


それを念頭に置いて、Text-Generation-WebUI を使用して量子化された Llama 2 LLM をコンピューター上にローカルにロードする方法に関するステップバイステップのガイドを作成しました。
Llama 2 を直接実行することを選択する理由はたくさんあります。プライバシーを考慮してこれを行うものもあれば、カスタマイズを目的とするもの、オフライン機能を目的として行うものもあります。プロジェクトに合わせて Llama 2 を研究、微調整、または統合している場合、API 経由で Llama 2 にアクセスすることは適していない可能性があります。 LLM を PC 上でローカルに実行することのポイントは、サードパーティの AI ツールへの依存を減らし、企業や他の組織に機密データが漏洩する可能性を心配することなく、いつでもどこでも AI を使用できるようになることです。
そうは言っても、Llama 2 をローカルにインストールするためのステップバイステップのガイドから始めましょう。
作業を簡素化するために、Text-Generation-WebUI (GUI で Llama 2 をロードするために使用されるプログラム) のワンクリック インストーラーを使用します。ただし、このインストーラーが機能するには、Visual Studio 2019 Build Tool をダウンロードし、必要なリソースをインストールする必要があります。
ダウンロード:Visual Studio 2019 (無料)
先に進み、ソフトウェアのコミュニティ エディションをダウンロードしてください。 次に、Visual Studio 2019 をインストールし、ソフトウェアを開きます。開いたら、[C++ を使用したデスクトップ開発] のボックスにチェックを入れて、[インストール] をクリックします。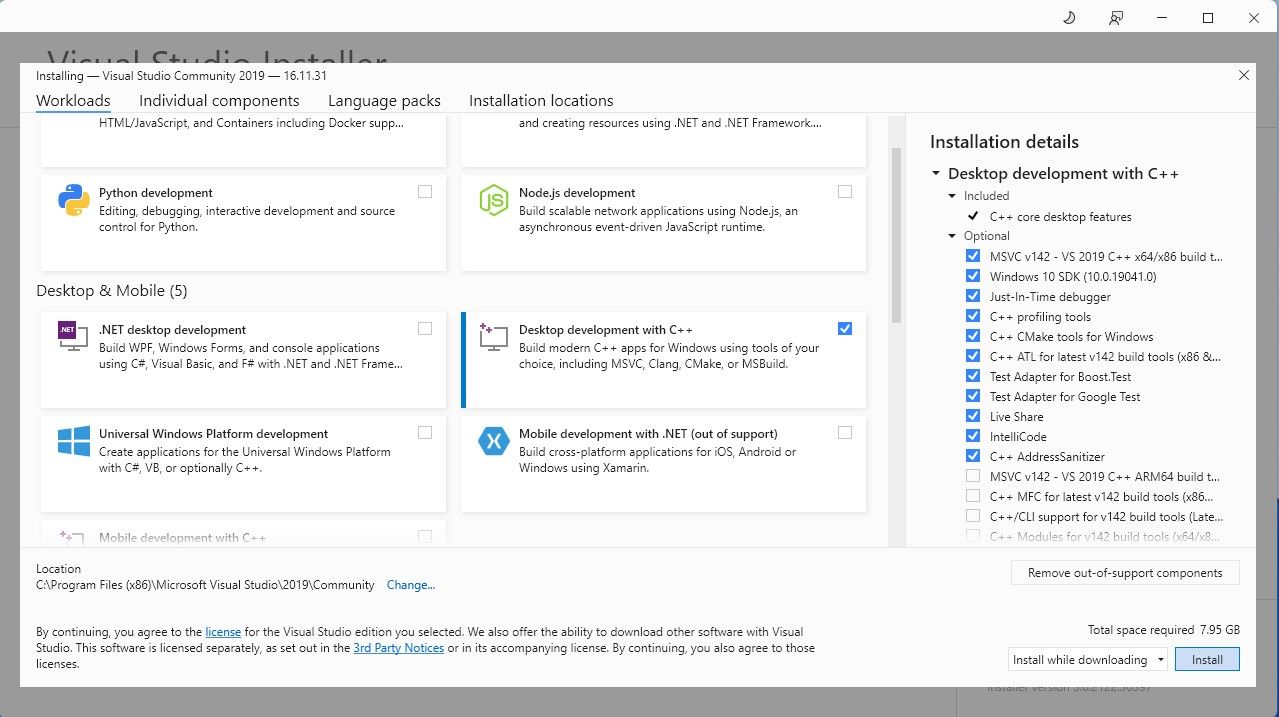
C++ を使用したデスクトップ開発がインストールされたので、Text-Generation-WebUI ワンクリック インストーラーをダウンロードします。
Text-Generation-WebUI のワンクリック インストーラーは、必要なフォルダーを自動的に作成し、Conda 環境と AI モデルを実行するために必要なすべての要件をセットアップするスクリプトです。
スクリプトをインストールするには、[コード] > [コード] をクリックしてワンクリック インストーラーをダウンロードします。 ZIPをダウンロードします。
ダウンロード:Text-Generation-WebUI インストーラー (無料)
ダウンロードしたら、ZIP ファイルを任意の場所に解凍し、解凍したフォルダーを開きます。 フォルダー内で下にスクロールして、オペレーティング システムに適した起動プログラムを探します。適切なスクリプトをダブルクリックしてプログラムを実行します。 Windows を使用している場合は、MacOS の場合は start_windows バッチ ファイルを選択し、Linux の場合は start_macos シェル スクリプトを選択し、start_linux シェル スクリプトを選択します。
ウイルス対策ソフトによってアラートが作成される場合があります。これは大丈夫です。このプロンプトは、バッチ ファイルまたはスクリプトを実行するためのウイルス対策の誤検知です。 「とにかく実行」をクリックします。 ターミナルが開き、セットアップが開始されます。初期段階では、セットアップが一時停止し、使用している GPU を尋ねられます。コンピューターにインストールされている適切なタイプの GPU を選択し、Enter キーを押します。専用のグラフィックス カードがない場合は、[なし (CPU モードでモデルを実行したい)] を選択します。 CPU モードでの実行は、専用 GPU でモデルを実行する場合に比べてはるかに遅いことに注意してください。
 セットアップが完了すると、Text-Generation-WebUI をローカルで起動できるようになります。これを行うには、お好みの Web ブラウザを開いて、指定された IP アドレスを URL に入力します。
セットアップが完了すると、Text-Generation-WebUI をローカルで起動できるようになります。これを行うには、お好みの Web ブラウザを開いて、指定された IP アドレスを URL に入力します。 WebUI を使用する準備が整いました。
WebUI を使用する準備が整いました。
ただし、このプログラムは単なるモデル ローダーです。モデルローダーを起動するために Llama 2 をダウンロードしましょう。
必要な Llama 2 のイテレーションを決定する際には、考慮すべきことがかなり多くあります。これらには、パラメータ、量子化、ハードウェアの最適化、サイズ、使用法が含まれます。これらの情報はすべてモデル名に示されています。
パラメータ: モデルのトレーニングに使用されるパラメータの数。パラメータが大きいほどモデルの機能は向上しますが、パフォーマンスが犠牲になります。使用法: 標準またはチャットのいずれかになります。チャット モデルは、ChatGPT のようなチャットボットとして使用するために最適化されていますが、標準がデフォルトのモデルです。ハードウェアの最適化: モデルを最適に実行するハードウェアを指します。 GPTQ はモデルが専用 GPU で実行するように最適化されているのに対し、GGML は CPU で実行するように最適化されていることを意味します。量子化: モデル内の重みとアクティベーションの精度を示します。推論の場合、q4 の精度が最適です。サイズ: 特定のモデルのサイズを指します。一部のモデルでは配置が異なる場合があり、同じ種類の情報が表示されない場合もありますのでご注意ください。ただし、このタイプの命名規則は HuggingFace Model ライブラリではかなり一般的であるため、理解しておく価値はあります。

この例では、モデルは、専用 CPU を使用したチャット推論用に最適化された 130 億のパラメーターでトレーニングされた中型の Llama 2 モデルとして識別できます。
専用 GPU で実行している場合は GPTQ モデルを選択し、CPU を使用している場合は GGML を選択します。 ChatGPT と同じようにモデルとチャットしたい場合はチャットを選択しますが、モデルの全機能を試してみたい場合は標準モデルを使用してください。パラメーターに関しては、より大きなモデルを使用すると、パフォーマンスは犠牲になりますが、より良い結果が得られることに注意してください。個人的には7Bモデルから始めることをお勧めします。量子化については、推論専用なので q4 を使用します。
ダウンロード:GGML (無料)
ダウンロード:GPTQ (無料)
必要な Llama 2 のイテレーションがわかったので、必要なモデルをダウンロードしてください。
私の場合、これをウルトラブックで実行しているため、チャット用に微調整された GGML モデル、llama-2-7b-chat-ggmlv3.q4_K_S.bin を使用します。
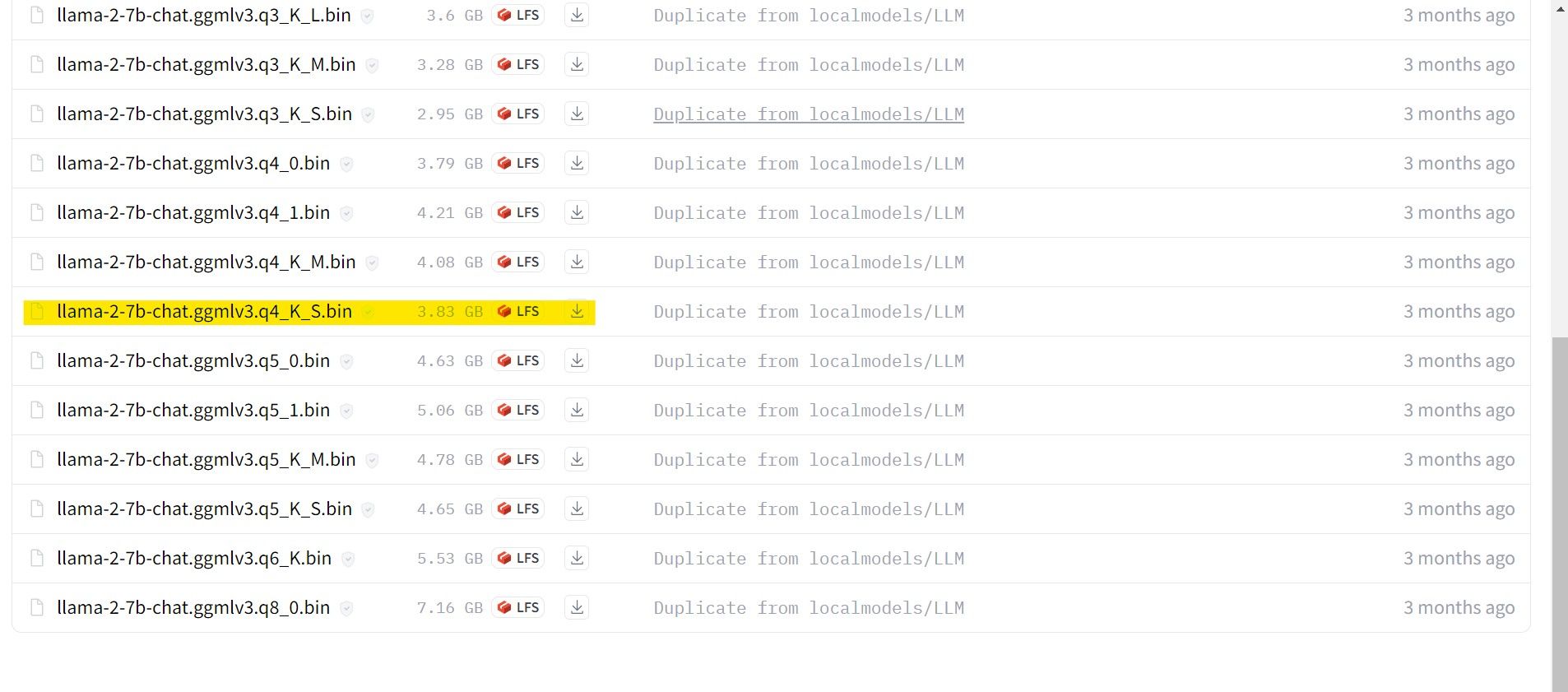
ダウンロードが完了したら、モデルを text-generation-webui-main > に配置します。モデル。

モデルをダウンロードしてモデル フォルダーに配置したので、モデル ローダーを構成します。
次に、構成フェーズを始めましょう。
もう一度、start_(OS) ファイルを実行して Text-Generation-WebUI を開きます (上記の前の手順を参照)。 GUI の上にあるタブで、「モデル」をクリックします。モデルのドロップダウン メニューで更新ボタンをクリックし、モデルを選択します。 次に、モデル ローダーのドロップダウン メニューをクリックし、GTPQ モデルを使用する場合は AutoGPTQ を選択し、GGML モデルを使用する場合は ctransformers を選択します。最後に、[ロード] をクリックしてモデルをロードします。 モデルを使用するには、[チャット] タブを開いてモデルのテストを開始します。
モデルを使用するには、[チャット] タブを開いてモデルのテストを開始します。
おめでとうございます。Llama2 がローカル コンピューターに正常にロードされました。
Text-Generation-WebUI を使用してコンピューター上で Llama 2 を直接実行する方法がわかったので、Llama 以外の LLM も実行できるはずです。モデルの命名規則と、量子化されたモデル (通常は q4 精度) のみが通常の PC にロードできることを覚えておいてください。多くの量子化 LLM が HuggingFace で入手できます。他のモデルを調べたい場合は、HuggingFace のモデル ライブラリで TheBloke を検索すると、利用可能なモデルが多数見つかるはずです。
以上がLlama 2 をローカルにダウンロードしてインストールする方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



