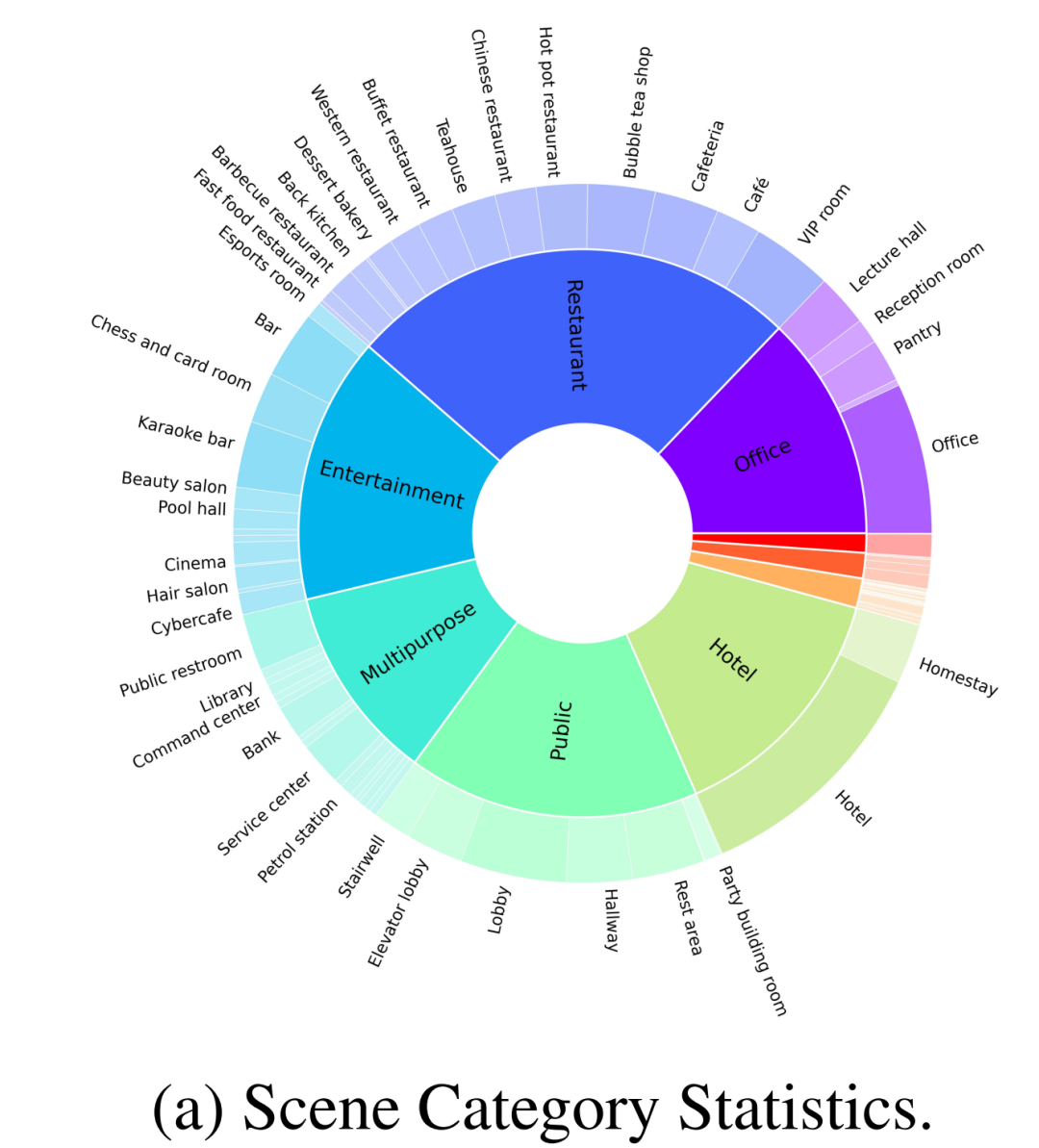
Darüber hinaus hat der Autor auch mit mehreren professionellen Designern zusammengearbeitet, um Objekte entsprechend den menschlichen Lebensgewohnheiten zuzuordnen, um diese Szenen realistischer zu gestalten, wie in Abbildung 1 dargestellt, was in früheren Arbeiten normalerweise ignoriert wird.
Interaktive Objekte mit Anmerkungen auf Teilebene
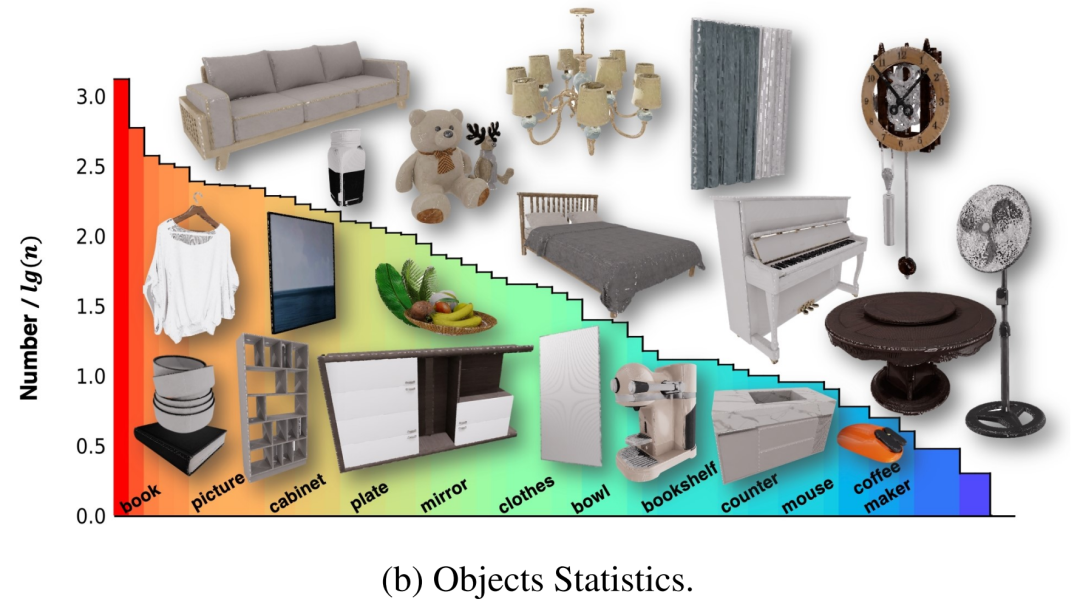
Diese Szenen enthielten ursprünglich mehrere 3D-Objekte, einige davon wurden jedoch nicht intern modelliert, sodass der Roboter nicht für die Interaktion mit diesen Objekten trainiert werden konnte. Um dieses Problem zu lösen, arbeiteten die Autoren mit einem Team von Fachleuten zusammen, um diese Assets zu modifizieren und vollständige Objekte zu erstellen, die es ihnen ermöglichten, auf physikalisch glaubwürdige Weise zu interagieren. Um umfassendere Informationen bereitzustellen, die es Agenten ermöglichen, mit diesen Assets zu interagieren, haben die Autoren den interaktiven Teilen aller Objekte in NVIDIA Omniverse außerdem fein abgestufte Teilbezeichnungen in Form eines X hinzugefügt. Schließlich enthalten die 100 Szenen 2956 interaktive Objekte und 22001 nicht interaktive Objekte in 96 Kategorien, und ihre Verteilung ist in Abbildung 2-(b) dargestellt.
Hierarchische multimodale Annotation
Um schließlich eine multimodale Interaktion verkörperter Agenten mit der Umgebung und dem NPC zu erreichen, müssen diese Szenen und Objekte auch sprachlich annotiert werden. Im Gegensatz zu früheren multimodalen 3D-Szenendatensätzen, die sich nur auf die Objektebene oder Beziehungen zwischen Objekten konzentrierten, berücksichtigten die Autoren auch unterschiedliche Granularitäten von Szenenelementen, beispielsweise die Beziehung zwischen Objekten und Regionen. Angesichts des Fehlens von Regionsbezeichnungen entwarfen die Autoren zunächst eine Benutzeroberfläche, um Regionen mit Polygonen in einer Vogelperspektive der Szene zu kommentieren, die dann Objekt-Region-Beziehungen in die sprachliche Annotation einbeziehen könnte. Für jedes Objekt veranlassen sie einen leistungsstarken VLM (z. B. GPT-4v) mit gerenderten Multi-View-Bildern, um Anmerkungen zu initialisieren, die dann von Menschen überprüft werden. Die resultierenden linguistischen Anmerkungen bilden die Grundlage für nachfolgende verkörperte Aufgaben zur Benchmark-Generierung.
GRResidents3D-Umgebung generative NPCs
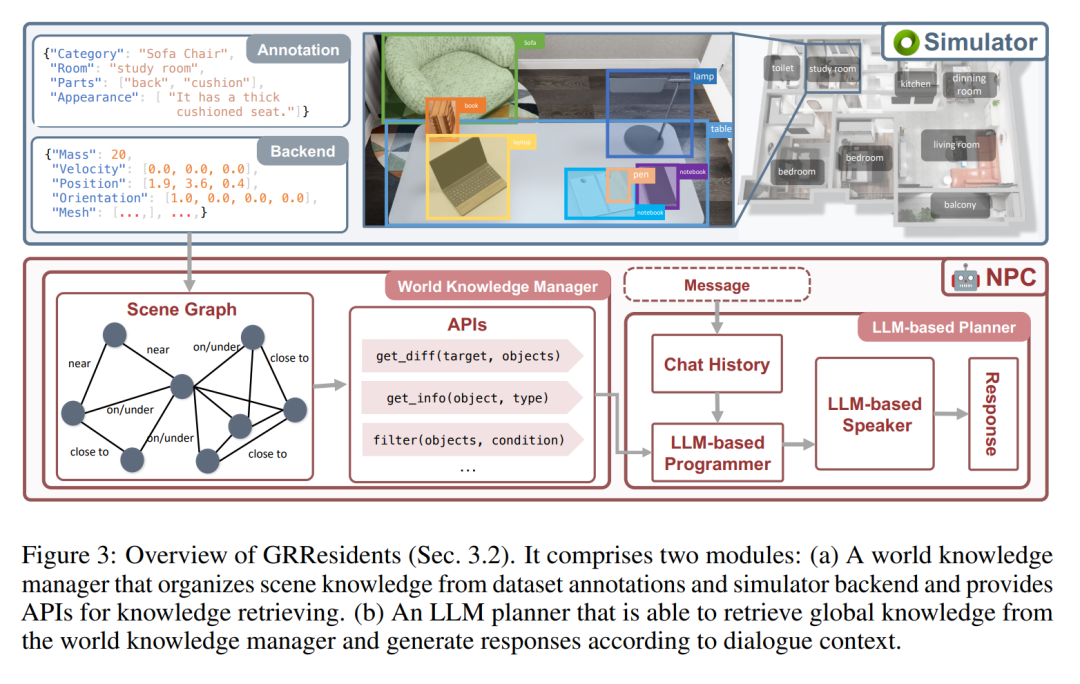
In GRUtopia verleiht der Autor der Welt soziale Fähigkeiten, indem er einige „Bewohner“ (d. h. generative NPCs, die von LLM gesteuert werden) einbettet, um soziale Interaktionen in städtischen Umgebungen zu simulieren. Dieses NPC-System trägt den Namen GRResidents. Eine der größten Herausforderungen beim Aufbau realistischer virtueller Charaktere in 3D-Szenen ist die Integration von 3D-Wahrnehmungsfunktionen. Virtuelle Charaktere können jedoch problemlos auf Szenenanmerkungen und den internen Zustand der simulierten Welt zugreifen, was leistungsstarke Wahrnehmungsfähigkeiten ermöglicht. Zu diesem Zweck haben die Autoren einen World Knowledge Manager (WKM) entworfen, um dynamisches Wissen über Echtzeit-Weltzustände zu verwalten und den Zugriff über eine Reihe von Datenschnittstellen zu ermöglichen. Mit WKM können NPCs das erforderliche Wissen abrufen und durch parametrisierte Funktionsaufrufe eine feinkörnige Objekterdung durchführen, die den Kern ihrer Empfindungsfähigkeiten bildet.
World Knowledge Manager (WKM)
Die Hauptaufgabe von WKM besteht darin, das Wissen über virtuelle Umgebungen kontinuierlich zu verwalten und NPCs erweitertes Szenenwissen bereitzustellen. Konkret ruft WKM hierarchische Anmerkungen und Szenenwissen aus dem Datensatz bzw. dem Simulator-Backend ab und erstellt einen Szenengraphen als Szenendarstellung, wobei jeder Knoten eine Objektinstanz darstellt und Kanten räumliche Beziehungen zwischen Objekten darstellen. Die Autoren übernehmen die in Sr3D definierten räumlichen Beziehungen als relationalen Raum. WKM behält dieses Szenendiagramm bei jedem Simulationsschritt bei. Darüber hinaus bietet WKM auch drei Kerndatenschnittstellen zum Extrahieren von Wissen aus Szenendiagrammen:
1, find_diff (Ziel, Objekte): vergleicht den Unterschied zwischen dem Zielobjekt und einer Reihe anderer Objekte;
2, get_info (Objekt, Typ): Objektwissen entsprechend dem erforderlichen Attributtyp abrufen;
3. Filtern (Objekte, Bedingung): Objekte nach Bedingungen filtern.
LLM-Planer
Das Entscheidungsmodul von NPC ist ein LLM-basierter Planer, der aus drei Teilen besteht (Abbildung 3): einem Speichermodul, das zum Speichern des Chat-Verlaufs zwischen NPC und anderen Agenten verwendet wird; von WKM, um Szenenwissen abzufragen; und ein LLM-Sprecher wird verwendet, um den Chat-Verlauf und das abgefragte Wissen zu verarbeiten, um Antworten zu generieren. Wenn ein NPC eine Nachricht empfängt, speichert er die Nachricht zunächst im Speicher und leitet dann den aktualisierten Verlauf an den LLM-Programmierer weiter. Anschließend ruft der Programmierer wiederholt die Datenschnittstelle auf, um das notwendige Szenenwissen abzufragen. Schließlich werden das Wissen und die Geschichte an den LLM-Sprecher gesendet, der eine Antwort generiert.
Experimente
Der Autor führte Experimente zu Objektreferenz, Spracherdung und objektzentrierter Qualitätssicherung durch, um zu beweisen, dass der NPC im Artikel Objektbeschreibungen generieren, Objekte anhand von Beschreibungen lokalisieren und intelligente Objekte bereitstellen kann. Der Körper stellt Objekte bereit Information. Zu den NPC-Backend-LLMs in diesen Experimenten gehören GPT-4o, InternLM2-Chat-20B und Llama-3-70BInstruct.
図 4 に示すように、参考実験では著者らは人間参加型評価を使用しました。 NPC はオブジェクトをランダムに選択してそれを説明し、ヒューマン・アノテーターはその説明に基づいてオブジェクトを選択します。ヒューマン・アノテーターが説明に対応する正しいオブジェクトを見つけることができれば、参照は成功します。グラウンディング実験では、GPT-4o はヒューマン アノテーターの役割を果たし、NPC によって配置されたオブジェクトの説明を提供しました。 NPC が対応するオブジェクトを見つけることができれば、接地は成功します。
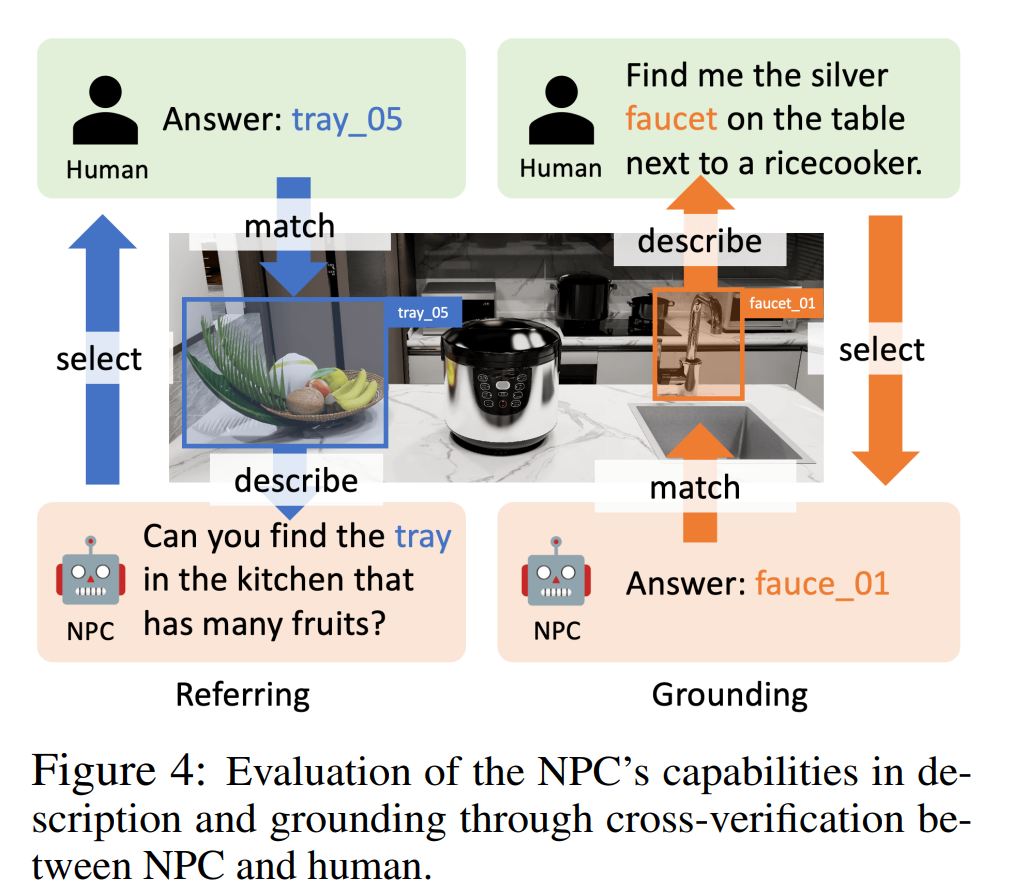
表 2 の成功率 (参照およびグラウンディング) は、さまざまな LLM の精度率がそれぞれ 95.9% ~ 100% および 83.3% ~ 93.2% であることを示しており、NPC フレームワークがさまざまな LLM を参照できることが検証されています。そして接地精度。
オブジェクト中心の QA 実験で、著者らは、ナビゲーション タスクの質問に答えることでオブジェクト レベルの情報をエージェントに提供する NPC の能力を評価しました。彼らは、現実世界のシナリオをシミュレートするオブジェクト中心のナビゲーション プロットを生成するパイプラインを設計しました。これらのシナリオでは、エージェントは NPC に質問して情報を取得し、その回答に基づいてアクションを実行します。エージェントの質問が与えられると、著者はその回答と実際の回答の間の意味論的な類似性に基づいて NPC を評価します。表 2 (QA) に示されている総合スコアは、NPC が正確で有用なナビゲーション支援を提供できることを示しています。
GRBench: 身体化エージェントを評価するためのベンチマーク
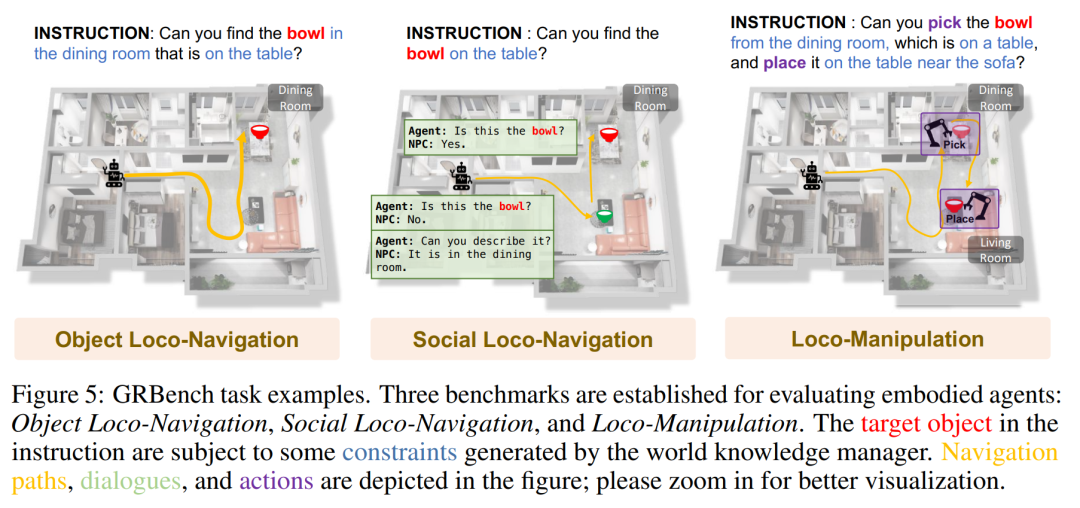
GRBench は、ロボット エージェントの機能を評価するための包括的な評価ツールです。日常のタスクを処理するロボット エージェントの能力を評価するために、GRBench にはオブジェクト ローカリゼーション ナビゲーション、ソーシャル ローカリゼーション ナビゲーション、およびローカリゼーション オペレーションの 3 つのベンチマークが含まれています。これらのベンチマークの難易度は徐々に上がり、ロボットに必要なスキルも上がります。
脚式ロボットの優れた地形横断能力により、著者はそれをメインエージェントとして優先しました。ただし、大規模なシナリオでは、現在のアルゴリズムでは高レベルの認識、計画、および低レベルの制御を同時に実行し、満足のいく結果を達成することが困難です。
GRBench の最新の進歩により、シミュレーションにおける単一スキルの高精度ポリシーのトレーニングの実現可能性が証明されました。これに触発されて、GRBench の初期バージョンは高レベルのタスクに焦点を当て、学習ベースの制御戦略を API として提供します。歩いて選んで配置します。その結果、ベンチマークはより現実的な物理環境を提供し、シミュレーションと現実世界の間のギャップを埋めます。
下の図は、GRBench タスクの例をいくつか示しています。
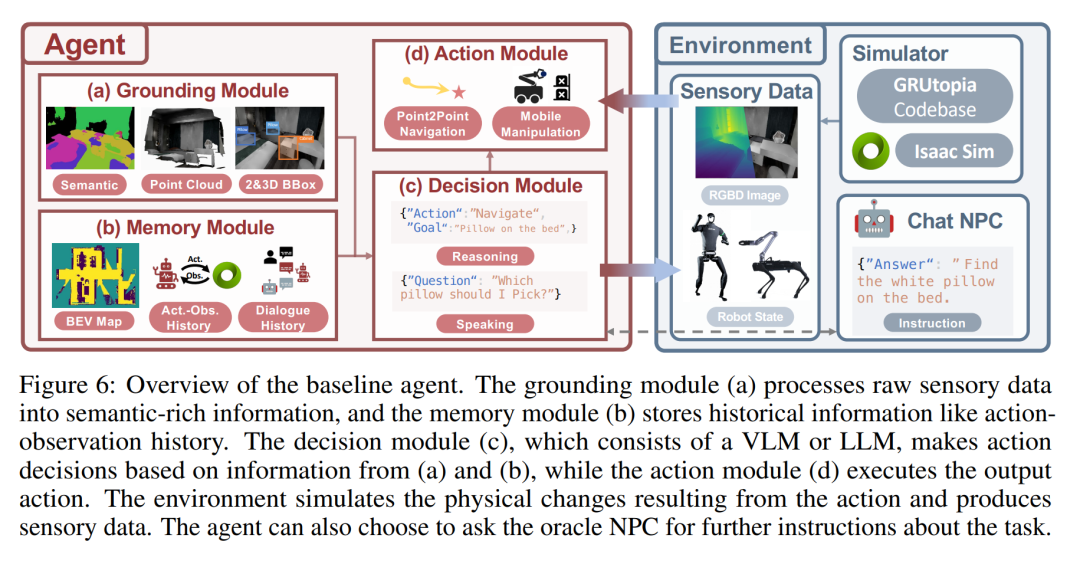
下の図は、ベースライン エージェントの概要です。グラウンディング モジュール (a) は生の感覚データを処理して意味論的に豊富な情報を生成し、メモリ モジュール (b) は行動観察履歴などの履歴情報を保存します。決定モジュール (c) は VLM または LLM で構成され、(a) と (b) からの情報に基づいてアクションの決定を行い、アクション モジュール (d) は出力アクションを実行します。環境は、行動によってもたらされる物理的な変化をシミュレートし、感覚データを生成します。エージェントは、タスクに関するさらなる指示をアドバイザー NPC に求めることを選択できます。
定量的な評価結果
著者は、3 つのベンチマーク テストで、異なる大規模モデル バックエンドの下で大規模モデル駆動型エージェント フレームワークの比較分析を実行しました。表 4 に示すように、ランダム戦略のパフォーマンスが 0 に近いことがわかり、タスクが単純ではないことがわかりました。比較的優れた大規模モデルをバックエンドとして使用すると、3 つのベンチマークすべてで全体的なパフォーマンスが大幅に向上することが観察されました。対話において Qwen が GPT-4o よりも優れたパフォーマンスを発揮したことを彼らが観察したことは言及する価値があります (表 5 を参照)。
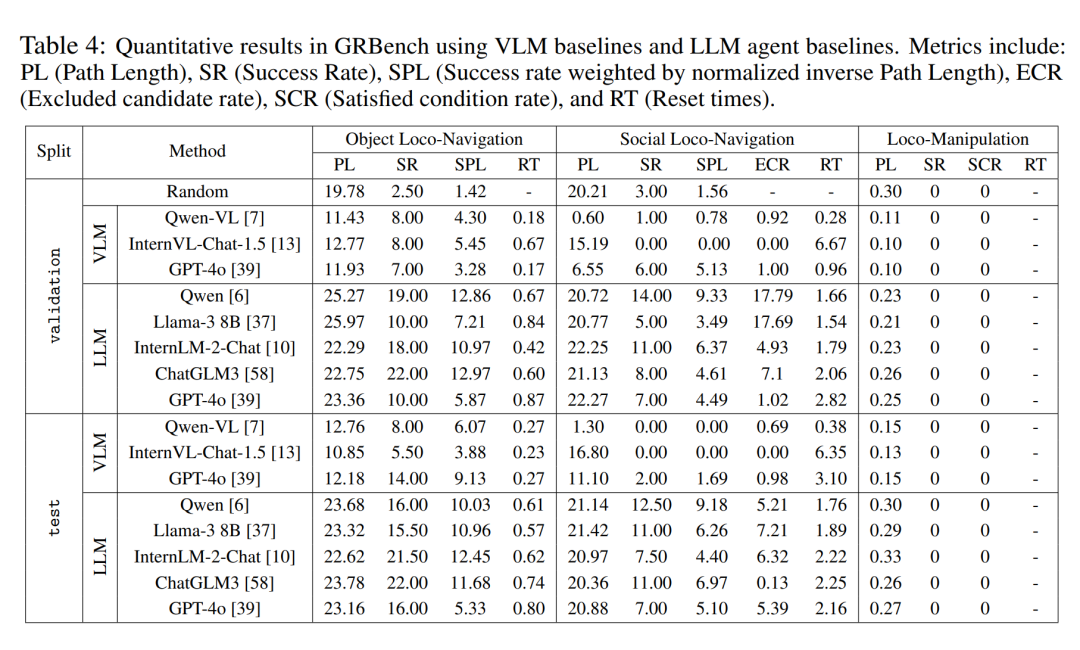

さらに、意思決定にマルチモーダル大規模モデルを直接使用する場合と比較して、この記事で提案されているエージェント フレームワークは明らかな優位性を示しています。これは、現在の最先端のマルチモーダル大規模モデルでさえ、現実世界の具体化されたタスクに対する強力な一般化機能に欠けていることを示しています。ただし、この記事の方法にも改善の余地がかなりあります。このことは、ナビゲーションのような長年研究されてきた課題であっても、より現実世界に近い課題設定を導入した場合には、未だ完全な解決には程遠いことを示している。
定性評価結果
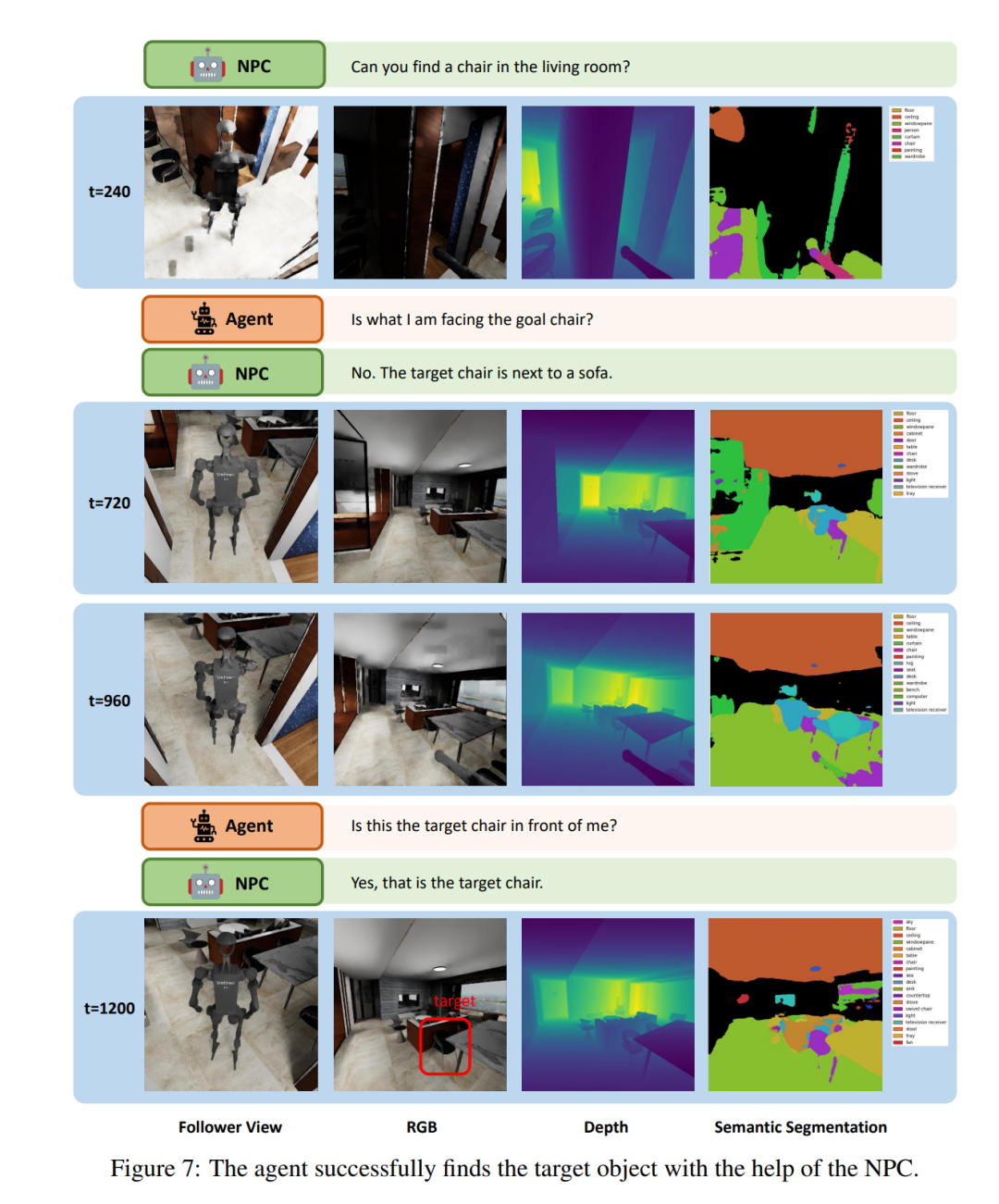
図 7 は、LLM エージェントが「ソーシャル ロコ ナビゲーション」タスクで実行する小さな断片を示し、エージェントが NPC とどのように対話するかを示しています。エージェントは最大 3 回まで NPC と会話して、より多くのタスク情報を問い合わせることができます。 t = 240 で、エージェントは椅子に移動し、この椅子がターゲットの椅子であるかどうかを NPC に尋ねます。次に、NPC は曖昧さを減らすためにターゲットに関する周辺情報を提供します。 NPC の支援により、エージェントは人間の行動と同様の対話プロセスを通じてターゲットの椅子を特定することに成功しました。これは、この論文の NPC が人間とロボットの相互作用とコラボレーションを研究するために自然な社会的相互作用を提供できることを示しています。
以上が身体化知能研究のために特別に作られたロボット版「スタンフォード・タウン」が登場の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



