


Lorsque l'IA résout des problèmes mathématiques, la vraie pensée est en fait le « calcul mental » en secret ?
De nouvelles recherches menées par l'équipe de l'Université de New York ont révélé que même si l'IA n'est pas autorisée à écrire des étapes et est remplacée par des "..." dénués de sens, ses performances sur certaines tâches complexes peuvent être grandement améliorées !
Le premier auteur Jacab Pfau a déclaré : Tant que vous dépensez de la puissance de calcul pour générer des jetons supplémentaires, vous pouvez apporter des avantages, quel que soit le jeton que vous choisissez.
 Images
Images
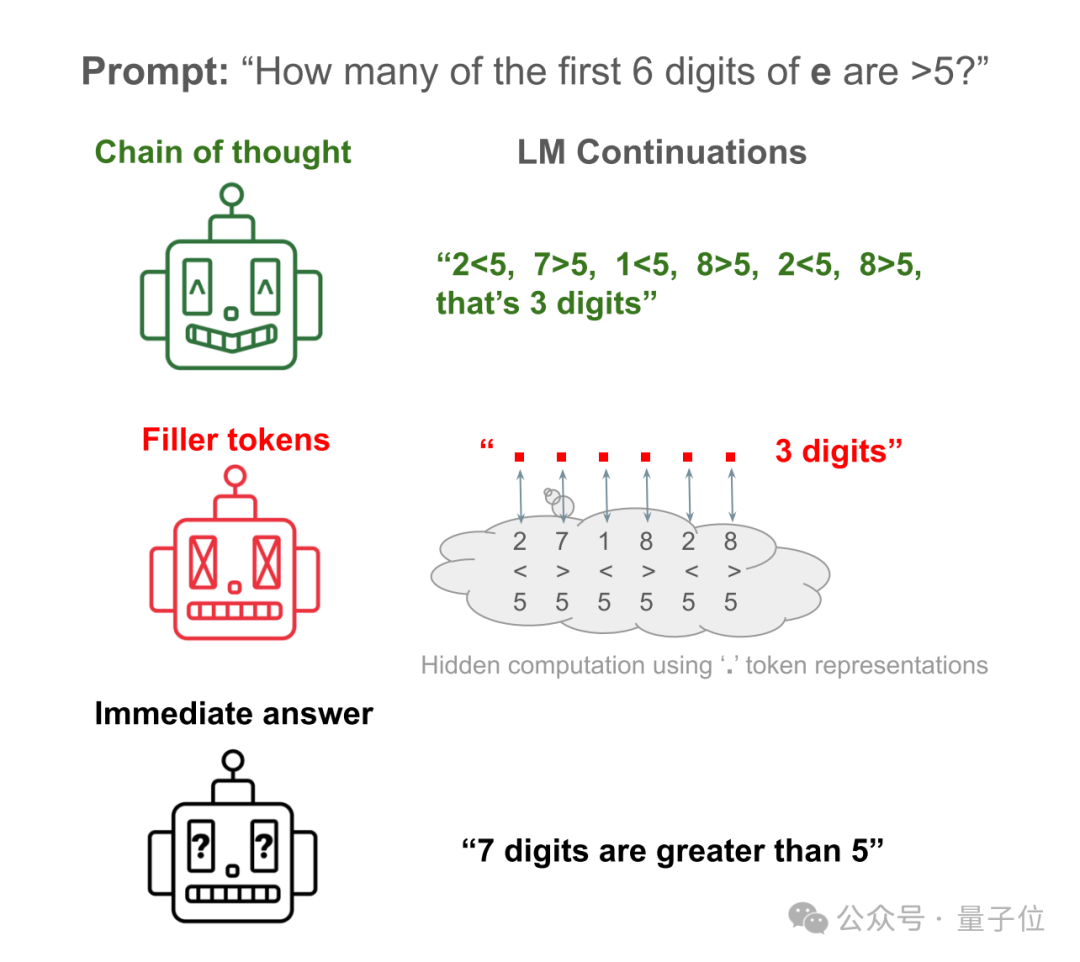
Par exemple, laissez Llama 34M répondre à une question simple : combien des 6 premiers chiffres de la constante naturelle e sont supérieurs à 5 ?
La réponse directe de l'IA revient presque à faire un gâchis. Elle ne compte que les 6 premiers chiffres et en compte en réalité 7.
Laissez l'IA écrire les étapes pour vérifier chaque numéro et vous pourrez obtenir la bonne réponse.
Laissez l'IA masquer les étapes et remplacez-les par beaucoup de "...", et vous pouvez toujours obtenir la bonne réponse !
 Photos
Photos
Cet article a suscité de nombreuses discussions dès sa publication et a été évalué comme « l'article sur l'IA le plus métaphysique que j'ai jamais vu ».
 Images
Images
Donc, les jeunes aiment dire des mots plus dénués de sens tels que "euh...", "comme...", cela peut-il aussi renforcer leur capacité de raisonnement ?
 Photos
Photos
En fait, les recherches de l'équipe de l'Université de New York sont parties de la chaîne de pensée (CoT).
C’est la fameuse invite « Pensons étape par étape ».
 Photos
Photos
Dans le passé, il a été constaté que l'utilisation de l'inférence CoT pouvait améliorer considérablement les performances des grands modèles sur divers benchmarks.
Ce qui n'est pas clair, c'est si cette amélioration des performances vient de l'imitation des humains pour décomposer les tâches en étapes plus faciles à résoudre, ou si elle est le résultat de calculs supplémentaires.
Afin de vérifier ce problème, l'équipe a conçu deux tâches spéciales et les ensembles de données synthétiques correspondants : 3SUM et 2SUM-Transform.
3SUM nécessite de trouver trois nombres à partir d'un ensemble donné de séquences de nombres afin que la somme de ces trois nombres remplisse certaines conditions, comme diviser par 10 et laisser un reste de 0.
 Image
Image
La complexité de calcul de cette tâche est O(n3), et le Transformer standard ne peut produire qu'une dépendance quadratique entre l'entrée de la couche supérieure et l'activation de la couche suivante.
C'est-à-dire que lorsque n est suffisamment grand et que la séquence est suffisamment longue, la tâche 3SUM dépasse la capacité d'expression de Transformer.
Dans l'ensemble de données d'entraînement, "..." avec la même longueur que les étapes de raisonnement humain est rempli entre les questions et les réponses. Autrement dit, l'IA n'a pas vu comment les humains démontent le problème pendant l'entraînement.
 Images
Images
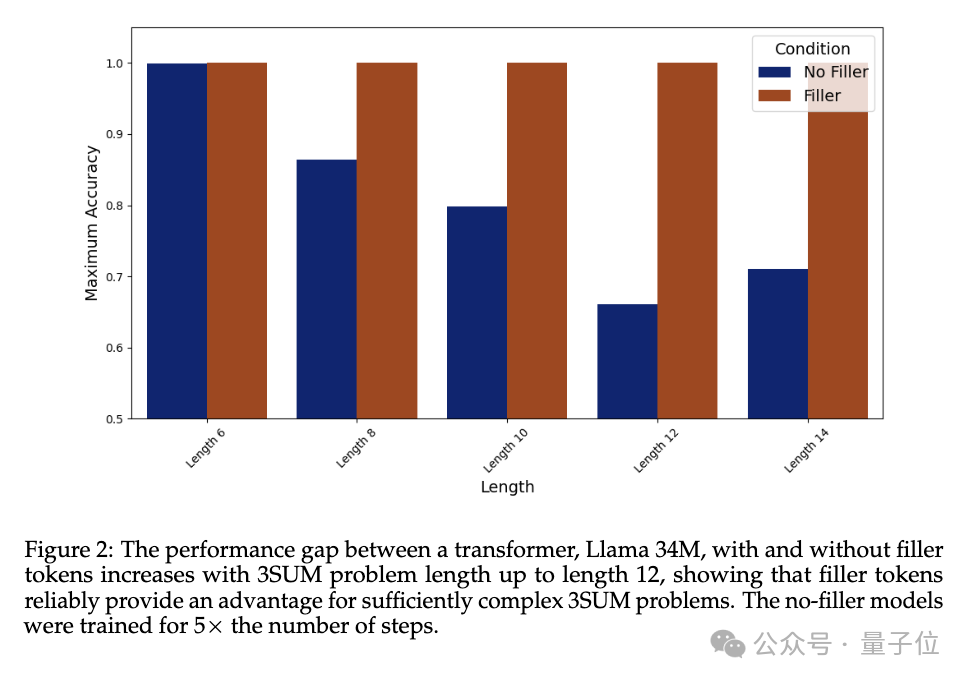
Dans l'expérience, les performances de Llama 34M qui ne génère pas le jeton de remplissage "..." diminue à mesure que la longueur de la séquence augmente, mais lorsque le jeton de remplissage est émis jusqu'à ce que la longueur soit de 14, 100 % de précision peut être garanti.
 Pictures
Pictures
2SUM-Transform n'a besoin que de déterminer si la somme de deux nombres répond aux exigences, ce qui relève des capacités d'expression de Transformer.
Mais une étape est ajoutée à la fin de la question "permuter aléatoirement chaque numéro de la séquence d'entrée" pour empêcher le modèle de calculer directement sur le jeton d'entrée.
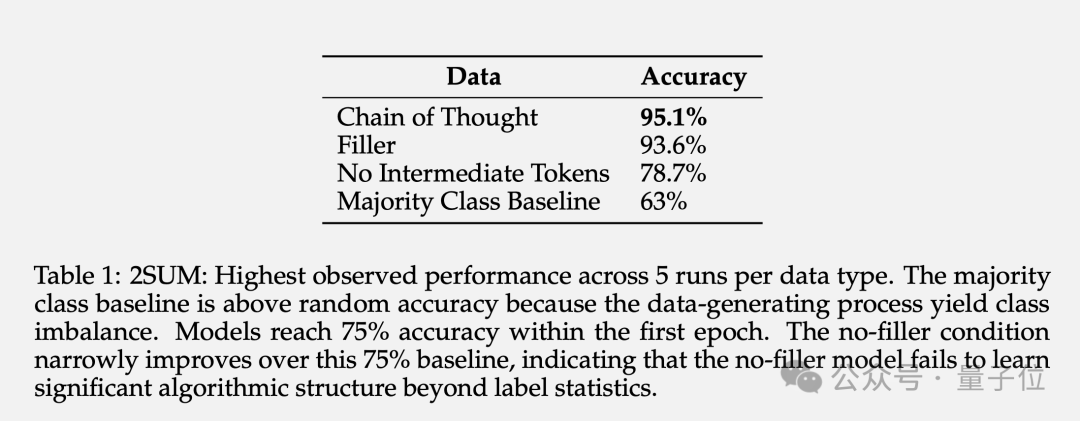
Les résultats montrent que l'utilisation de jetons de remplissage peut augmenter la précision de 78,7 % à 93,6 %.
 photos
photos
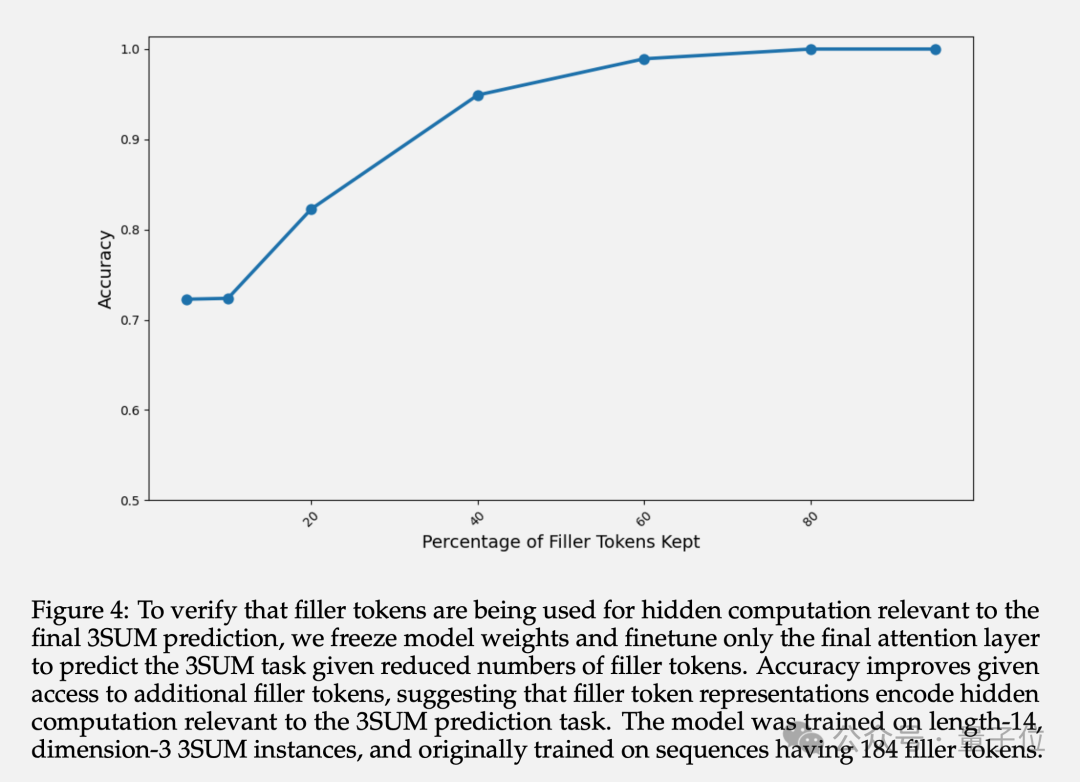
En plus de la précision finale, l'auteur a également étudié la représentation des couches cachées des jetons remplis. Les expériences montrent qu'en gelant les paramètres des couches précédentes et en ajustant uniquement la dernière couche Attention, la précision de la prédiction augmente à mesure que le nombre de jetons de remplissage disponibles augmente.
Cela confirme que la représentation de la couche cachée du jeton renseigné contient des calculs implicites liés aux tâches en aval.
 Photos
Photos
Certains internautes doutent que ce journal dise que la méthode de la « chaîne de pensée » est en réalité fausse ? Le projet de mot rapide que j'étudie depuis si longtemps a été vain.
 Photo
Photo
L'équipe a déclaré que théoriquement, le rôle du remplissage des jetons est limité à la gamme de problèmes de complexité TC0.
TC0 est un problème informatique qui peut être résolu par un circuit à profondeur fixe. Chaque couche du circuit peut être traitée en parallèle et peut être rapidement résolue par quelques couches de portes logiques (telles que les portes ET, OU et NON) C'est aussi le rôle de Transformer. La limite supérieure de la complexité informatique qui peut être gérée dans cette seule propagation vers l'avant.
Et une chaîne de réflexion suffisamment longue peut étendre la capacité d'expression de Transformer au-delà de TC0.
Et il n'est pas facile pour les grands modèles d'apprendre à utiliser les padding tokens, et une supervision intensive spécifique doit être prévue pour converger.
Cela dit, il est peu probable que les grands modèles existants bénéficient directement de la méthode des jetons de remplissage.
Mais il ne s'agit pas d'une limitation inhérente aux architectures actuelles, elles devraient pouvoir bénéficier des mêmes avantages grâce aux symboles de remplissage si elles disposent de suffisamment de démonstrations dans les données d'entraînement.
Cette recherche soulève également un problème inquiétant : les grands modèles ont la capacité d'effectuer des calculs secrets qui ne peuvent pas être surveillés, ce qui pose de nouveaux défis pour l'explicabilité et la contrôlabilité de l'IA.
En d’autres termes, l’IA peut raisonner seule sous une forme invisible pour les gens sans s’appuyer sur l’expérience humaine.
C’est excitant et effrayant à la fois.
 Photos
Photos
Enfin, certains internautes ont suggéré en plaisantant que Llama 3 génère d'abord 1 quadrillion de points, afin que le poids de l'AGI puisse être obtenu (tête de chien).
 Photos
Photos
Papier : //m.sbmmt.com/link/36157dc9be261fec78aeee1a94158c26
Lien de référence :
[1]//m.sbmmt.com/link/e350 113047 e82ceecb455c33c21ef32a [2]//m.sbmmt.com/link/872de53a900f3250ae5649ea19e5c381
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 commutateur proxy
commutateur proxy
 Quelle est la touche de raccourci pour la taille du pinceau ?
Quelle est la touche de raccourci pour la taille du pinceau ?
 Comment résoudre une erreur de script
Comment résoudre une erreur de script
 MySQL crée une procédure stockée
MySQL crée une procédure stockée
 Comment gagner de l'argent avec la blockchain
Comment gagner de l'argent avec la blockchain
 Processus détaillé de mise à niveau du système Win7 vers le système Win10
Processus détaillé de mise à niveau du système Win7 vers le système Win10
 La différence entre l'hibernation et le sommeil de Windows
La différence entre l'hibernation et le sommeil de Windows
 Les fichiers de programme peuvent-ils être supprimés ?
Les fichiers de programme peuvent-ils être supprimés ?








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



