昨日の面接で、ロングテール関連の質問をしたことがあるか聞かれたので、簡単にまとめてみようと思いました。
自動運転車のロングテール問題とは、自動運転車のエッジケース、つまり、発生確率が低い起こり得るシナリオを指します。認識されているロングテール問題は、現在、単一車両のインテリジェント自動運転車の運用設計領域を制限している主な理由の 1 つです。自動運転の基礎となるアーキテクチャとほとんどの技術的問題は解決されており、残りの 5% のロングテール問題が徐々に自動運転の開発を制限する鍵となってきています。これらの問題には、さまざまな断片的なシナリオ、極端な状況、予測不可能な人間の行動が含まれます。
自動運転におけるエッジシナリオ
「ロングテール」とは、自動運転車(AV)におけるエッジケースを指し、発生確率が低い可能性のあるシナリオです。これらのまれなイベントは、発生頻度が低く、より固有であるため、データセットでは見逃されることがよくあります。 人間は本来、エッジケースに対処するのが得意ですが、AI については同じことが言えません。エッジ シーンの原因となる可能性のある要因には、トラックや突起のある特殊な形状の車両、急旋回する車両、混雑した群衆の中での運転、歩道橋を歩く歩行者、異常気象や照明条件が悪い、傘をさしている人、車に乗っている人、そして移動する箱、木の落下などがあります。道路の真ん中などで
例:
車の前に透明なフィルムを置きます、透明な物体は認識されますか、そして車両は減速しますか? - LiDAR会社Aeyeは挑戦をしました、自動運転はどのように対処しますか?道路の真ん中に浮かぶ風船? L4 の無人運転車は衝突を回避する傾向があり、この場合、不要な事故を避けるために回避行動をとったり、ブレーキをかけたりします。風船は柔らかい物体なので、障害物がなく直接通過できます。
-
ロングテール問題を解決する方法
合成データは大きな概念であり、知覚データ (nerf、カメラ/センサー sim) は、より優れた分野の 1 つにすぎません。業界では、長い間、合成データがロングテール行動シミュレーションにおける標準的な答えとなってきました。合成データ、つまりスパース信号のアップサンプリングは、ロングテール問題に対する最初の解決策の 1 つです。ロングテール能力は、モデルの汎化能力とデータに含まれる情報量の積です。
Tesla ソリューション:
合成データを使用してエッジ シーンを生成し、データ セットを強化します データ エンジンの原理: まず、既存のモデルの不正確さを検出し、次に単体テストに追加されたこのクラス ケースを使用します。また、モデルを再トレーニングするために、同様のケースに関するより多くのデータを収集します。この反復的なアプローチにより、できるだけ多くのエッジ ケースをキャプチャできます。エッジ ケースを作成する際の主な課題は、エッジ ケースの収集とラベル付けのコストが比較的高いことです。もう 1 つは、収集動作が非常に危険であるか、達成が不可能である可能性があることです。
NVIDIA のソリューション:
NVIDIA は最近、「模倣トレーニング」と呼ばれる戦略的アプローチを提案しました (下の図)。このアプローチでは、現実世界のシステム障害ケースがシミュレートされた環境で再現され、自動運転車のトレーニング データとして使用されます。このサイクルは、モデルのパフォーマンスが収束するまで繰り返されます。
このアプローチの目標は、障害シナリオを継続的にシミュレートすることで自動運転システムの堅牢性を向上させることです。シミュレーション トレーニングにより、開発者は現実世界のさまざまな障害シナリオをより深く理解し、解決できるようになります。さらに、大量のトレーニング データを迅速に生成して、モデルのパフォーマンスを向上させることができます。
このサイクルを繰り返すことで、

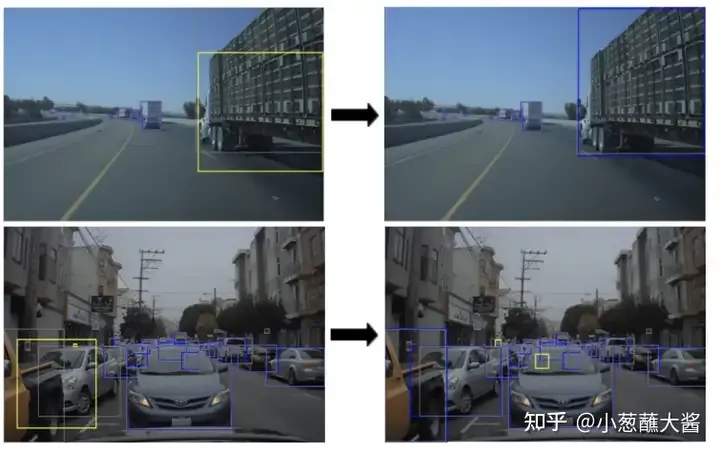
以下の実際のシーンでは、トラックが高すぎる (上) ことと、車両の突き出た部分が後部車両をブロックしている (下) ため、モデルを作成したときに車両のフレームが失われます。 NVIDIA による改善後、モデルはこのエッジ ケースで正しい境界ボックスを生成できるようになります。
いくつかの考え:
Q: 合成データは価値がありますか?
A: ここでの値は 2 つのタイプに分けられます。1 つはテストの有効性、つまり、生成されたシーンで検出アルゴリズムの欠陥が見つかるかどうかをテストすることです。2 つ目は、トレーニングの有効性、つまり、生成されたシーンです。アルゴリズムのトレーニングによってパフォーマンスも効果的に向上できるかどうか。
Q: 仮想データを使用してパフォーマンスを向上させるにはどうすればよいですか?トレーニング セットにダミー データを追加する必要は本当にありますか?これを追加するとパフォーマンスの低下が発生しますか?
A: これらの質問は答えるのが難しいため、トレーニングの精度を向上させるためにさまざまなソリューションが作成されています。
- ハイブリッド トレーニング: パフォーマンスを向上させるために、さまざまな割合の仮想データを実際のデータに追加します。
- 転移学習: 実際のデータを使用してモデルを事前トレーニングし、特定のレイヤーをフリーズしてから、トレーニング用に混合データを追加します。
- 模倣学習: モデルエラーのいくつかのシナリオを設計し、データを生成することで、モデルのパフォーマンスを徐々に改善することも非常に自然です。実際のデータ収集とモデルのトレーニングでは、パフォーマンスを向上させるために、対象を絞った方法でいくつかの補足データも収集されます。
いくつかの拡張:
AI システムの堅牢性を徹底的に評価するには、単体テストに一般的なケースとエッジ ケースの両方を含める必要があります。ただし、一部のエッジ ケースは、既存の実世界のデータセットからは利用できない場合があります。これを行うために、AI 担当者はテストに合成データを使用できます。
その一例は、自動運転車の視覚知能をテストするために使用される合成データセットである ParallelEye-CS です。実世界のデータを使用する場合と比較して、合成データを作成する利点は、各画像のシーンを多次元で制御できることです。
合成データは、プロダクション AV モデルのエッジケースに対する実行可能なソリューションとして機能します。現実世界のデータセットをエッジケースで補完し、異常な事態が発生した場合でも AV が堅牢であることを保証します。また、実際のデータよりも拡張性が高く、エラーが発生しにくく、安価です。
以上が自動運転シナリオにおけるロングテール問題を解決するにはどうすればよいでしょうか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。



















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



