


現在の主要なオブジェクト検出器は、深層 CNN のバックボーン分類器ネットワークを再利用した 2 段階または 1 段階のネットワークです。 YOLOv3 は、入力画像を受け取り、それを等しいサイズのグリッド マトリックスに分割する、よく知られた最先端の 1 段階検出器の 1 つです。ターゲット中心を持つグリッド セルは、特定のターゲットの検出を担当します。
今日私たちが共有したのは、正確なタイトフィットバウンディングボックス予測を達成するために各ターゲットに複数のグリッドを割り当てる新しい数学的手法を提案することです。研究者らはまた、ターゲット検出のための効果的なオフラインのコピーアンドペーストデータ拡張も提案しました。新しく提案された方法は、現在の最先端の物体検出器の一部よりも大幅に性能が優れており、より優れたパフォーマンスが期待されます。
物体検出ネットワークは、画像上の物体の位置を特定し、高精度の境界ボックスを使用して正確にラベルを付けるように設計されています。最近、これを達成するための 2 つの異なる方法が登場しました。最初の方法はパフォーマンスの点で、最も重要な方法は 2 段階の物体検出です。最も代表的なのは、地域畳み込みニューラル ネットワーク (RCNN) とその派生です [高速な R-CNN: 地域提案ネットワークによるリアルタイムの物体検出に向けて]。 ]、[高速 R-CNN]。対照的に、2 番目のオブジェクト検出実装グループは、優れた検出速度と軽量さで知られており、シングルステージ ネットワークと呼ばれます。代表的な例としては、[You Only Look Once: 統合されたリアルタイムのオブジェクト検出]、[SSD:シングルショット マルチボックス検出器]、[密集物体検出のための焦点損失]。 2 段階のネットワークは、対象のオブジェクトを含む可能性のある画像の候補領域を生成する潜在領域提案ネットワークに依存しています。このネットワークによって生成された候補領域には、オブジェクトの対象領域が含まれる場合があります。単一ステージのオブジェクト検出では、検出は完全な前方パスで分類および位置特定と同時に処理されます。したがって、通常、単一ステージのネットワークは軽量で高速で、実装が容易です。

今日の研究は依然としてYOLO手法、特にYOLOv3に準拠しており、複数のネットワークユニット要素を同時に使用してターゲットの座標、カテゴリ、およびターゲットの信頼度を予測できる簡単なハックを提案しています。オブジェクトごとに複数のネットワーク単位要素を使用する背後にある理論的根拠は、複数の単位要素が同じオブジェクト上で動作するようにすることで、厳密に適合する境界ボックスを予測する可能性を高めることです。

マルチグリッド割り当てのいくつかの利点は次のとおりです:
オブジェクト検出器は、オブジェクトのクラスを予測するために 1 つのグリッド セルだけに依存するのではなく、検出しているオブジェクトのマルチビュー マップを提供します。コーディネート。
(b+) ランダムで不確実なバウンディングボックス予測が少なくなります。これは、近くのネットワークユニットが同じオブジェクトカテゴリと座標を予測するように訓練されているため、高精度と再現率を意味します。
(c) グリッドセル間の不均衡を軽減します。対象オブジェクトと対象オブジェクトのないグリッド セル。
さらに、マルチグリッド割り当ては既存のパラメータの数学的利用であり、追加のキーポイント プーリング レイヤーやキーポイントを CenterNet や CornerNet などの対応するターゲットに再結合するための後処理を必要としないため、これは、アンカーフリーまたはキーポイントベースのオブジェクト検出器が達成しようとしていることを実現する、より自然な方法です。マルチグリッドの冗長注釈に加えて、研究者らは、正確な物体検出のための新しいオフラインのコピー&ペーストベースのデータ拡張技術も導入しました。

上の写真には、犬、自転車、車という 3 つのターゲットが含まれています。簡潔にするために、1 つのオブジェクトに対するマルチグリッドの割り当てについて説明します。上の画像は 3 つのオブジェクトの境界ボックスを示しており、犬の境界ボックスの詳細が示されています。下の画像は、犬の境界ボックスの中心に焦点を当てた、上の画像のズームアウト領域を示しています。犬の境界ボックスの中心を含むグリッド セルの左上の座標には数値 0 のラベルが付けられ、中心を含むグリッドを囲む他の 8 つのグリッド セルには 1 から 8 のラベルが付けられます。

これまで、オブジェクトの境界ボックスの中心を含むメッシュがオブジェクトにどのように注釈を付けるかについての基本的な事実を説明してきました。カテゴリと正確にぴったりとフィットする境界ボックスを予測するという困難な作業をオブジェクトごとに 1 つのグリッド セルのみに依存することにより、次のような多くの問題が生じます。オブジェクト中心のグリッド座標がない
(b) GTへのバウンディングボックスの収束が遅い
(c) 予測されるオブジェクトのマルチアングル(角度)ビューの欠如。
そこで、ここで当然の疑問が生じます。「明らかに、ほとんどのオブジェクトには複数のグリッド セルの領域が含まれています。そこで、オブジェクトのカテゴリと座標を予測するために、これらのグリッド セルをさらに割り当てる簡単な数学的方法はありますか?」中央のグリッドセルと一緒に?」この利点としては、(a) 不均衡が軽減されること、(b) 複数のグリッド セルが同じオブジェクトを同時にターゲットにするため、境界ボックスに収束するためのトレーニングが高速化されること、(c) 緊密に適合する境界ボックスの予測が増加することが挙げられます。オブジェクトの単一点ビューではなくマルチビュー ビューを備えた YOLOv3 などのベースの検出器。新しく提案されたマルチグリッド割り当ては、上記の質問に答えることを試みます。
グラウンドトゥルースエンコーディング
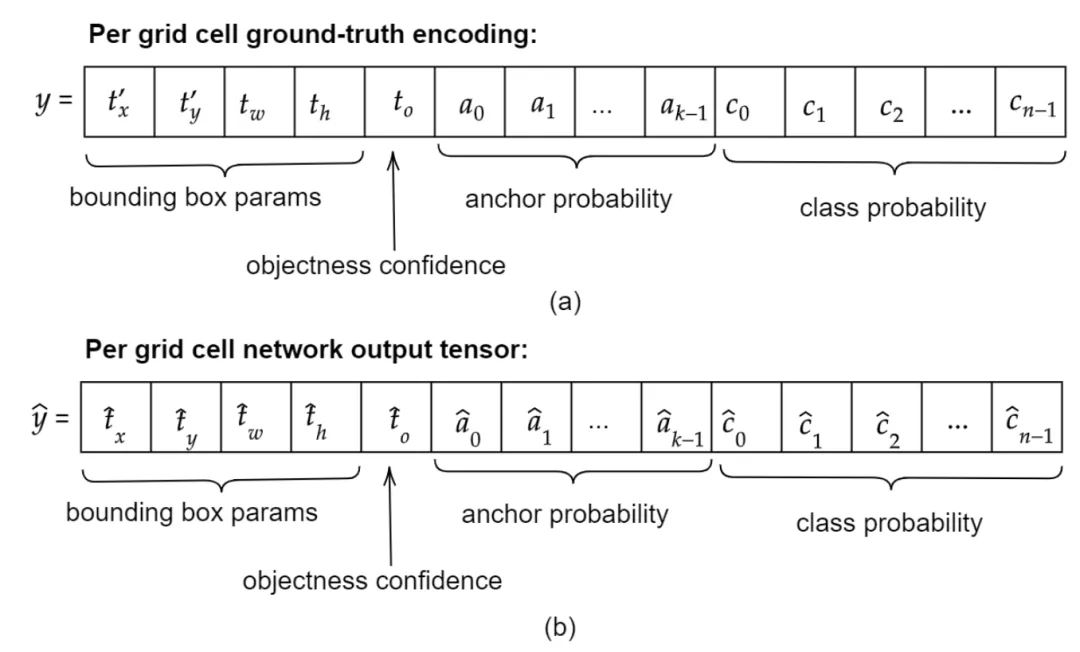
IV. トレーニング
YOLOv3 Convo から 6 つのダークネットを削除ソリューションブロックを使用して軽量化と高速化を実現します。畳み込みブロックには Conv2D+Batch Normalization+LeakyRelu があります。削除されたブロックは、分類バックボーン、つまり Darknet53 からのものではありません。代わりに、3 つのマルチスケール検出出力ネットワークまたはヘッドから、各出力ネットワークから 2 つずつ、それらを削除します。一般に、深いネットワークは良好なパフォーマンスを発揮しますが、深すぎるネットワークはすぐにオーバーフィットしたり、ネットワークの速度が大幅に低下したりする傾向があります。
B. 損失関数
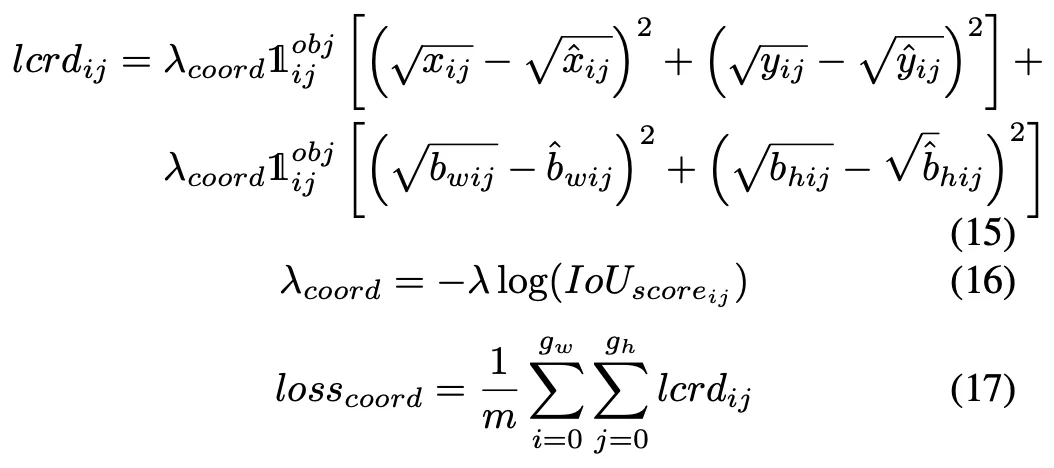
手動トレーニング画像合成の機能以下のように: まず、単純な画像検索スクリプトを使用して、ランドマーク、雨、森林などのキーワードを使用して、Google 画像から背景オブジェクトのない画像、つまり、関心のあるオブジェクトのない画像を何千枚もダウンロードします。次に、トレーニング データセット全体のランダムな q 個の画像から p 個のオブジェクトとその境界ボックスを繰り返し選択します。次に、インデックスを ID として使用して選択された p 個の境界ボックスの可能なすべての組み合わせを生成します。結合されたセットから、次の 2 つの条件を満たす境界ボックスのサブセットを選択します:
ランダムな順序で並べた場合、指定されたターゲット背景画像領域内に収まる必要があり、
オブジェクトが重なり合うことなく、背景画像空間全体または少なくともその大部分を効率的に利用します
以上が正確なオブジェクト検出のためのマルチグリッド冗長境界ボックス注釈の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



