


大規模言語モデル (LLM) は、巨大なテキスト データベースでトレーニングされ、そこで大量の現実世界の知識を取得します。この知識はパラメータに組み込まれており、必要なときに使用できます。これらのモデルの知識は、トレーニングの終了時に「具体化」されます。事前トレーニングの終了時に、モデルは実際に学習を停止します。

モデルを調整するか命令チューニングを実行して、この知識を最大限に活用する方法と、ユーザーの質問により自然に応答する方法をモデルに学習させます。ただし、モデルの知識だけでは不十分な場合があり、モデルは RAG を通じて外部コンテンツにアクセスできますが、微調整を通じてモデルを新しいドメインに適応させることが有益であると考えられます。この微調整は、ヒューマン アノテーターまたは他の LLM によって作成された入力を使用して実行され、モデルは追加の実世界の知識に遭遇し、それをパラメーターに組み込みます。
メカニズムのレベルでは、この相互作用がどのように発生するのかは実際にはわかりません。一部の人によると、この新しい知識にさらされると、モデルは幻覚を引き起こす可能性があります。これは、モデルが既存の知識に基づいていない (またはモデルの事前知識と矛盾する可能性がある) ファクトを生成するようにトレーニングされているためです。また、モデルがどのような外観に遭遇する可能性があるかについての知識もあります (たとえば、トレーニング前のコーパスにあまり出現しないエンティティ)。
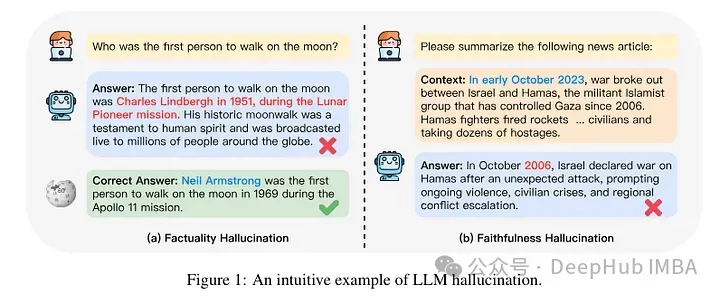
そこで、最近発表された研究では、微調整を通じてモデルに新しい知識が与えられたときに何が起こるかを分析することに焦点を当てました。著者らは、微調整されたモデルに何が起こるのか、新しい知識を獲得した後にモデルがどのように反応するのかを詳しく調べます。
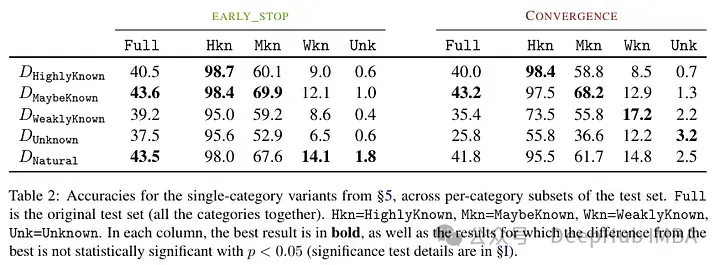
彼らは、微調整した後、知識レベルで例を分類しようとします。新しい例に固有の知識は、モデルの知識と完全に一致しない可能性があります。例は既知の場合もあれば未知の場合もあります。知られているとしても、知名度が高いこともあれば、知られている知識であることもあれば、あまり知られていない知識であることもあります。
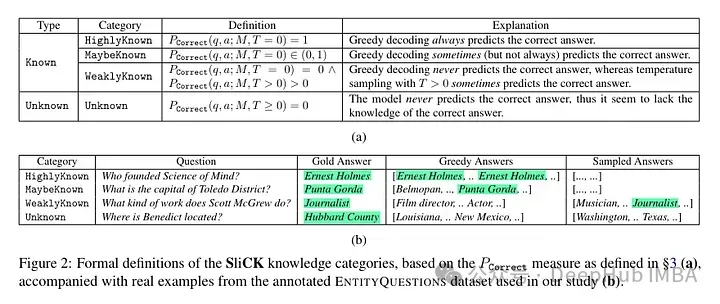
その後、著者はモデル (PaLM 2-M) を使用して微調整しました。各ナッジの例は、事実に関する知識 (主題、関係、オブジェクト) で構成されています。これは、モデルが特定の質問、特定のトリプル (例: 「パリはどこですか?」)、および真実の答え (例: 「フランス」) を使用してこの知識を照会できるようにするためです。言い換えれば、モデルに新しい知識を提供し、これらのトリプルを質問 (質問と回答のペア) に再構築して、その知識をテストします。これらすべての例を上で説明したカテゴリにグループ化し、回答を評価します。
モデルを微調整した後のテスト結果: 不明な事実の割合が高いため、パフォーマンスの低下が生じます (微調整にかかる時間を長くしても補償されません)。
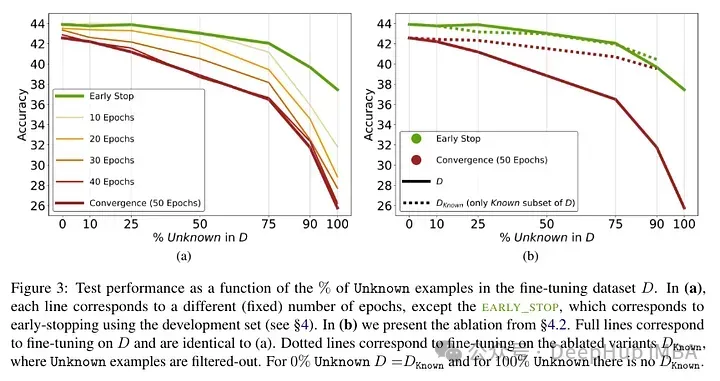
未知の事実は、エポック番号が低い場合はほぼ中立的な影響を与えますが、エポック番号が高い場合はパフォーマンスに悪影響を及ぼします。したがって、未知の例は有害であるように見えますが、その悪影響は主にトレーニングの後期段階に反映されます。以下のグラフは、データセット例の既知および未知のサブセットの微調整期間の関数としてトレーニング精度を示しています。モデルが後の段階で未知の例を学習していることがわかります。
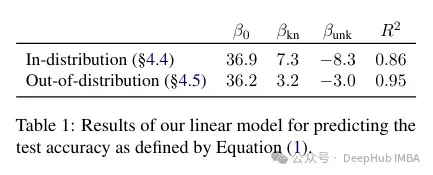
最後に、未知の例は新しい事実の知識を導入する可能性が高いものであるため、その適合率が著しく遅いことは、LLMが微調整を通じて新しい事実の知識を獲得するのに苦労しているのではなく、代わりに次の方法を使用して既存の知識を明らかにすることを学習していることを示唆しています著者らは、この精度が既知の例と未知の例にどのように関連しているか、また線形であるかどうかを定量化しようとしています。結果は、パフォーマンスを損なう未知の例と、パフォーマンスを向上させる既知の例との間に、ほぼ同じくらい強い線形関係があることを示しています (この線形回帰の相関係数は非常に近い)。
この種の微調整は、特定のケースでのパフォーマンスに影響を与えるだけでなく、モデルの知識にも広範囲に影響を与えます。著者らは、配布外 (OOD) テスト セットを使用して、未知のサンプルが OOD のパフォーマンスに有害であることを示しています。著者らによると、これは幻覚の発生にも関連しています。
全体的に、これは本質的に、「[E1] はどこにありますか?」などの未知の例に対する微調整が行われていることを示しています。 「[E2] を設立したのは誰ですか?」など、一見無関係な質問に対する幻覚を促す可能性があります。
もう 1 つの興味深い結果は、よく知られた例ではなく、潜在的に知られている例を使用した場合に最良の結果が得られることです。言い換えれば、これらの例により、モデルは事前の知識をより適切に活用できるようになります (あまりによく知られている事実はモデルに有用な影響を与えません)。
対照的に、不明で明確ではない事実はモデルのパフォーマンスに悪影響を及ぼし、この低下は幻覚の増加に起因します。
この研究は、微調整による新しい知識の獲得が既存の知識に対する幻覚と相関しているという経験的証拠を提示しているため、LLMの知識を更新するために教師付き微調整を使用することのリスクを強調しています。
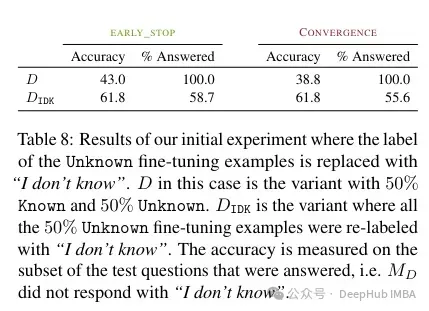
著者によると、この未知の知識はパフォーマンスに悪影響を与える可能性があります(微調整がほとんど役に立たなくなります)。そして、この未知の知識に「私は知らない」というラベルを付けると、この傷を軽減することができます。
LLM は、既存の知識に対する幻覚と相関関係があり、ほとんどの場合、既存の知識を活用することを学習します。 要約すると、微調整中に未知の知識が現れると、モデルに損傷を与える可能性があります。このパフォーマンスの低下は幻覚の増加と関連していました。対照的に、既知の例には有益な効果がある可能性があります。これは、モデルに新しい知識を統合するのが難しいことを示唆しています。つまり、モデルが学習した内容と、新しい知識をどのように使用するかの間に矛盾が生じます。これは、アラインメントと命令のチューニングに関連している可能性があります (ただし、この論文ではこれについては調査しませんでした)。
そのため、特定のドメイン知識を備えたモデルを使用したい場合、論文では RAG を使用するのが最善であると推奨しています。そして、「わかりません」とマークされた結果は、これらの微調整の限界を克服するための他の戦略を見つけることができます。
この研究は非常に興味深いもので、微調整の要素と古い知識と新しい知識の間の矛盾を解決する方法がまだ不明であることを示しています。そのため、微調整の前後で結果をテストします。
以上が微調整によって本当に LLM が新しいことを学習できるようになるのでしょうか: 新しい知識を導入すると、モデルがより多くの幻覚を生成する可能性がありますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。





























![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



