

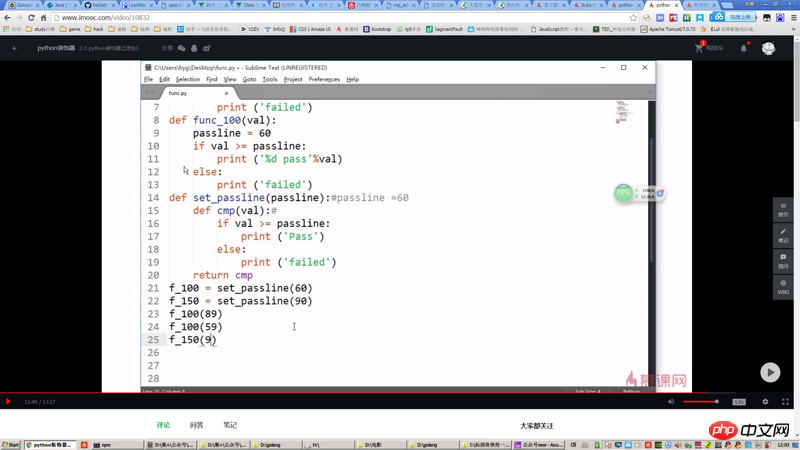
Après avoir regardé l'explication de la fonction des fermetures dans la vidéo, je ne comprends toujours pas. Par exemple, le code dans la capture d'écran peut être implémenté en ajoutant un paramètre passline à la fonction cmp.
Qui peut donner un meilleur exemple pour illustrer le rôle de la clôture ?




























![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




延长局部变量的生命周期,封装私有变量
保存变量 大部分时候我是用它来替代全局变量 避免造成变量污染
闭包解决的问题:基于
JS的词法作用域规则,其访问是一直向上查找作用域,直到全局作用域。而想直接访问某个作用域可通过闭包解决。bar词法作用域可以访问foo内部作用域,foo执行后返回bar,最后赋值给baz,可以获取并访问foo内部作用域,只是标识符不同而已。该代码就使用了闭包,可以说写
JS代码处处可见闭包,使用闭包还有一个好处就是引用的作用域不会被垃圾回收处理,当然不合理的使用会耗内存。闭包用来增加变量(能访问某作用域,自然能加变量)或者延长其生命周期(作用域被引用,自然会延长)
第一个循环是声明了几个函数,共享全局
i变量(变量和函数声明都提升了)。第二个循环是定义了几个立即执行函数,又传递了
i值,故每个i值都有自己的作用域。这个是一个比较好的例子,闭包+循环,只是这个比较特别,闭包访问自身的作用域。
当然最能体现闭包思想的是模块,返回一个方法,该方法就相当引入了一个作用域。
闭包:就是一个获取并访问某个作用域,可在外访问或者自身内部访问。
最大的两个作用
读取函数内部变量
让变量值始终保持在内存里
第一个不赘述,看第二个,举例
result实际上就是闭包f2函数。它一共运行了两次,第一次的值是999,第二次的值是1000。这证明了,函数f1中的局部变量n一直保存在内存中,并没有在f1调用后被自动清除。
为什么会这样呢?原因就在于f1是f2的父函数,而f2被赋给了一个全局变量,这导致f2始终在内存中,而f2的存在依赖于f1,因此f1也始终在内存中,不会在调用结束后,被垃圾回收机制(garbage collection)回收。
这段代码中另一个值得注意的地方,就是"nAdd=function(){n+=1}"这一行,首先在nAdd前面没有使用var关键字,因此nAdd是一个全局变量,而不是局部变量。其次,nAdd的值是一个匿名函数(anonymous function),而这个匿名函数本身也是一个闭包,所以nAdd相当于是一个setter,可以在函数外部对函数内部的局部变量进行操作
管理私有变量和私有方法,将对变量(状态)的变化封装在安全的环境中
将代码封装成一个闭包形式,等待时机成熟的时候再使用,比如实现柯里化和反柯里化
需要注意的:
由于闭包内的部分资源无法自动释放,容易造成内存泄露 解决方法是,在退出函数之前,将不使用的局部变量全部删除。
闭包会在父函数外部,改变父函数内部变量的值。所以,如果你把父函数当作对象(object)使用,把闭包当作它的公用方法(Public Method),把内部变量当作它的私有属性(private value),这时一定要小心,不要随便改变父函数内部变量的值。
如果我说,
set_passLine其实就是两个参数的函数,你能接受吗?这个和函数
在功能上是等价的,但前者,不必一次性给出所有参数来调用。
另外,第一种写法可以实现和类一样的功能:
虽然这些都是相同功能的不同实现。但是人们越来越发现函数式编程比其他的方式更好,更好的意思是指在代码量上更好,更清晰(但是对程序员的要求越来越高)。
给个链接吧,但是是我用 js 写的:http://zonxin.github.io/post/...
P.S.
面向对象的编程就是把,所有的“物体”看为对象,编程就是,使用对象模拟“物体”的行为,即模拟某个“世界”的运行。
而函数式编程,只关心“物体”的初始状态和“物体”经过函数之后的最终状态,而不必关心其中的过程,编程就是处理这些函数的复合。
我一直是这么理解的:保护内部变量,通过暴漏API进行操作。
以上是个人理解
避免变量污染,但如果是在ES6中,用let和const就可以解决这个问题了
初级水平来看
只知道1、可以访问到局部变量
2、可以一直保存在内存中
所以使用频率不宜过高,会造成内存泄漏
答个我印象深刻的
偏函数