10000 contenu connexe trouvé

Qu'est-ce que la synchronisation maître-esclave MySQL ?
Présentation de l'article:La synchronisation maître-esclave Mysql signifie sauvegarde. La bibliothèque maître (Maître) synchronise les écritures de sa propre bibliothèque avec sa bibliothèque esclave (Esclave) Lorsque des conditions imprévisibles se produisent dans la bibliothèque maître et que l'ensemble du serveur ne peut pas être utilisé, en raison de problèmes. également une copie des données dans la base de données esclave, afin que les données puissent être restaurées rapidement sans provoquer ni réduire la perte de données.
2020-10-05
commentaire 0
5345
php 读取表结构自动生成php类
Présentation de l'article:: php 读取表结构自动生成php类:平时写项目的时候经常会碰到操作数据库,每次操作数据库的时候最麻烦的就是要写一个表映射的类,根据规律总结写了一个自动生成的小demo:
2016-07-28
commentaire 0
1158
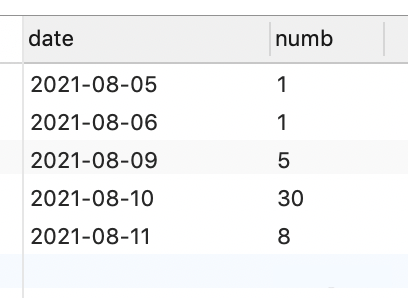
Comment générer des dates consécutives et des affectations de variables dans MySQL
Présentation de l'article:1. Description de la date continue de production : principalement utilisé pour afficher certaines données statistiques selon l'ordre chronologique ; si les données de la base de données contiennent des données pour le jour suivant, mais que les statistiques doivent être affichées tous les jours, même si elles sont 0, alors un calendrier doit être généré. Pour utiliser : interroger les données de la base de données : SELECTDATE_FORMAT(create_time,'%Y-%m-%d')ASdate,COUNT(1)ASnumbFROMqc_taskWHEREcreate_time>=DATE_SUB(CURDATE(),INTERVAL1MONTH)anddepartment_id.
2023-06-02
commentaire 0
1555
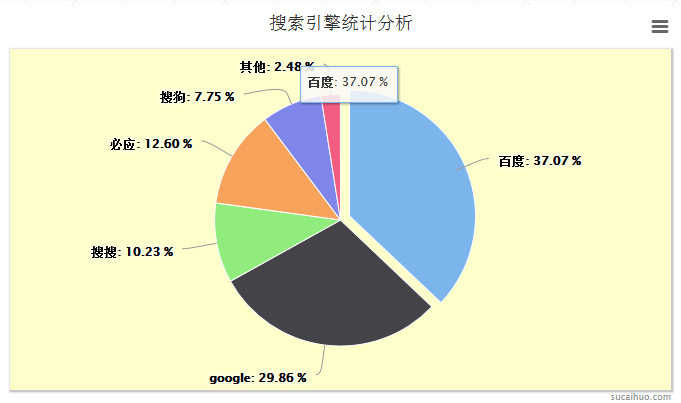
PHP mysql Highcharts génère un camembert_jquery
Présentation de l'article:Cet article sera basé sur la réalité, utilisera PHP pour lire les données dans la table de données Mysql et affichera les données obtenues vers le JS frontal selon les besoins, puis appellera la bibliothèque de graphiques Highcharts via la configuration pour générer un diagramme circulaire.
2016-05-16
commentaire 0
1821

Il existe plusieurs types de staticisation php
Présentation de l'article:Il existe deux types de staticisation en PHP, à savoir : 1. La staticisation pure est divisée en staticisation partielle et statique complète. La staticisation pure consiste à enregistrer la page dynamique générée par PHP en tant que page HTML statique. accès pseudo-statique ou dynamique, essentiellement des données générées dynamiquement pour faciliter l’inclusion dans les moteurs de recherche.
2022-03-09
commentaire 0
2224

Astuces | Une bibliothèque Python qui a l'air tellement fausse qu'elle m'a fait craquer. .
Présentation de l'article:En parcourant GitHub aujourd'hui, j'ai trouvé une bibliothèque très impressionnante - Faker. Cette bibliothèque peut générer de fausses informations, notamment des informations personnelles ou des données de test. Si nous devons utiliser de fausses données pour des tests pendant le développement, cette bibliothèque entre en jeu. pratique ~
2023-08-10
commentaire 0
1117

Comment utiliser PHP pour la visualisation de données et la génération de graphiques
Présentation de l'article:Comment utiliser PHP pour implémenter la visualisation de données et la génération de graphiques La visualisation de données et la génération de graphiques jouent un rôle important dans l'analyse et la présentation modernes des données. En tant que langage de script côté serveur populaire, PHP fournit une multitude d'outils et de bibliothèques pour la visualisation de données et la génération de graphiques. Cet article expliquera comment utiliser PHP pour réaliser cette fonction et fournira des exemples de code. Avant de commencer, nous devons installer une bibliothèque pour générer des graphiques. Chart.js est un JavaScript puissant et facile à utiliser
2023-09-05
commentaire 0
1356

Une plongée approfondie dans le fonctionnement des générateurs de nombres aléatoires dans numpy
Présentation de l'article:Compréhension approfondie du générateur de nombres aléatoires dans NumPy Introduction : NumPy (NumericalPython) est l'une des bibliothèques de calcul scientifique importantes de Python, fournissant un grand nombre d'opérations numériques et de fonctions d'opérations matricielles. Parmi eux, la génération de nombres aléatoires est une partie importante de la bibliothèque NumPy. Elle fournit un support puissant pour les simulations, les expériences et l'analyse de données en calcul scientifique, et peut nous aider à générer des nombres aléatoires qui obéissent à diverses distributions. Cet article fournira une compréhension approfondie du générateur de nombres aléatoires dans la bibliothèque NumPy et fournira
2024-01-03
commentaire 0
534

Comment utiliser la méthode thinkphp u
Présentation de l'article:La méthode u de thinkphp est utilisée pour terminer l'assemblage des adresses URL. Sa fonctionnalité est qu'elle peut générer automatiquement l'adresse URL correspondante en fonction du mode et des paramètres d'URL actuels. Sa syntaxe d'utilisation est "U('address','parameter','. pseudo-statique', 'Sauter s'il faut', 'Afficher le nom de domaine');".
2021-12-16
commentaire 0
2381

A quoi sert la méthode PHP U ?
Présentation de l'article:La méthode PHP U est utilisée pour assembler l'adresse URL. Elle se caractérise par la génération automatique de l'adresse URL correspondante en fonction du mode et des paramètres d'URL actuels. Son format de syntaxe est "U('adresse','paramètre','pseudo-statique. ',' S'il faut sauter','afficher le nom de domaine');".
2020-07-03
commentaire 0
2738

Comment utiliser Faker avec CakePHP ?
Présentation de l'article:CakePHP est un framework PHP populaire largement reconnu pour la création d'applications Web. L'utilisation de l'outil Faker dans CakePHP nous permet de générer des données aléatoires plus facilement, simplifiant ainsi le développement et les tests. Cet article explique comment utiliser Faker dans les applications CakePHP. 1. Qu’est-ce que Faker ? Faker est une bibliothèque PHP permettant de générer des données pseudo-aléatoires. Nous pouvons l'utiliser pour simuler certaines données de nature aléatoire, telles que les noms d'utilisateur, les adresses, les e-mails.
2023-06-03
commentaire 0
1095

Avant d'apprendre la technologie Big Data, comprenez les caractéristiques et les scénarios d'application de MySQL et Oracle.
Présentation de l'article:Avant d'apprendre la technologie du Big Data, comprenez les caractéristiques et les scénarios d'application de MySQL et Oracle Introduction Avec l'avènement de l'ère du Big Data, la technologie du Big Data est progressivement devenue le centre d'intérêt de diverses industries. Dans l’écosystème technologique du Big Data, les bases de données jouent un rôle très important. Parmi les bases de données, MySQL et Oracle sont deux bases de données relationnelles très connues avec un large éventail de scénarios et de fonctionnalités d'application. Cet article présentera respectivement les caractéristiques et les scénarios d'application de MySQL et Oracle, et fournira quelques exemples de code. 1. MySQL
2023-09-09
commentaire 0
1345

Stratégie de sécurité pour la gestion des sessions PHP
Présentation de l'article:Pour assurer la sécurité de la gestion des sessions PHP, les politiques de sécurité suivantes doivent être mises en œuvre : Utiliser des cookies sécurisés (transport HTTPS, avec les flags HttpOnly et Secure) Mettre en place un cycle de vie de session raisonnable Utiliser la régénération de session Empêcher le détournement de session Interdire la falsification de requêtes intersites (CSRF) , Par exemple en utilisant un jeton anti-CSRF pour stocker les données de session en utilisant une base de données au lieu du stockage de fichiers
2024-05-02
commentaire 0
1180

Sans serveur et basées sur l'IA, les capacités principales de la base de données Alibaba Cloud ont été entièrement mises à niveau !
Présentation de l'article:Le 1er novembre 2023, Alibaba Cloud Yaochi Database a annoncé lors de la conférence Hangzhou Yunqi qu'elle avait entièrement réalisé le sans serveur et qu'elle avait accédé avec succès aux capacités de grands modèles telles que Tongyi, améliorant considérablement le niveau unique et intelligent de la base de données. Dans le même temps, la série PolarDB AlwaysOn a également lancé trois mises à niveau majeures, et le premier assistant intelligent de données, DMSCopilot, a également fait des débuts époustouflants. Li Feifei, responsable de la division produits de base de données d'Alibaba Cloud, a déclaré lors de la réunion : « Grâce au sans serveur et à l'IA, les bases de données cloud natives accélèrent leur évolution vers une plate-forme de données intelligente à guichet unique. Li Feifei a déclaré que la plate-forme de données devrait ressembler à cela. "éléments de base". Tout aussi pratiques et faciles à utiliser, et utilisant la technologie sans serveur pour réaliser
2023-11-01
commentaire 0
1286

Comment créer un nuage de mots en python
Présentation de l'article:Deux bibliothèques de classes Python sont nécessaires pour générer des nuages de mots chinois en Python : jieba : outil de segmentation de mots chinois, wordcloud : outil de génération de nuages de mots sous Python. Définissez ensuite les paramètres dans le code en fonction de vos propres besoins. Le paramètre isCN peut annuler la segmentation des mots chinois.
2019-06-11
commentaire 0
7196

Base de données analytique MySql : Comment utiliser MySQL pour mettre en œuvre l'analyse du Big Data
Présentation de l'article:Avec le développement rapide d’Internet et de l’Internet mobile, la croissance explosive du volume de données est devenue la norme. Comment analyser rapidement de grandes quantités de données pour obtenir des informations précieuses est devenu un besoin urgent pour les entreprises et les particuliers. À cet égard, la base de données analytique MySql a vu le jour. Cet article explique comment utiliser MySQL pour mettre en œuvre l'analyse du Big Data. 1. Qu'est-ce qu'une base de données analytique ? Dans le passé, les bases de données traditionnelles étaient principalement basées sur le traitement des transactions, c'est-à-dire des opérations telles que la modification, l'ajout, la suppression et l'interrogation d'une certaine ligne d'enregistrements. Si la taille de la base de données
2023-06-16
commentaire 0
1852


Comment lire les données de la base de données et générer un affichage graphique en php
Présentation de l'article:Avec le développement rapide d’Internet, l’analyse et la visualisation des données sont devenues des moyens essentiels permettant aux entreprises et aux particuliers d’analyser les données présentes sur les sites Web et les applications. En tant que langage de script côté serveur populaire, PHP est devenu le premier choix de nombreux développeurs Web. Dans cet article, nous verrons comment lire les données d'une base de données et générer un affichage graphique à l'aide de PHP. 1. PHP se connecte à la base de données Avant de générer des graphiques, nous devons nous connecter à la base de données et obtenir les données requises. PHP prend en charge une variété de bases de données, notamment MySQL, PostgreSQL et SQLit
2023-04-21
commentaire 0
1577
Développement de compte public WeChat : convertissez les connexions longues en liens courts via un jeton d'accès
Présentation de l'article:Il y a souvent des liens très longs dans le processus de développement des comptes publics WeChat. Si vous générez un code QR à ce moment-là, le processus de reconnaissance sera lent pendant le processus de numérisation. S'il est stocké dans la base de données, le champ. la longueur de la base de données devra être définie. Une longueur très longue suffira, il est donc de plus en plus important de convertir les liens longs en liens courts.
2018-05-26
commentaire 1
10153

People's Daily Online·People's Data Une base de données de 300 millions d'IA est officiellement ouverte au marché
Présentation de l'article:Récemment, la base de données de corpus sémantique fournie par People's Daily Online et People's Data pour le marché de l'IA a officiellement fourni des services au marché. Depuis le début de cette année, les grands modèles d'IA sont devenus extrêmement populaires, ayant un impact profond sur le développement économique et social, et étant également confrontés à des défis complexes. À l'heure actuelle, les données de corpus nécessaires au développement de l'IA sont encore insuffisantes et le coût d'acquisition est souvent élevé. Les données sont pour la plupart de « petits échantillons », et la quantité de données ne peut pas répondre aux exigences de l'apprentissage profond de l'IA. Afin de promouvoir le développement en profondeur de grands modèles d'IA, basés sur les avantages des ressources médiatiques du Quotidien du Peuple et du Quotidien du Peuple en ligne, People's Data a créé un corpus sémantique de données d'actualité, de données de questions et réponses, etc., avec la quantité de données pertinentes atteignant près de 300 millions de pièces. Ce corpus sémantique permet une production et une personnalisation de haute qualité pour des scénarios d'application tels que les grands modèles d'intelligence artificielle, l'intelligence artificielle générale et l'Internet intelligent.
2023-10-21
commentaire 0
538

