


1.node.jsの役割
I/O の意味 (I/O は、入力/出力の略語です。たとえば、キーボードにテキストを入力し、入力し、画面上のテキスト表示出力を確認します。マウスを動かして、動きを確認します)画面上のマウスの入力、出力など)
Node.js が解決したい問題は (入力の処理、入力、高い同時実行性。たとえば、オンライン ゲームには何百万人ものプレイヤーがいて、何百万もの入力があるなど) (node.js が解決するカテゴリ)以下に適しています: Node.js が最も適しているのは、アプリケーションがネットワーク経由でデータを送受信する必要がある場合です。これには、サードパーティ API、ネットワーク接続されたデバイス、またはブラウザとサーバー間のリアルタイム通信が考えられます。 🎜>
同時実行性の意味 (同時実行性という用語は、同時に発生し、相互作用する可能性のあることを表します。ノードのイベント I/O モデルにより、マルチスレッド非同期 I/O で一般的なインターロックと同時実行性について心配する必要がなくなります。質問です)
デモネットワーク I/O
var http = require('http'),
urls = ['www.baidu.com','www.10jqka.com.cn','www.duokan.com'];
function fetchPage(url){
var start = new Date();
http.get({host:url},function(res){
console.log("Got response from:" + url);
console.log("Request took:",new Date() - start, "ms");
});
}
for(var i=0; i<urls.length; i++){
fetchPage(urls[i]);
}
ターミナルでノードnode.js
を実行します
出力:

2 つの出力時間が異なることがわかります。 DNS リクエストの解決時間、サーバービジー手順など、さまざまな要因の影響を受けます。
JavaScript がイベント駆動型言語である理由
JavaScript は、もともとドキュメント オブジェクト モデル (DOM) に関連付けられたイベントを中心に設計されています。開発者はイベントが発生したときに何かを行うことができます。これらのイベントには、ユーザーによる要素のクリック、ページの読み込みの完了などが含まれます。イベントを使用すると、開発者はイベントの発生時にトリガーされるイベント リスナーを作成できます。
2. コールバック
1. コールバックとは
2. コールバックの分析
コールバックは、関数を引数として別の関数に渡すことを指し、通常は最初の関数が完了した後に呼び出されます。
例: jquery の Hide() メソッドなど、
JSコード
1,$("p").hide('slow');
2,$("p").hide('slow',function(){alert("The paragraph is now hidden")});
1 コールバックは必要ありません
2. 段落が非表示になるとコールバックが呼び出され、アラート プロンプトが表示されます。
したがって、コールバックを含むコードとコールバックを含まないコードの違いがわかります
JSコード
$("p").hide('slow');
alert("The paragraph is now hidden");//1
$("p").hide('slow',function(){alert("The paragraph is now hidden")});//2
2. コールバックがあり、非表示が完了した後、実行はalert
になります。
コールバックを分析しています
JSコード
function haveBreakfast(food,drink,callback){
console.log('Having barakfast of' + food + ', '+ drink);
if(callback && typeof(callback) === "function"){
callback();
}
}
haveBreakfast('foast','coffee',function(){
console.log('Finished breakfast. Time to go to work!');
});
出力:
Having barakfast of foast,coffee Finished breakfast. Time to go to work!
haveBreakfast 関数は、食べられたものをコンソールに記録し、パラメータとして渡されたコールバック関数を呼び出します。
Node.js でコールバックを使用する方法
JSコード
var fs = require('fs');
fs.readFile('somefile.txt','utf8',function(err,data){
if(err) throw err;
console.log(data);
});
1. fs (ファイルシステム) モジュールはスクリプトで使用するために要求されます
2. ファイル システム上のファイル パスを fs.readFile メソッド
の最初のパラメータとして指定します。
3. 2 番目のパラメータは utf8 で、ファイル
のエンコーディングを表します。
4. fs.readFile メソッド
の 3 番目のパラメーターとしてコールバック関数を指定します。
5. コールバック関数の最初のパラメータは err で、ファイル
の読み取り時に返されたエラーを保存するために使用されます。
6. コールバック関数の 2 番目のパラメータは、ファイルの読み取りによって返されたデータを保存することです。
7. ファイルが読み取られると、コールバックが呼び出されます
8. err が true の場合、エラーがスローされます
9. err が false の場合、ファイルのデータを使用できます
10. この例では、データがコンソールに記録されます。
もう 1 つの http モジュールは、開発者が http クライアントとサーバーを作成できるようにします。
var http = require('http');
http.get({host:'shapeshed.com'},function(res){
console.log("Got response:" + res.statusCode);
}).on('error',function(e){
console.log("Got error:" + e.message);
});
1. スクリプトで使用する http モジュールをリクエストします
2. http.get() メソッドに 2 つのパラメータを指定します
3. 最初のパラメータはオプションオブジェクトです。この例では、shapeshed.com
のホームページをリクエストしています。
4. 2 番目のパラメータは、応答をパラメータとして受け取るコールバック関数です
5. リモート サーバーが応答を返すと、コールバック関数がトリガーされます。
6. エラーが発生した場合は、応答ステータス コードをコールバック関数に記録します。
次に、発生する 4 つの異なる I/O 操作を見てみましょう。それらはすべてコールバックを使用します
var fs = require('fs'),
http = require('http');
http.get({host:'www.baidu.com'},function(res){
console.log("baidu.com");
}).on('error',function(e){
console.log("Got error:" + e.message);
});
fs.readFile('somefile.txt','utf8',function(err,data){
if(err) throw err;
console.log("somefile");
});
http.get({host:'www.duokan.com'},function(res){
console.log("duokan.com");
}).on('error',function(e){
console.log("Got error:" + e.message);
});
fs.readFile('somefile2.txt','utf8',function(err,data){
if(err) throw err;
console.log("somefile2");
});
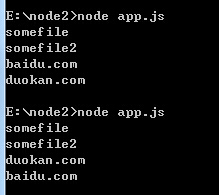
我们能知道哪个操作先返回吗?
猜测就是从磁盘上读取的两个文件先返回,因为无需进入网络,但是我们很难说哪个文件先返回,因为我们不知道文件的大小。对于两个主页的获取,脚本要进入网络,而响应时间则依赖于许多难以预测的事情,Node.js进程在还有已经注册的回调尚未触发之前将不会退出。回调首先解决不可预测性的方法,他也是处理并发(或者说一次做超过一件事情)的高效方法。
下面是我执行的结果
同步和异步代码
先看代码,同步(或者阻塞)代码
Js代码
function sleep(milliseconds){
var start = new Date().getTime();
while((new Date().getTime() -start) < milliseconds){
}
}
function fetchPage(){
console.log('fetching page');
sleep(2000);
console.log('data returned from requesting page');
}
function fetchApi(){
console.log('fetching api');
sleep(2000);
console.log('data returned from the api');
}
fetchPage();
fetchApi();
当脚本运行时,fetchPage()函数会被调用,直到它返回之前,脚本的运行是被阻塞的,在fetchPage()函数返回之前,程序是不能移到fetchApi()函数中的。这称为阻塞操作。
Node.js几乎从不使用这种编码风格,而是异步地调用回调。
看下下面编码,,
Js代码
var http = require('http');
function fetchPage(){
console.log('fetching page');
http.get({host:'www.baidu.com',path:'/?delay=2000'},
function(res){
console.log('data returned from requesting page');
}).on('error',function(e){
console.log("There was an error" + e);
});
}
function fetchApi(){
console.log('fetching api');
http.get({host:'www.baidu.com',path:'/?delay=2000'},
function(res){
console.log('data returned from requesting api');
}).on('error',function(e){
console.log("There was an error" + e);
});
}
fetchPage();
fetchApi();
允许这段代码的时候,就不再等待fetchPage()函数返回了,fetchApi()函数随之立刻被调用。代码通过使用回调,是非阻塞的了。一旦调用了,两个函数都会侦听远程服务器的返回,并以此触发回调函数。
注意这些函数的返回顺序是无法保证的,而是和网络有关。
事件循环
Node.js使用javascript的事件循环来支持它所推崇的异步编程风格。基本上,事件循环使得系统可以将回调函数先保存起来,而后当事件在将来发生时再运行。这可以是数据库返回数据,也可以是HTTP请求返回数据。因为回调函数的执行被推迟到事件反生之后,于是就无需停止执行,控制流可以返回到Node运行时的环境,从而让其他事情发生。
Node.js经常被当作是一个网络编程框架,因为它的设计旨在处理网络中数据流的不确定性。促成这样的设计的是事件循环和对回调的使用,他们似的程序员可以编写对网络或I/O事件进行响应的异步代码。
需要遵循的规则有:函数必须快速返回,函数不得阻塞,长时间运行的操作必须移到另一个进程中。
Node.js所不适合的地方包括处理大量数据或者长时间运行计算等。Node.js旨在网络中推送数据并瞬间完成。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



