中心となる概念
- 主キーインデックス / 副キーインデックス
- クラスター化インデックス / 非クラスター化インデックス
- テーブルルックアップ / インデックスカバレッジ
- インデックスプッシュダウン
- 複合インデックス / 左端のプレフィックス マッチング
- プレフィックスインデックス
- 説明
1. 【インデックス定義】
1.インデックス定義
データ自体に加えて、データベース システムは特定の検索アルゴリズムを満たすデータ構造も維持します。これらの構造は、特定の方法でデータを参照 (ポイント)し、高度な検索アルゴリズムを実装できるようにします。 これらのデータ構造はインデックスです。
2.インデックスのデータ構造
- B ツリー / B+ ツリー (MySQL の InnoDB エンジンはデフォルトのインデックス構造として B+ ツリーを使用します)
- ハッシュテーブル
- ソートされた配列
3. B ツリーではなく B+ ツリーを選択する理由
- B ツリー構造: レコードはツリー ノードに格納されます。
- B+ ツリー構造: レコードはツリーのリーフ ノードにのみ保存されます。
- データ サイズが 1KB、インデックス サイズが 16B、データベースがディスク データ ページを使用し、デフォルトのディスク ページ サイズが 16K であると仮定すると、同じ 3 つの I/O 操作で次の結果が得られます。
B ツリーは 16*16*16=4096 レコードをフェッチできます。
B+ ツリーは 1000*1000*1000=10 億 レコードをフェッチできます。
2. 【インデックスの種類】
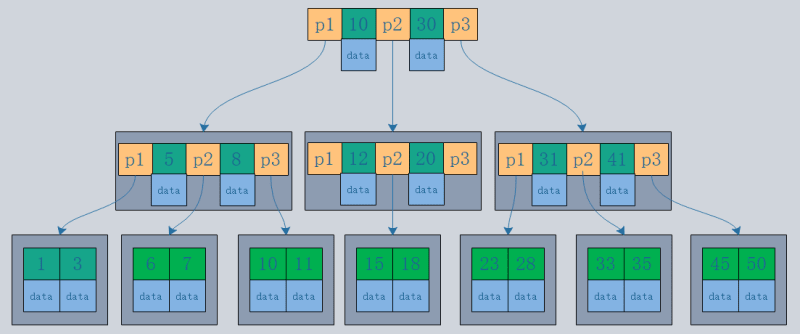
1.主キーインデックスと副キーインデックス
-
主キー インデックス: インデックスのリーフ ノードはデータ行です。
-
セカンダリ インデックス: インデックスのリーフ ノードは、KEY フィールドと主キー インデックスです。したがって、セカンダリ インデックスを通じてクエリを実行すると、まず主キー値が検索され、次に InnoDB は主キー インデックスを通じて対応するデータ ブロックを検索します。
-
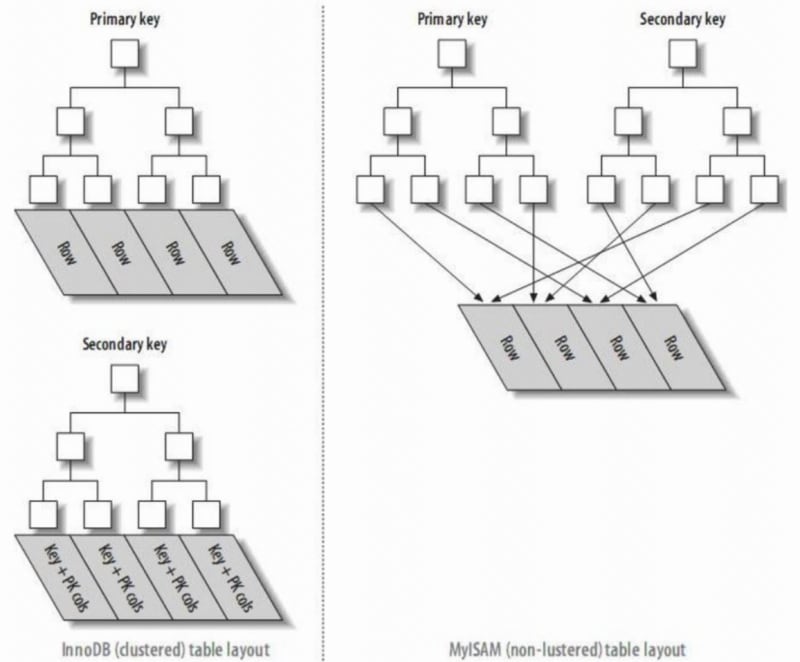
InnoDB では、プライマリ インデックス ファイルはクラスター化インデックスと呼ばれるデータ行を直接保存し、セカンダリ インデックスは主キー参照を指します。
-
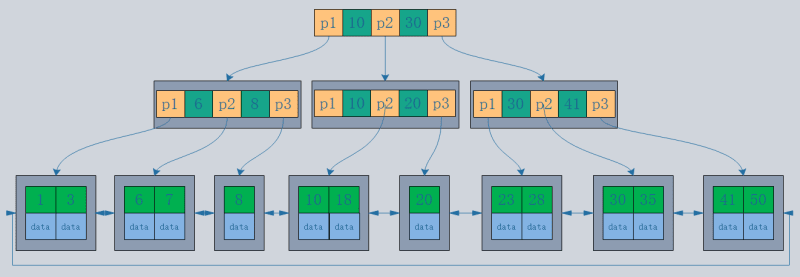
MyISAM では、プライマリ インデックスとセカンダリ インデックスの両方が物理行 (ディスクの位置) を指します。
2.クラスター化インデックスと非クラスター化インデックス
- クラスター化インデックスは、ディスク上の実際のデータを再編成し、1 つ以上の指定された列値で並べ替えます。データの格納順序とインデックスの順序が一致しているのが特徴です。一般に、主キーはデフォルトでクラスター化インデックスを作成し、テーブルでは 1 つのクラスター化インデックスのみが許可されます (理由: データは 1 つの順序でのみ保存できます)。画像に示すように、InnoDB のプライマリ インデックスとセカンダリ インデックスはクラスター化インデックスです。
- クラスター化インデックスのリーフ ノードがデータ レコードであるのに対し、非クラスター化インデックスのリーフ ノードはデータ レコードへのポインターです。最大の違いは、データ レコードの順序がインデックスの順序と一致しないことです。
3.クラスター化インデックスの利点と欠点
- 利点: 主キーによってエントリをクエリする場合、テーブル検索を実行する必要はありません (データは主キー ノードの下にあります)。
- 欠点: 不規則なデータ挿入により、ページ分割が頻繁に発生する可能性があります。
3. [拡張インデックスの概念]
1.テーブルルックアップ
テーブル ルックアップの概念には、主キー インデックス クエリと非主キー インデックス クエリの違いが関係します。
- クエリが select * from T where ID=500 の場合、主キー クエリは ID ツリーを検索するだけで済みます。
- クエリが select * from T where k=5 の場合、非主キー インデックス クエリは、最初に k インデックス ツリーを検索して ID 値 500 を取得し、次に ID インデックス ツリーを再度検索する必要があります。
- 非主キー インデックスから主キー インデックスに戻るプロセスは、テーブル ルックアップと呼ばれます。
非主キー インデックスに基づくクエリでは、追加のインデックス ツリーをスキャンする必要があります。 したがって、アプリケーションでは主キー クエリの使用を試みる必要があります。記憶領域の観点から見ると、非主キー インデックス ツリーのリーフ ノードには主キーの値が格納されるため、主キー フィールドをできるだけ短くすることをお勧めします。この方法では、非主キー インデックス ツリーのリーフ ノードが小さくなり、非主キー インデックスが占有するスペースが少なくなります。一般に、非主キー インデックスが占有する領域を最小限に抑えるために、自動インクリメント主キーを作成することをお勧めします。
2.インデックスカバレッジ
- WHERE 句の条件が非主キー インデックスの場合、クエリはまず非主キー インデックスを通じて主キー インデックスを見つけます (主キーは非主キー インデックスのリーフ ノードにあります)。キー インデックス検索ツリー) を参照し、主キー インデックスを通じてクエリのコンテンツを見つけます。このプロセスで、主キー インデックス ツリーに戻ることをテーブル ルックアップと呼びます。
- ただし、クエリの内容が主キー値である場合、テーブル検索を行わずにクエリ結果を直接提供できます。言い換えれば、非主キー インデックスは、このクエリのクエリ要件をすでに「カバー」しているため、カバー インデックスと呼ばれます。
-
カバリング インデックスは、プライマリ インデックスへのテーブル ルックアップを行わずに、補助インデックスからクエリ結果を直接取得できます。これにより、検索数が削減されます (補助インデックス ツリーからクラスタード インデックス ツリーに移動する必要がありません)。 IO 操作 (補助インデックス ツリーはディスクから一度により多くのノードをロードできます) により、パフォーマンスが向上します。
3.複合インデックス
複合インデックスとは、テーブルの複数の列にインデックスを付けることを指します。
シナリオ 1:
複合インデックス (a, b) は a、b でソートされます (最初に a でソートされ、a が同じ場合は次に b でソートされます)。したがって、次のステートメントは複合インデックスを直接使用して結果を取得できます (実際には、左端の接頭辞の原則が使用されます):
- select … from xxx where a=xxx;
- select … from xxx where a=xxx order by b;
次のステートメントでは複合クエリを使用できません:
- select … from xxx where b=xxx;
シナリオ 2:
複合インデックス (a、b、c) の場合、次のステートメントは複合インデックスを通じて結果を直接取得できます。
- select … from xxx where a=xxx order by b;
- select … from xxx where a=xxx and b=xxx order by c;
次のステートメントは複合インデックスを使用できず、ファイルソート操作が必要です:
- select … from xxx where a=xxx order by c;
概要:
例として複合インデックス (a、b、c) を使用すると、そのようなインデックスを作成することは、インデックス a、ab、abc を作成することと同じです。 3 つのインデックスを 1 つのインデックスで置き換えることは確かに有益です。インデックスが追加されるたびに、書き込み操作のオーバーヘッドとディスク領域の使用量が増加します。
4.左端のプレフィックス原則
- 上記の複合インデックスの例から、一番左のプレフィックスの原則を理解できます。
-
インデックスの完全な定義だけでなく、左端のプレフィックスを満たす限り、検索を高速化するために使用できます。この左端のプレフィックスは、複合インデックスの左端の N フィールド、または文字列インデックスの左端の M 文字です。 インデックスの「左端のプレフィックス」原則を使用してレコードを検索し、冗長なインデックス定義を回避します。
- したがって、左端のプレフィックスの原則に基づいて、複合インデックスを定義するときはインデックス内のフィールドの順序を考慮することが重要です。評価基準はインデックスの再利用性です。たとえば、(a, b) にすでにインデックスがある場合、通常、a に別のインデックスを作成する必要はありません。
5.インデックス プッシュダウン
MySQL 5.6 では、インデックス プッシュダウン最適化が導入されました。これにより、インデックス トラバーサル中にインデックスに含まれるフィールドに基づいて条件を満たさないレコードをフィルタリングして、テーブル ルックアップの数を削減できます。
CREATE TABLE `test` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'Auto-increment primary key',
`age` int(11) NOT NULL DEFAULT '0',
`name` varchar(255) CHARACTER SET utf8 NOT NULL DEFAULT '',
PRIMARY KEY (`id`),
KEY `idx_name_age` (`name`,`age`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
ログイン後にコピー
-
SELECT * from user where name like 'Chen%' 左端のプレフィックス原則、idx_name_age インデックス
にヒット
-
SELECT * 名前が「Chen%」、年齢が 20 のユーザーから
- バージョン 5.6 より前では、まず名前インデックスに基づいて 2 つのレコードを照合し (この時点では age=20 条件を無視します)、対応する 2 つの ID を見つけてテーブル検索を実行し、次に age=20 に基づいてフィルタリングします。
- バージョン 5.6 以降、インデックス プッシュダウンが導入されました。名前に基づいて 2 つのレコードを照合した後、テーブル検索を実行する前に age=20 条件を無視せず、テーブル検索の前に年齢に基づいてフィルタリングします。このインデックス プッシュダウンにより、テーブル ルックアップの数が減り、クエリのパフォーマンスが向上します。
6.プレフィックスインデックス
インデックスが長い文字シーケンスである場合、大量のメモリを消費し、速度が遅くなる可能性があります。この場合、プレフィックスインデックスを使用できます。値全体にインデックスを付ける代わりに、最初の数文字にインデックスを付けてスペースを節約し、良好なパフォーマンスを実現します。 プレフィックスインデックスはインデックスの最初の数文字を使用します。ただし、インデックスの重複率を減らすには、プレフィックス インデックスの一意性を評価する必要があります。
- まず、現在の文字列フィールドの一意性の比率を計算します: select 1.0*count(distinct name)/count(*) from test
- 次に、さまざまなプレフィックスの一意性の比率を計算します。
-
select 1.0*count(distinct left(name,1))/count(*) from test 名前の最初の文字をプレフィックスインデックスとして使用します
-
名前の最初の 2 文字をプレフィックス インデックスとしてテストから 1.0*count(distinct left(name,2))/count(*) を選択します
- ...
- left(str, n) が大幅に増加しない場合は、プレフィックス インデックスのカットオフ値として n を選択します。
- インデックス変更テーブルの作成 test add key(name(n));
4. 【インデックスの見方】
インデックスを追加した後、それらをどのように表示できますか?または、ステートメントの実行が遅い場合、どのようにトラブルシューティングすればよいですか?
Explain は、インデックスが有効かどうかを確認するためによく使用されます。
遅いクエリのログを取得したら、どのステートメントが遅いかを観察します。ステートメントの前に Explain を追加し、再度実行します。 Explain はクエリにフラグを設定し、ステートメントを実行する代わりに実行計画の各ステップに関する情報を返します。 実行計画と実行の各部分を示す 1 行以上の情報を返します。注文します。
explain によって返される重要なフィールド:
-
type: 検索方法を示します (フルテーブルスキャンまたはインデックススキャン)
- key: 使用されるインデックスフィールド、使用されない場合は null
説明の type フィールド:
- ALL: フルテーブルスキャン
- インデックス: フルインデックススキャン
- 範囲: インデックス範囲スキャン
- 参照: 非固有インデックス スキャン
- eq_ref: ユニークなインデックススキャン
以上がMysqlデータベースインデックスを初心者向けに解説の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。



















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



