



Lajur AIxiv ialah lajur di mana tapak ini menerbitkan kandungan akademik dan teknikal. Dalam beberapa tahun kebelakangan ini, lajur AIxiv laman web ini telah menerima lebih daripada 2,000 laporan, meliputi makmal terkemuka dari universiti dan syarikat utama di seluruh dunia, mempromosikan pertukaran dan penyebaran akademik secara berkesan. Jika anda mempunyai kerja yang sangat baik yang ingin anda kongsikan, sila berasa bebas untuk menyumbang atau hubungi kami untuk melaporkan. E-mel penyerahan: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Yizuo Diao Haiwen ialah pelajar kedoktoran di Universiti Teknologi Dalian, dan penyelianya ialah Profesor Lu Huchuan. Sedang berkhidmat di Institut Penyelidikan Kepintaran Buatan Beijing Zhiyuan, pengajarnya ialah Dr. Wang Xinlong. Minat penyelidikannya ialah visi dan bahasa, pemindahan model besar yang cekap, model besar berbilang modal, dsb. Pengarang bersama pertama Cui Yufeng lulus dari Universiti Beihang dan merupakan penyelidik algoritma di Pusat Penglihatan Institut Penyelidikan Kepintaran Buatan Zhiyuan Beijing. Minat penyelidikannya ialah model multimodal, model generatif, dan visi komputer, dan kerja utamanya adalah dalam siri Emu.
Baru-baru ini, penyelidikan mengenai model besar berbilang modal sedang giat dijalankan, dan industri telah melabur lebih banyak lagi dalam hal ini. Model hangat telah dilancarkan di luar negara, seperti GPT-4o (OpenAI), Gemini (Google), Phi-3V (Microsoft), Claude-3V (Anthropic), dan Grok-1.5V (xAI). Pada masa yang sama, domestik GLM-4V (Wisdom Spectrum AI), Step-1.5V (Step Star), Emu2 (Beijing Zhiyuan), Intern-VL (Shanghai AI Laboratory), Qwen-VL (Alibaba), dll. Model berkembang .
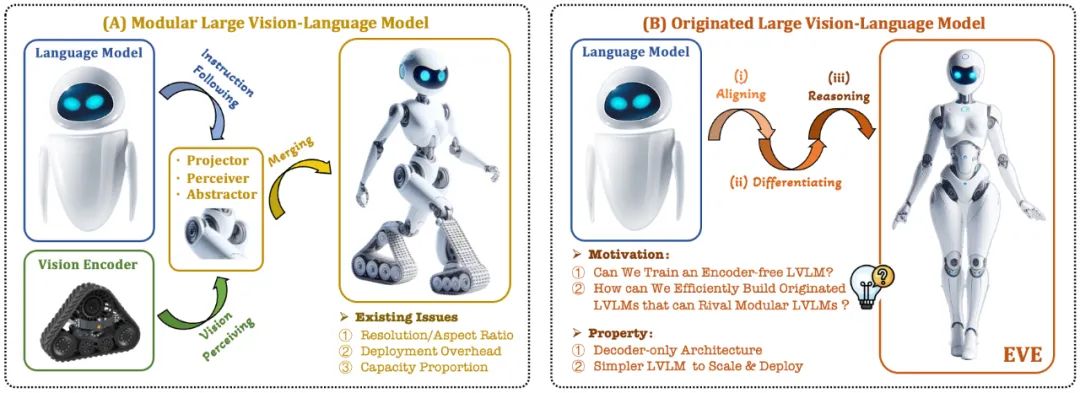
Model bahasa visual (VLM) semasa biasanya bergantung pada pengekod visual (Vision Encoder, VE) untuk mengekstrak ciri visual, dan kemudian menggabungkan arahan pengguna dengan model bahasa besar (LLM) untuk memproses dan menjawab dalam pengekod visual dan pemisahan Latihan untuk model bahasa yang besar. Pemisahan ini menyebabkan pengekod visual memperkenalkan isu bias induksi visual apabila antara muka dengan model bahasa yang besar, seperti peleraian imej dan nisbah bidang yang terhad, serta semantik visual yang kuat. Memandangkan kapasiti pengekod visual terus berkembang, kecekapan penggunaan model besar berbilang mod dalam memproses isyarat visual juga amat terhad. Di samping itu, cara mencari konfigurasi kapasiti optimum pengekod visual dan model bahasa besar telah menjadi semakin kompleks dan mencabar.
Dalam konteks ini, beberapa idea yang lebih canggih muncul dengan cepat:
Bolehkah kita mengalih keluar pengekod visual, iaitu membina secara langsung model besar berbilang mod asli tanpa pengekod visual?
Bagaimana untuk mengembangkan model bahasa besar dengan cekap dan lancar menjadi model besar berbilang modal asli tanpa pengekod visual?
Bagaimana untuk merapatkan jurang prestasi antara rangka kerja berbilang modal asli tanpa pengekod dan paradigma berbilang modal berasaskan pengekod arus perdana?
Adept AI mengeluarkan model siri Fuyu pada penghujung tahun 2023 dan membuat beberapa percubaan berkaitan, tetapi tidak mendedahkan sebarang strategi latihan, sumber data dan maklumat peralatan. Pada masa yang sama, terdapat jurang prestasi yang ketara antara model Fuyu dan algoritma arus perdana dalam penunjuk penilaian teks visual awam. Dalam tempoh yang sama, beberapa percubaan rintis yang kami jalankan menunjukkan bahawa walaupun skala data pra-latihan ditingkatkan secara besar-besaran, model besar multi-modal asli tanpa pengekod masih menghadapi masalah yang sukar seperti kelajuan penumpuan yang perlahan dan prestasi yang lemah.
Sebagai tindak balas kepada cabaran ini, pasukan visi Institut Penyelidikan Zhiyuan, bersama-sama Universiti Teknologi Dalian, Universiti Peking dan universiti domestik lain, melancarkan generasi baharu model bahasa visual tanpa pengekod EVE. Melalui strategi latihan yang diperhalusi dan penyeliaan visual tambahan, EVE menyepadukan perwakilan visual-linguistik, penjajaran dan inferens ke dalam seni bina penyahkod tulen bersatu. Menggunakan data yang tersedia secara umum, EVE berprestasi baik pada berbilang penanda aras visual-linguistik, bersaing dengan kaedah multimodal berasaskan pengekod arus perdana dengan kapasiti yang sama dan dengan ketara mengatasi prestasi rakan Fuyu-8B. EVE dicadangkan untuk menyediakan laluan yang telus dan cekap untuk pembangunan seni bina berbilang modal asli untuk penyahkod tulen.


Alamat kertas: https://arxiv.org/abs/2406.11832
Kod projek: https://github.com/baaivision ://huggingface.co/BAAI/EVE-7B-HD-v1.0
ネイティブビジュアル言語モデル: 主流のマルチモーダルモデルの固定パラダイムを打ち破り、ビジュアルエンコーダーを削除し、あらゆる画像アスペクト比を処理できます。これは、複数のビジュアル言語ベンチマークで同じタイプの Fuyu-8B モデルを大幅に上回り、主流のビジュアル エンコーダベースのビジュアル言語アーキテクチャに近いものです。
低いデータコストとトレーニングコスト: EVE モデルの事前トレーニングでは、OpenImages、SAM、LAION からの公開データのみがスクリーニングされ、665,000 個の LLaVA 命令データと追加の 120 万個のビジュアルダイアログデータがそれぞれ標準および高レベルの構築に利用されました。 EVE-7B の解像度バージョン。トレーニングが完了するまでに、2 つの 8-A100 (40G) ノードで約 9 日、4 つの 8-A100 ノードで約 5 日かかります。
透明で効率的な探索: EVE は、ネイティブ視覚言語モデルへの効率的で透明かつ実用的なパスを探索し、新世代の純粋なデコーダー視覚言語モデル アーキテクチャの開発に新しいアイデアと貴重な経験を提供します。将来のマルチモーダル モデルの開発により、新たな探索の方向性が開かれます。
2. モデル構造
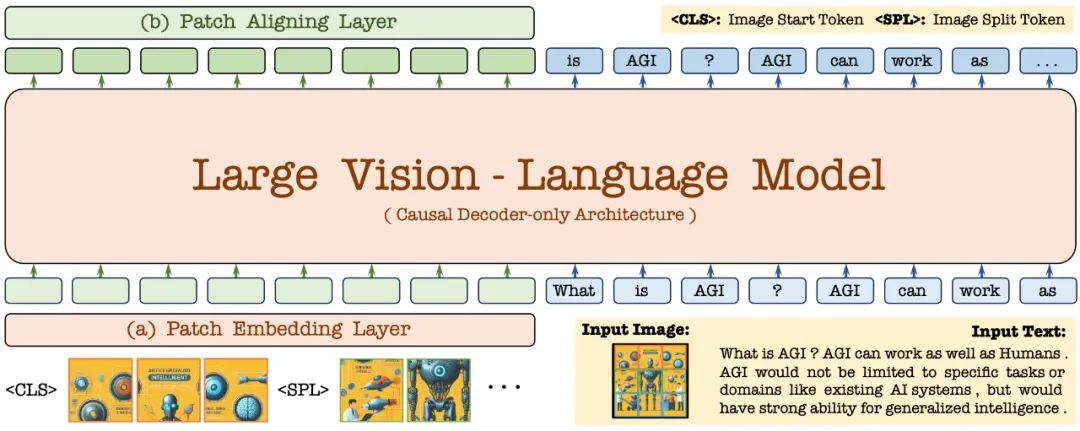
まず、Vicuna-7B 言語モデルを通じて初期化され、豊富な言語知識と強力な命令追従機能を備えています。これに基づいて、ディープビジュアルエンコーダが削除され、軽量ビジュアルエンコード層が構築され、画像入力が効率的かつ可逆的にエンコードされ、ユーザー言語コマンドとともに統合デコーダに入力されます。さらに、ビジュアル アライメント レイヤーは、一般的なビジュアル エンコーダとの特徴アライメントを実行して、きめの細かい視覚情報のエンコードと表現を強化します。
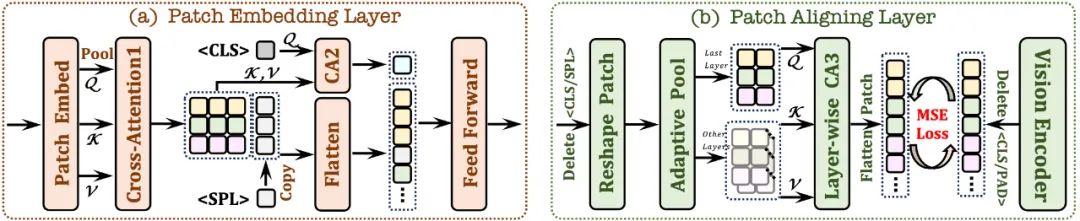
2.1 パッチ埋め込み層
最初に単一の畳み込み層を使用して画像の 2D 特徴マップを取得し、次に平均プーリング層を通じてダウンサンプリングします
クロス アテンション モジュール (CA1) を使用します。各パッチのローカル機能を強化するために、限定された受容野で対話します。
は、トークンを使用し、クロスアテンションモジュール(CA2)と組み合わせて、各パッチ機能のグローバル情報を提供します。ネットワークが画像の 2 次元空間構造を理解できるように、学習可能な
トークンが行の最後に挿入されます。2.2 パッチ調整レイヤー
有効なパッチの 2D 形状を記録し、
/大規模な言語モデルに基づいた事前トレーニング段階: 視覚と言語の間の最初の接続を確立し、その後の安定した効率的な大規模な事前トレーニングの基礎を築きます。 ;
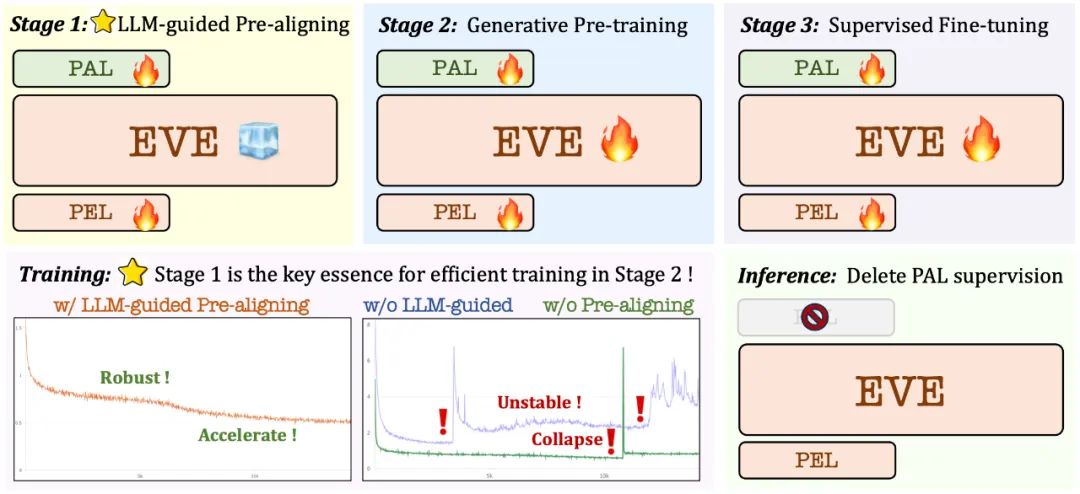 生成的事前トレーニングフェーズ: 視覚言語コンテンツを理解するモデルの能力をさらに向上させ、純粋な言語モデルからマルチモーダルモデルへのスムーズな移行を実現します。
生成的事前トレーニングフェーズ: 視覚言語コンテンツを理解するモデルの能力をさらに向上させ、純粋な言語モデルからマルチモーダルモデルへのスムーズな移行を実現します。
教師付き微調整フェーズ: さらに言語の指示に従うモデルと、さまざまな視覚言語ベンチマークの要件を満たす会話パターンを学習する機能を標準化します。
 監視付き微調整ステージでは、LLaVA-mix-665K 微調整データセットを使用して EVE-7B の標準バージョンをトレーニングし、AI2D、Synthdog、DVQA、ChartQA、DocVQA、 Vision-Flan と Bunny-695K は、EVE-7B の高解像度バージョンを取得するためにトレーニングするように設定されています。
監視付き微調整ステージでは、LLaVA-mix-665K 微調整データセットを使用して EVE-7B の標準バージョンをトレーニングし、AI2D、Synthdog、DVQA、ChartQA、DocVQA、 Vision-Flan と Bunny-695K は、EVE-7B の高解像度バージョンを取得するためにトレーニングするように設定されています。
EVE モデルは、複数の視覚言語ベンチマークで同様の Fuyu-8B モデルを大幅に上回り、さまざまな主流のエンコーダーベースの視覚言語モデルと同等のパフォーマンスを発揮します。ただし、トレーニングに大量の視覚言語データを使用するため、特定の指示に正確に応答するのに課題があり、一部のベンチマーク テストでのパフォーマンスを改善する必要があります。興味深いのは、効率的なトレーニング戦略を通じて、エンコーダレス EVE がエンコーダベースのビジュアル言語モデルと同等のパフォーマンスを達成でき、入力サイズの柔軟性、導入効率、および主流モデルのキャパシティ マッチングの問題を根本的に解決できることです。
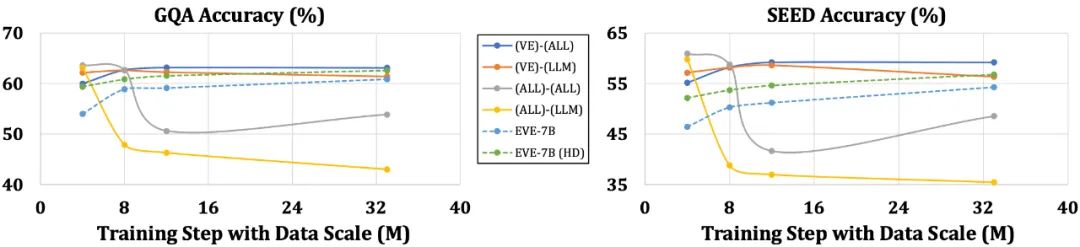
言語構造の単純化や豊富な知識の損失などの問題が発生しやすいエンコーダーを備えたモデルと比較して、EVEはデータサイズの増加に応じて徐々に安定したパフォーマンスの向上を示し、徐々にエンコーダーのパフォーマンスに近づいていますベースのモデルのレベル。これは、統合ネットワーク内で視覚的モダリティと言語モダリティをエンコードして調整することがより困難であり、エンコーダなしのモデルがエンコーダありのモデルに比べて過剰適合する傾向が低いためである可能性があります。
5. 同僚はどう思いますか?
NVIDIA の上級研究員である Ali Hatamizadeh 氏は、EVE は新鮮であり、複雑な評価基準の構築や進歩的な視覚言語モデルの改善とは異なる、新しい物語を提案しようとしていると述べました。

Google Deepmind の主任研究員である Armand Joulin 氏は、純粋なデコーダー視覚言語モデルを構築するのはエキサイティングであると述べました。

Apple 機械学習エンジニアの Prince Canuma 氏は、EVE アーキテクチャは非常に興味深いものであり、MLX VLM プロジェクト セットへの優れた追加であると述べました。

6. 今後の展望
エンコーダーのないネイティブビジュアル言語モデルとして、EVE は現在、有望な結果を達成しています。この道筋に沿って、将来的に検討する価値のある興味深い方向性がいくつかあります:
さらなるパフォーマンスの向上: 実験により、視覚言語データのみを使用した事前トレーニングによりモデルの言語能力が大幅に低下することがわかりました (SQA スコアは 65.3% から低下しました) 63.0% まで)、しかしモデルのマルチモーダル パフォーマンスは徐々に改善されました。これは、大規模な言語モデルが更新されると、言語知識が内部的に壊滅的に忘れられることを示しています。純粋な言語の事前トレーニング データを適切に統合するか、専門家の混合 (MoE) 戦略を使用して、視覚モダリティと言語モダリティの間の干渉を減らすことが推奨されます。
エンコーダーレス アーキテクチャの想像力: 適切な戦略と高品質のデータによるトレーニングにより、エンコーダーレスの視覚言語モデルはエンコーダー付きモデルに匹敵することができます。では、同じモデル能力と大量のトレーニング データの下では、この 2 つのパフォーマンスはどれくらいでしょうか?エンコーダレス アーキテクチャは、ほぼロスレスで画像を入力し、ビジュアル エンコーダのアプリオリ バイアスを回避するため、モデルの容量とトレーニング データ量を拡張することで、エンコーダレス アーキテクチャがエンコーダベースのアーキテクチャに達するか、それを超える可能性があると我々は推測しています。
ネイティブ マルチモーダル モデルの構築: EVE は、ネイティブ マルチモーダル モデルを効率的かつ安定的に構築する方法を完全に示します。これにより、その後のより多くのモダリティ (オーディオ、ビデオ、熱画像、深度、など)と実践的なパス。中心となるアイデアは、大規模な統合トレーニングを導入する前に、凍結された大規模言語モデルを通じてこれらのモダリティを事前に調整し、対応する単一モーダル エンコーダーと言語概念の調整を監視に利用することです。
以上がビジュアルエンコーダを放棄したこの「ネイティブバージョン」マルチモーダル大規模モデルは、主流の手法にも匹敵しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



