


Après le départ du patron, le premier modèle est là !
Aujourd'hui encore, Stability AI a officiellement annoncé un nouveau modèle de code, Stable Code Instruct 3B.
 Photos
Photos
La stabilité est très importante. Le départ du PDG a causé quelques problèmes à Stable Diffusion. Il y a quelque chose qui ne va pas avec la société d'investissement, et il peut y avoir des problèmes avec votre propre salaire.
Cependant, le vent et la pluie font rage à l'extérieur du bâtiment, mais le laboratoire reste immobile. Des recherches doivent être menées, des discussions doivent être menées et des modèles doivent être ajustés. Le modèle de guerre à grande échelle dans divers domaines est arrivé. à rien.
Non seulement il s'étend pour s'engager dans une guerre totale, mais chaque recherche fait également des progrès continus. Par exemple, le Stable Code Instruct 3B d'aujourd'hui est basé sur le précédent Stable Code 3B avec un réglage des instructions.
 Photos
Photos
Adresse papier : https://static1.squarespace.com/static/6213c340453c3f502425776e/t/6601c5713150412edcd56f8e/1711392114564/Stable_ C ode_TechReport_release.pdf
Avec des invites en langage naturel, Stable Code Instruct 3B peut gérer diverses tâches telles que la génération de code, les mathématiques et d’autres requêtes liées au développement de logiciels.
 Photos
Photos
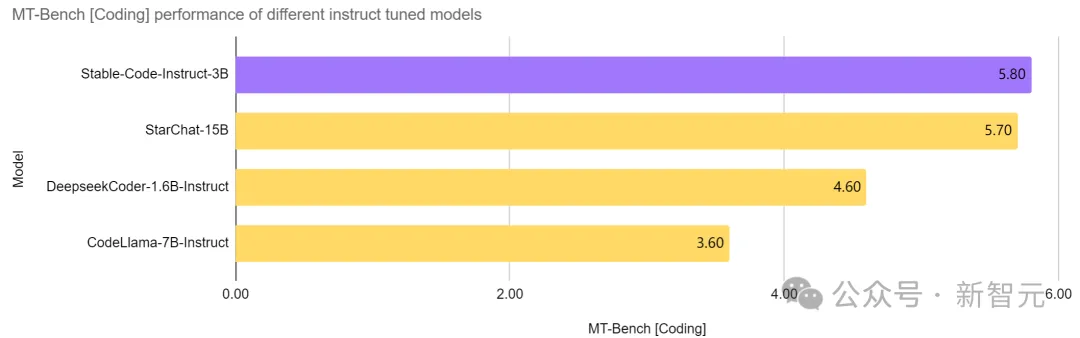
Stable Code Instruct 3B a atteint le SOTA actuel dans un modèle avec le même nombre de paramètres, encore mieux que CodeLlama, qui est plus de deux fois sa taille 7B Instruct et d'autres modèles, et ses performances dans les tâches liées au génie logiciel sont comparables à celles de StarChat 15B.
 Photos
Photos
Comme vous pouvez le voir sur l'image ci-dessus, Stable Code Instruct 3B fonctionne bien dans une gamme de tâches de codage par rapport aux principaux modèles tels que Codellama 7B Instruct et DeepSeek-Coder Instruct 1.3B.
Les tests montrent que Stable Code Instruct 3B est capable d'égaler ou de dépasser ses concurrents en termes de précision de complétion du code, de compréhension des instructions en langage naturel et de polyvalence dans différents langages de programmation.
 Pictures
Pictures
Stable Code Instruct 3B est basé sur les résultats de l'enquête auprès des développeurs Stack Overflow 2023 et concentre la formation sur les langages de programmationtels que Python, Javascript, Java, C, C++ et Aller.
Le graphique ci-dessus compare la force de la sortie générée par trois modèles dans divers langages de programmation à l'aide du benchmark Multi-PL. On peut constater que Stable Code Instruct 3B est nettement meilleur que CodeLlama dans toutes les langues et que le nombre de paramètres est supérieur à la moitié.
En plus des langages de programmation populaires mentionnés ci-dessus, Stable Code Instruct 3B comprend également une formation pour d'autres langages (tels que SQL, PHP et Rust), et peut fournir une formation puissante même dans des langages sans formation (comme Lua) pour tester les performances.
Stable Code Instruct 3B maîtrise non seulement la génération de code, mais également les tâches FIM (remplir au milieu), les requêtes de base de données, la traduction, l'interprétation et la création de code.
Grâce au réglage des instructions, les modèles sont capables de comprendre et d'agir sur des instructions subtiles, facilitant ainsi un large éventail de tâches de codage au-delà de la simple complétion de code, telles que la compréhension mathématique, le raisonnement logique et la gestion de techniques complexes de développement logiciel.
 Photos
Photos
Téléchargement du modèle : https://huggingface.co/stabilityai/stable-code-instruct-3b
Stable Code Instruct 3B est désormais disponible à des fins commerciales avec l'adhésion à Stability AI. Pour une utilisation non commerciale, les poids des modèles et le code peuvent être téléchargés sur Hugging Face.
 Photos
Photos
Stable Code est construit sur Stable LM 3B et est une structure de transformateur uniquement avec décodeur avec une conception similaire à LLaMA. Le tableau suivant présente quelques informations structurelles clés :
 Photos
Photos
Les principales différences avec LLaMA incluent :
Intégration positionnelle : utilisez l'intégration positionnelle en rotation dans les premiers 25 % de l'intégration de la tête pour améliorer les intégrations ultérieures. débit.
Régularisation : utilisez LayerNorm avec le terme de biais d'apprentissage au lieu de RMSNorm.
Termes de biais : tous les termes de biais du réseau feedforward et de la couche d'auto-attention multi-têtes sont supprimés, à l'exception de KQV.
Utilise le même tokenizer (BPE) que le modèle Stable LM 3B, avec une taille de 50 257. De plus, des balises spéciales de StarCoder sont également référencées, notamment le nombre d'étoiles utilisées pour indiquer le nom du fichier, le référentiel, et attente de remplissage intermédiaire (FIM).
Pour une formation contextuelle longue, utilisez des marqueurs spéciaux pour indiquer quand deux fichiers concaténés appartiennent au même référentiel.
Données de formation
L'ensemble de données de pré-formation collecte une variété de sources de données à grande échelle accessibles au public, notamment des référentiels de code, de la documentation technique (telle que readthedocs), des Concentrez-vous sur le texte et les grands ensembles de données Web.
L'objectif principal de la phase initiale de pré-formation est d'apprendre des représentations internes riches pour améliorer considérablement la capacité du modèle en compréhension mathématique, en raisonnement logique et en traitement de textes techniques complexes liés au développement de logiciels.
De plus, les données d'entraînement contiennent également un ensemble de données textuelles communes pour fournir au modèle des connaissances linguistiques et un contexte plus larges, permettant finalement au modèle de gérer un plus large éventail de requêtes et de tâches de manière conversationnelle.
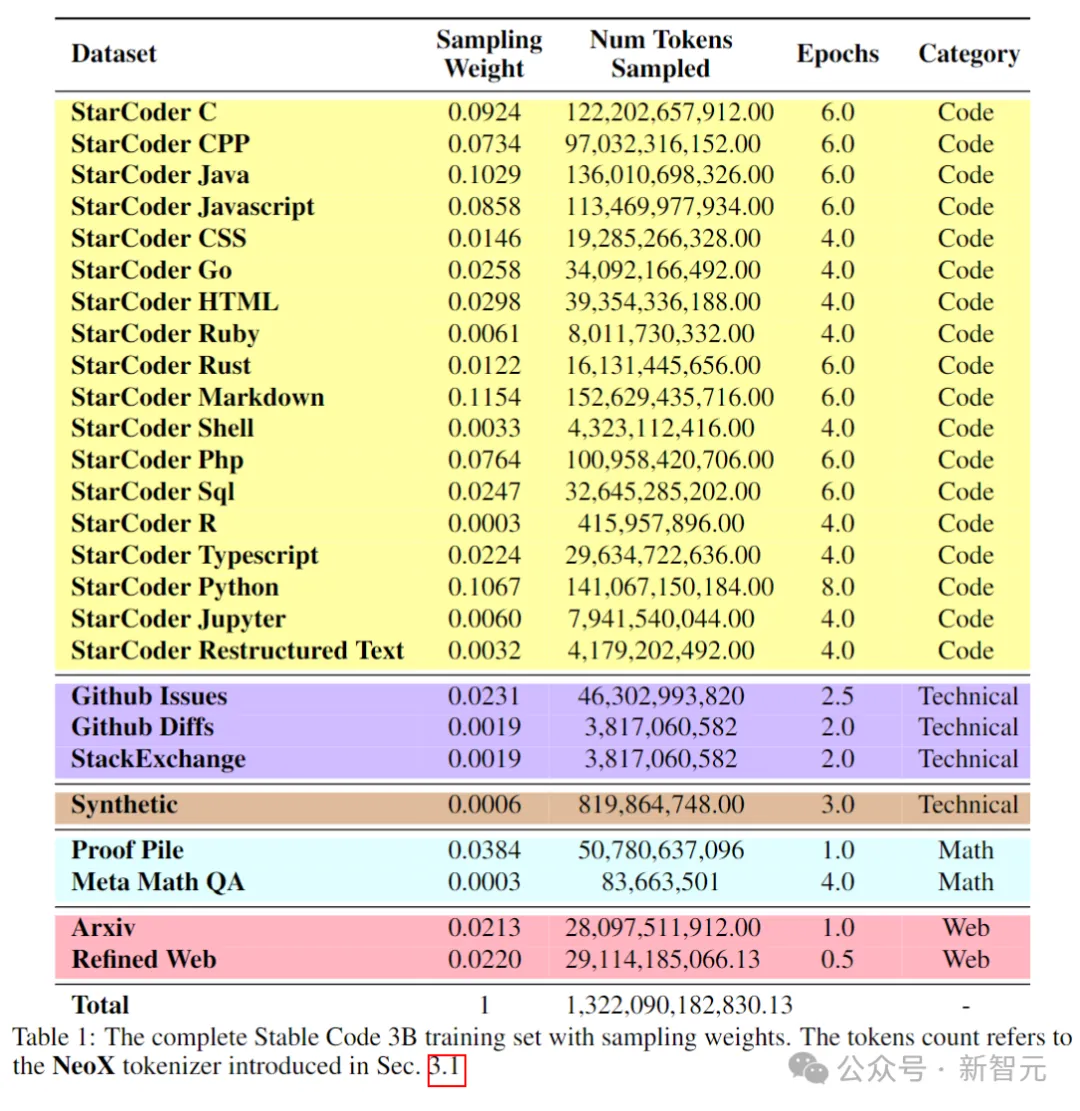
Le tableau suivant montre les sources de données, les catégories et les poids d'échantillonnage du corpus de pré-formation, où le ratio de données de code et de langage naturel est de 80:20.
 Photos
Photos
De plus, les chercheurs ont également introduit un petit ensemble de données synthétiques, les données ont été synthétisées à partir des pointes de graines de l'ensemble de données CodeAlpaca, contenant 174 000 pointes.
Et suivez la méthode WizardLM, en augmentant progressivement la complexité des invites de départ données, et obtenez 100 000 invites supplémentaires.
L'auteur estime que l'introduction de ces données synthétiques dès le début de la phase de pré-formation aide le modèle à mieux répondre au texte en langage naturel.
Ensemble de données de contexte long
Étant donné que plusieurs fichiers dans un référentiel dépendent souvent les uns des autres, la longueur du contexte est importante pour l'encodage des modèles.
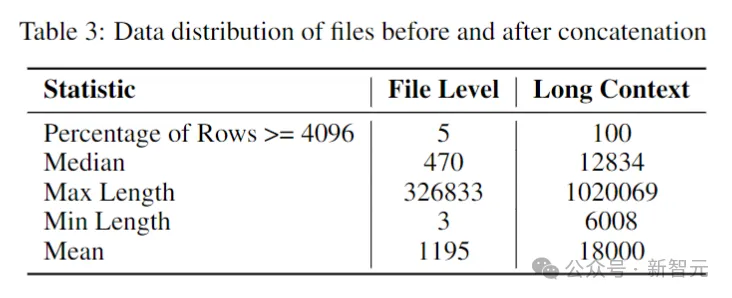
Les chercheurs ont estimé le nombre médian et moyen de jetons dans le référentiel de logiciels à 12 000 et 18 000 respectivement, c'est pourquoi 16 384 ont été choisis comme longueur de contexte.
L'étape suivante consistait à créer un long ensemble de données contextuelles. Les chercheurs ont pris certains fichiers écrits dans des langues populairesdans le référentiel et les ont combinés, en insérant une balise spéciale entre chaque fichier pour maintenir la séparation. flux de contenu.
Pour éviter tout biais potentiel pouvant résulter de l'ordre fixe des fichiers, les auteurs ont adopté une stratégie de randomisation. Pour chaque référentiel, deux séquences différentes de fichiers de connexion sont générées.
 Pictures
Pictures
Formation progressive
Stable Code est formé à l'aide de 32 instances Amazon P4d, contenant 256 GPU NVIDIA A100 (40 Go HBM2), et utilise ZeRO pour l'optimisation distribuée.
 Photos
Photos
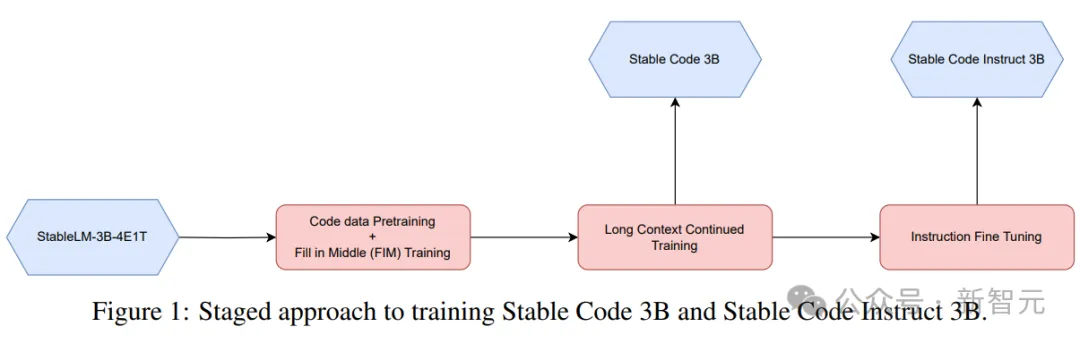
Une méthode d'entraînement par étapes est utilisée ici, comme le montre l'image ci-dessus.
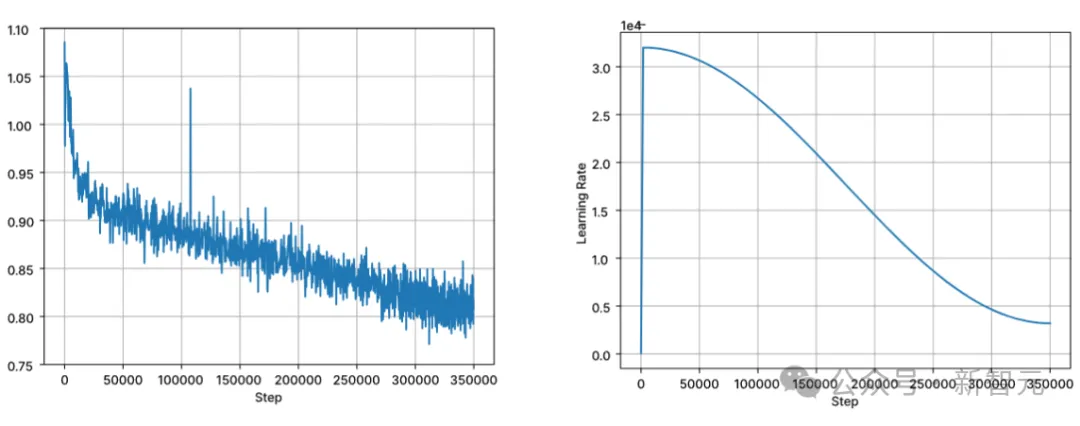
La formation suit la modélisation de séquence autorégressive standard pour prédire le prochain jeton. Le modèle est initialisé à l'aide du point de contrôle de Stable LM 3B. La durée du contexte de la première étape de formation est de 4096, puis une pré-formation continue est effectuée.
L'entraînement est effectué avec une précision mixte BFloat16 et FP32 est utilisé pour la réduction totale. Les paramètres de l'optimiseur AdamW sont : β1=0,9, β2=0,95, ε=1e−6, λ (dégradation du poids)=0,1. Commencez avec un taux d'apprentissage = 3,2e-4, définissez le taux d'apprentissage minimum sur 3,2e-5 et utilisez la désintégration du cosinus.
 Images
Images
L'une des hypothèses fondamentales de la formation des modèles de langage naturel est l'ordre causal de gauche à droite. Cependant, pour le code, cette hypothèse n'est pas toujours vraie (par exemple, les appels de fonction et la fonction. déclarations peuvent être dans n'importe quel ordre pour de nombreuses fonctions).
Pour résoudre ce problème, les chercheurs ont utilisé le FIM (Fill in the Middle). Divisez aléatoirement le document en trois segments : préfixe, milieu et suffixe, puis déplacez le segment du milieu vers la fin du document. Après réarrangement, le même processus de formation autorégressif est suivi.
Après la pré-formation, l'auteur améliore encore les compétences de dialogue du modèle à travers une étape de réglage fin, qui comprend un réglage fin supervisé (SFT) et une optimisation directe des préférences (DPO).
Effectuez d'abord le réglage fin de SFT à l'aide d'ensembles de données accessibles au public sur Hugging Face : notamment OpenHermes, Code Feedback, CodeAlpaca.
Après avoir effectué la déduplication des correspondances exactes, les trois ensembles de données fournissent un total d'environ 500 000 échantillons d'entraînement.
Utilisez le planificateur de taux d'apprentissage du cosinus pour contrôler le processus de formation et définissez la taille globale du lot sur 512 pour regrouper l'entrée en séquences d'une longueur ne dépassant pas 4096.
Après SFT, démarrez la phase DPO, en utilisant les données d'UltraFeedback pour organiser un ensemble de données contenant environ 7 000 échantillons. De plus, afin d'améliorer la sécurité du modèle, l'auteur a également inclus l'ensemble de données RLFH utile et inoffensif.
Les chercheurs ont adopté RMSProp comme algorithme d'optimisation et ont augmenté le taux d'apprentissage jusqu'à un pic de 5e-7 lors de la phase initiale de la formation DPO.
Ce qui suit compare les performances des modèles sur les tâches de complétion de code, en utilisant le benchmark Multi-PL pour évaluer les modèles.
Base de code stable
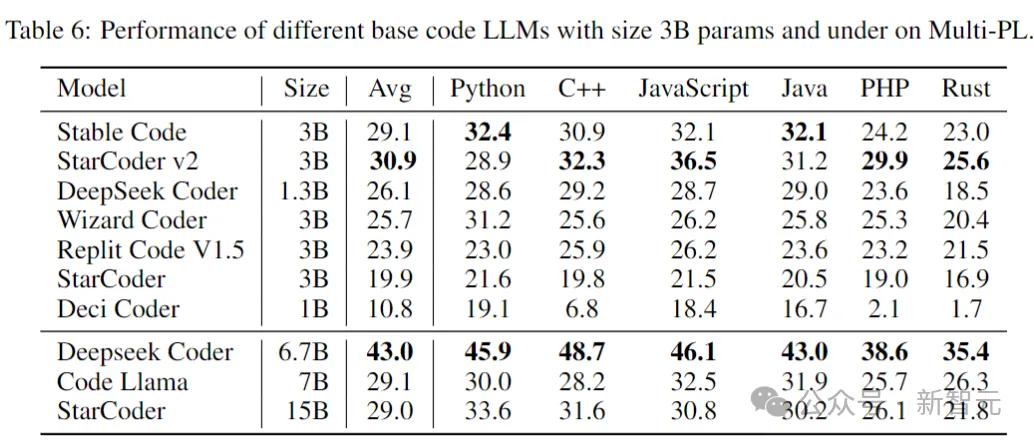
Le tableau suivant montre les performances de différents modèles de code avec des paramètres de taille 3B et inférieure sur Multi-PL.
 Photos
Photos
Bien que le nombre de paramètres de Stable Code soit respectivement inférieur à 40% et 20% de Code Llama et StarCoder 15B, les performances moyennes du modèle dans divers langages de programmation sont comparables à eux.
Stable Code Instruct
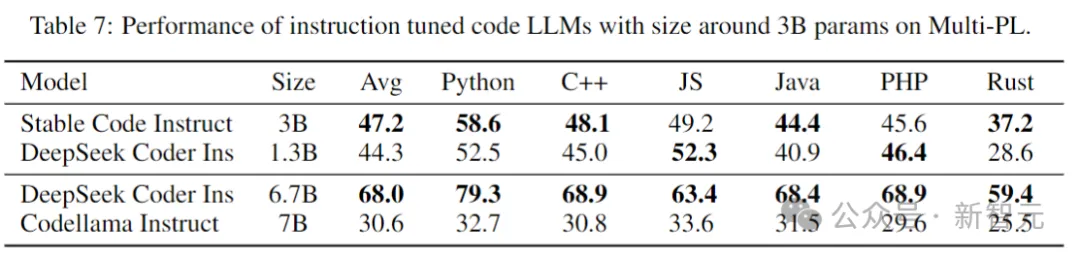
Le tableau suivant évalue les versions affinées de plusieurs modèles dans le benchmark Multi-PL.
 Images
Images
Performances SQL
Une application importante du modèle de langage de code est la tâche de requête de base de données. Dans ce domaine, les performances de Stable Code Instruct sont comparées à celles d’autres modèles populaires optimisés pour les instructions et à ceux formés spécifiquement pour SQL. Benchmarks créés ici à l’aide de Defog AI.
 Photos
Photos
Performances d'inférence
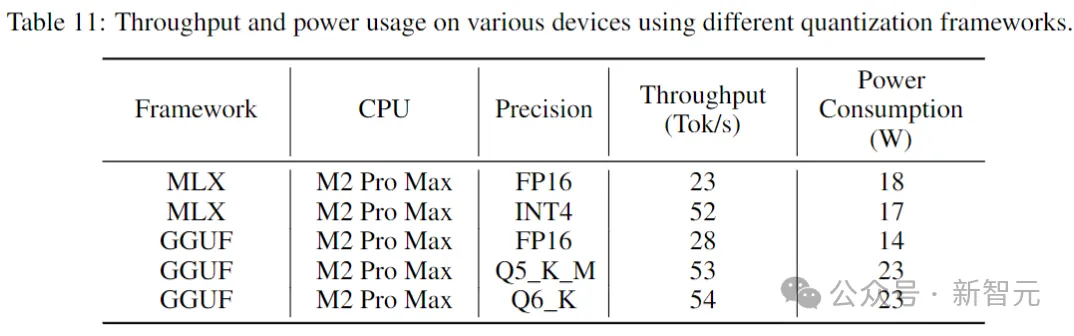
Le tableau suivant indique le débit et la consommation d'énergie lors de l'exécution de Stable Code sur des appareils grand public et les environnements système correspondants.
 Photos
Photos
Les résultats montrent que le débit augmente de près de deux fois en utilisant une précision inférieure. Cependant, il est important de noter que la mise en œuvre d’une quantification de moindre précision peut entraîner une certaine dégradation (potentiellement importante) des performances du modèle.
Référence ://m.sbmmt.com/link/8cb3522da182ff9ea5925bbd8975b203
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Formules de permutation et de combinaison couramment utilisées
Formules de permutation et de combinaison couramment utilisées Introduction à l'utilisation du code complet VBS
Introduction à l'utilisation du code complet VBS Raisons pour lesquelles les ordinateurs ont souvent des écrans bleus
Raisons pour lesquelles les ordinateurs ont souvent des écrans bleus Tutoriel sur l'ajustement de l'espacement des lignes dans les documents Word
Tutoriel sur l'ajustement de l'espacement des lignes dans les documents Word CPU
CPU Quelle langue est le langage C ?
Quelle langue est le langage C ? Où est le bouton d'impression ?
Où est le bouton d'impression ? Comment ouvrir jsp
Comment ouvrir jsp




















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



