AIxivコラムは、当サイトが学術的・技術的な内容を掲載するコラムです。過去数年間で、このサイトの AIxiv コラムには 2,000 件を超えるレポートが寄せられ、世界中の主要な大学や企業のトップ研究室がカバーされ、学術交流と普及を効果的に促進しています。共有したい優れた作品がある場合は、お気軽に寄稿するか、報告のために当社までご連絡ください。提出電子メール: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
リチャード・サットンは「苦い教訓」で次のように評価しました。「70 年間の人工知能研究から引き出せる最良の結論は、重要な教訓は、計算を利用する一般的な方法が最終的には最も効率的であり、その利点は非常に大きいということです。「セルフ プレイは、計算を完全に利用してスケールアップするために検索と学習の両方を使用するそのような方法の 1 つです。 今年の初めに、カリフォルニア大学ロサンゼルス校 (UCLA) の Gu Quanquan 教授のチームは、追加の微調整データを使用しないセルフプレイ微調整 (SPIN)
を提案しました。セルフプレイのみに依存して、LLM の機能を大幅に向上させることができます。
最近、カーネギーメロン大学(CMU)のGu Quanquan教授のチームとYiming Yang教授のチームは、「Self-Play Preference Optimization (SPPO)
」アライメント技術と呼ばれる手法を開発するために協力しました。この新しい手法は、最適化を目的としています。セルフゲーム フレームワークを通じて大規模な言語モデルの動作を人間の好みに合わせて調整します。左から右に戦って、もう一度あなたの魔法の力を誇示してください!
 論文のタイトル: 言語モデルの調整のためのセルフプレイ設定の最適化
論文のタイトル: 言語モデルの調整のためのセルフプレイ設定の最適化
- 論文のリンク: https://arxiv.org/pdf/2405.00675.pdf
-
テクノロジー背景と課題
大規模言語モデル (LLM) は、人工知能の分野における重要な推進力となりつつあり、その優れたテキスト生成および理解機能によりさまざまなタスクで優れたパフォーマンスを発揮します。 LLM の機能は優れていますが、これらのモデルの出力動作を実際のアプリケーションのニーズとより一致させるには、多くの場合、調整プロセスによる微調整が必要になります。 このプロセスの鍵は、人間の好みや行動規範をよりよく反映するようにモデルを調整することです。一般的な方法には、ヒューマン フィードバックに基づく強化学習 (RLHF) または直接嗜好の最適化 (直接嗜好の最適化、DPO) が含まれます。 ヒューマンフィードバックに基づく強化学習 (RLHF) は、大規模な言語モデルを調整および改良するために報酬モデルを明示的に維持することに依存しています。つまり、たとえば、InstructGPT は、まず人間の嗜好データに基づいて Bradley-Terry モデルに従う報酬関数をトレーニングし、次に近接ポリシー最適化 (PPO) などの強化学習アルゴリズムを使用して大規模な言語モデルを最適化します。昨年、研究者らは Direct Preference Optimization (DPO) を提案しました。 明示的な報酬モデルを維持する RLHF とは異なり、DPO アルゴリズムは暗黙的に Bradley-Terry モデルに従いますが、大規模な言語モデルの最適化に直接使用できます。既存の研究では、DPO を複数回繰り返して使用することで、大規模なモデルをさらに微調整することが試みられています (図 1)。 - 数値スコア。これらのモデルは人間の好みの合理的な近似を提供しますが、人間の行動の複雑さを完全に捉えることはできません。 
これらのモデルは、さまざまな選択間の選好関係が単調で推移的であると仮定することが多い一方で、経験的証拠は人間の意思決定の一貫性と非線形性を示していることがよくあります。たとえば、トベルスキーの研究では、人間の意思決定が影響を受ける可能性があることが観察されています。さまざまな要因が影響し、矛盾が生じます。
SPPOの理論的根拠と手法
两 図 2. 想像上の 2 つの言語モデルは頻繁に再生されます。 これらの文脈で、著者は新しいセルフゲーム フレームワーク SPPO を提案します。これは、2 プレイヤー定数和ゲームを解くための証明可能な保証があるだけでなく、大規模な言語モデルを効率的に微調整します。大規模にスケールします。
具体的には、この記事では RLHF 問題を 2 プレイヤーの通常の合計ゲームとして厳密に定義しています (図 2)。この研究の目的は、平均して常に他のどの戦略よりも好ましい反応をもたらすナッシュ均衡戦略を特定することです。
ナッシュ均衡戦略を近似的に特定するために、著者は、2 プレイヤー ゲームを解くための高レベルのフレームワーク アルゴリズムとして、乗算重みを備えた古典的なオンライン適応アルゴリズムを採用します。
このフレームワークの各ステップ内で、アルゴリズムはセルフゲーム メカニズムを通じて乗算的な重みの更新を近似できます。各ラウンドでは、大規模な言語モデルがモデル合成によって生成された前のラウンドに対して自ら微調整されます。最適化のためのデータと設定モデルのアノテーション。
具体的には、大規模な言語モデルは各ラウンドの各プロンプトに対して複数の応答を生成し、アルゴリズムは各応答の勝率を推定し、それによってさらに微調整することができます。大規模な言語モデルでは、パラメーターにより、勝率の高い応答が表示される確率が高くなります (図 3)。

実験デザインと結果実験では、研究チームはMistral-7Bをベースラインモデルとして採用し、UltraFeからの60,000のプロンプトを使用しました。教師なしトレーニング用の edback データセット。彼らは、自動再生により、モデルが AlpacaEval 2.0 や MT-Bench などの複数の評価プラットフォームでパフォーマンスを大幅に向上できることを発見しました。これらのプラットフォームは、モデルによって生成されたテキストの品質と関連性を評価するために広く使用されています。 SPPO メソッドを通じて、モデルは生成されたテキストの流暢さと精度
が向上するだけでなく、より重要なことに、「人間の価値観や好みに適合する点でパフォーマンスが向上する」ということです。 O 図 4. Alpacaeval 2.0 に対する thesppo モデルの効果は大幅に改善されており、ITERATIVE DPO などの他のベンチマーク手法よりも優れています。
AlpacaEval 2.0 (図 4) のテストでは、SPPO に最適化されたモデルは長さ制御の勝率をベースライン モデルの 17.11% から 28.53% に向上させ、人間の好みの理解が大幅に向上したことを示しました。 。 3 ラウンドの SPPO によって最適化されたモデルは、AlpacaEval2.0 での DPO、IPO、および自己報酬型言語モデル (Self-Rewarding LM) の複数ラウンドの反復よりも大幅に優れています。
さらに、MT-Bench でのモデルのパフォーマンスも、人間のフィードバックによって調整された従来のモデルを上回りました。これは、モデルの動作を複雑なタスクに自動的に適応させる SPPO の有効性を示しています。 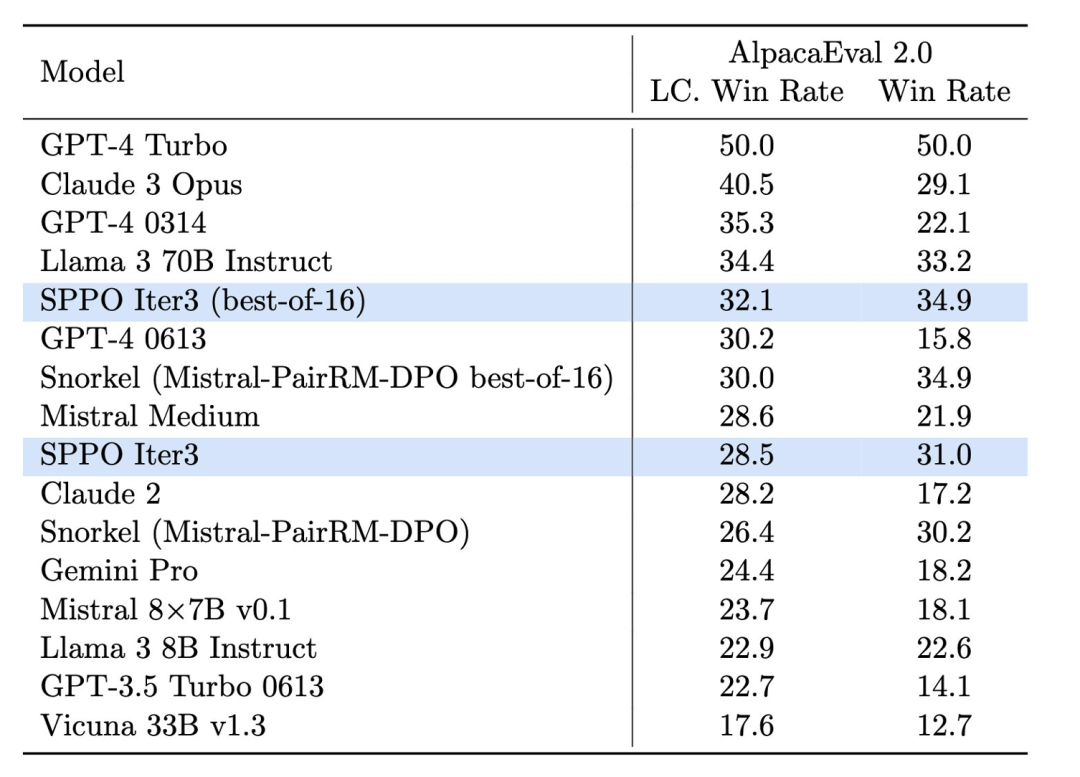
結論と将来の展望
セルフプレイ設定最適化 (SPPO) は、大規模な言語モデルに新しい最適化パスを提供します。これにより、モデルの生成品質が向上するだけでなく、より重要なことに、モデルの生成品質が向上します。人間の好みに合わせたモデルの品質。
テクノロジーの継続的な開発と最適化により、SPPO とその派生テクノロジーは、人工知能の持続可能な開発と社会的応用においてより大きな役割を果たすことが期待されており、よりインテリジェントで責任ある AI システムを構築する道が開かれることになります。 。 以上が人間の好みが支配者です! SPPO アライメント技術により、大規模な言語モデル同士の競合や、それ自体との競合が可能になります。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

































![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



