


L'architecture Mamba, qui avait déjà fait exploser le cercle de l'IA, a lancé aujourd'hui une super variante !
La licorne d'intelligence artificielle AI21 Labs vient de rendre Jamba open source, le premier grand modèle Mamba de qualité production au monde !

Jamba a obtenu de bons résultats dans plusieurs tests de référence et est actuellement à égalité avec certains des transformateurs open source les plus puissants.
Surtout lorsque l'on compare Mixtral 8x7B, qui a les meilleures performances et est également une architecture MoE, il y a aussi des gagnants et des perdants.
Plus précisément -
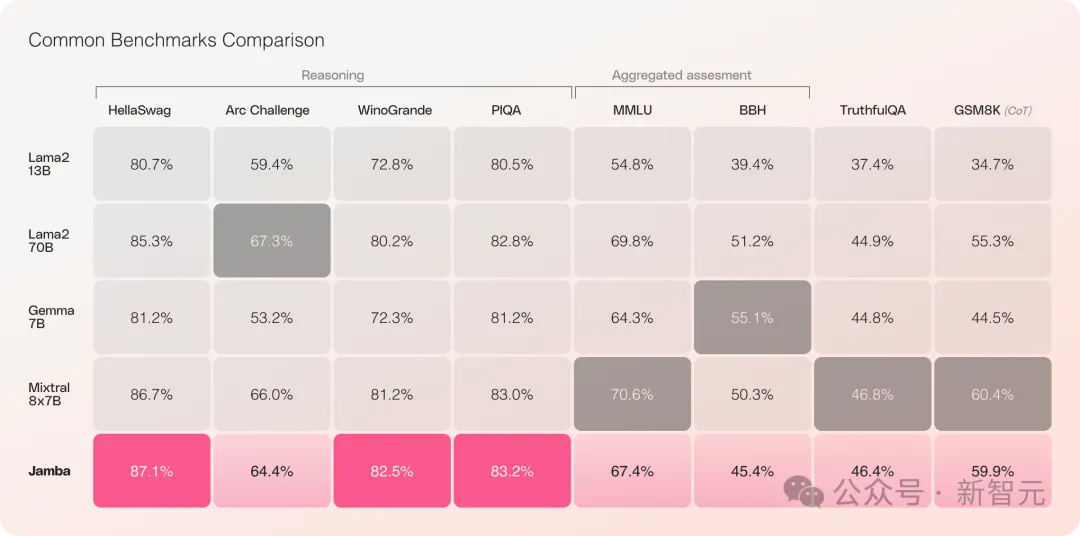
En raison de diverses restrictions, le précédent Mamba ne pouvait atteindre que 3B. Il a également été demandé s'il pouvait reprendre la bannière de Transformer RWKV, Griffin, etc., qui sont également des familles RNN linéaires. étendu à 14B.
——Jamba est passé directement au 52B cette fois, permettant à l'architecture Mamba de rivaliser de front avec le Transformer de niveau production pour la première fois.

Jamba est basé sur l'architecture Mamba originale et intègre les avantages de Transformer pour compenser les limitations inhérentes au modèle d'espace d'état (SSM).
On peut considérer qu'il s'agit en fait d'une nouvelle architecture - un hybride de Transformer et de Mamba, et le plus important est qu'elle puisse fonctionner sur un seul A100.
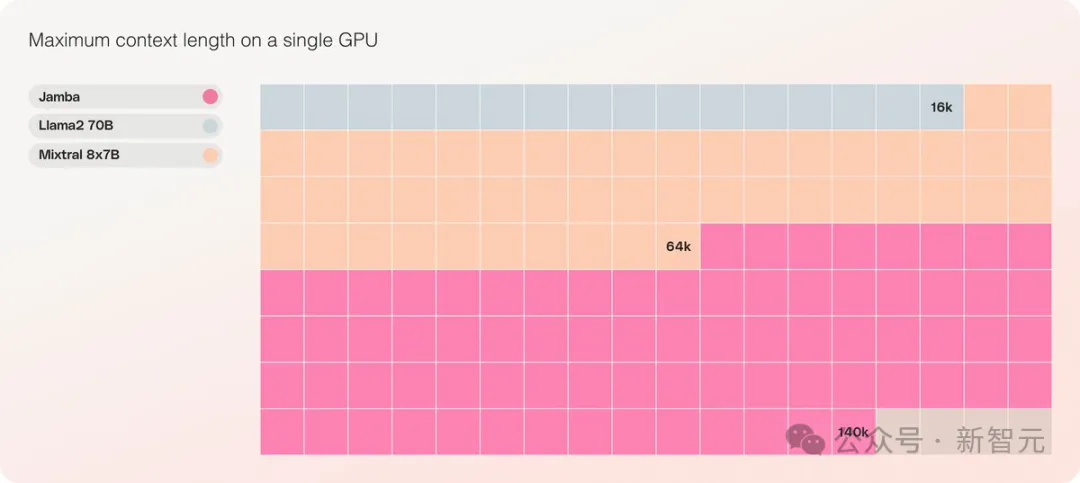
Il fournit une fenêtre de contexte ultra longue allant jusqu'à 256 Ko, un seul GPU peut exécuter un contexte de 140 Ko et le débit est 3 fois supérieur à celui de Transformer !
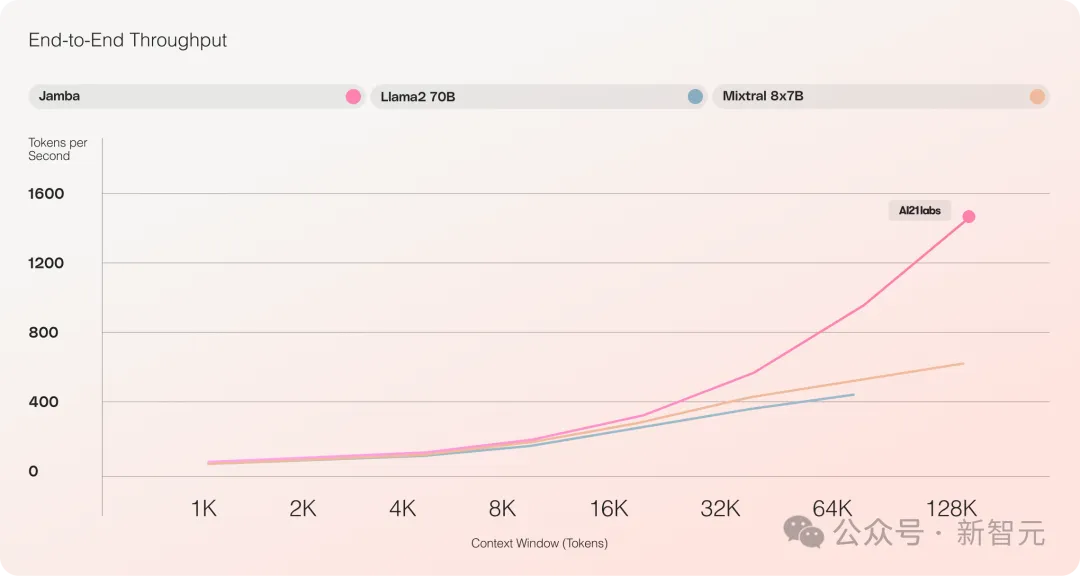
Par rapport à Transformer, il est très choquant de voir comment Jamba s'adapte à d'énormes longueurs de contexte
Jamba adopte la solution MoE, 12B sur 52B sont des paramètres actifs et le modèle est actuellement ouvert sous Apache 2.0 Les poids peuvent être téléchargés depuis huggingface.

Téléchargement du modèle : https://huggingface.co/ai21labs/Jamba-v0.1
La sortie de Jamba marque deux étapes importantes pour LLM :
Premièrement, il a combiné avec succès Mamba avec l'architecture Transformer, et deuxièmement, il a réussi à mettre à niveau la nouvelle forme de modèle (SSM-Transformer) à une échelle et une qualité de niveau production.
Les grands modèles actuels offrant les performances les plus élevées sont tous basés sur Transformer, même si tout le monde a également réalisé les deux principaux défauts de l'architecture Transformer :
Grande empreinte mémoire : l'empreinte mémoire de Transformer varie en fonction de la longueur du contexte. développer. L’exécution de longues fenêtres contextuelles ou le traitement par lots massivement parallèle nécessite beaucoup de ressources matérielles, ce qui limite l’expérimentation et le déploiement à grande échelle.
À mesure que le contexte grandit, la vitesse d'inférence ralentira : le mécanisme d'attention du transformateur fait augmenter le temps d'inférence carrément par rapport à la longueur de la séquence, et le débit deviendra de plus en plus lent. Étant donné que chaque jeton dépend de la séquence entière qui le précède, il devient assez difficile d'obtenir des contextes très longs.
Il y a quelques années, deux grands noms de Carnegie Mellon et Princeton ont proposé Mamba, qui a immédiatement enflammé les espoirs des gens.
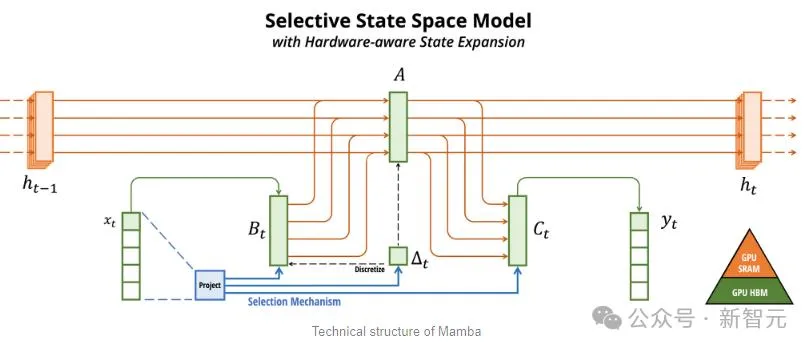
Mamba est basé sur SSM, ajoute la possibilité d'extraire sélectivement des informations et des algorithmes efficaces sur le matériel, résolvant les problèmes de Transformer d'un seul coup.
Ce nouveau domaine a immédiatement attiré un grand nombre de chercheurs, et un grand nombre d'applications et d'améliorations Mamba ont émergé sur arXiv, comme Vision Mamba, qui utilise Mamba pour la vision.
Je dois dire que le domaine de la recherche scientifique actuel est vraiment trop chargé. Il a fallu trois ans pour introduire Transformer into Vision (ViT), mais il n'a fallu qu'un mois de Mamba à Vision Mamba.
Cependant, la longueur du contexte du Mamba original est plus courte et le modèle lui-même n'est pas agrandi, il est donc difficile de battre le modèle SOTA Transformer, en particulier dans les tâches liées au rappel.
Jamba va ensuite plus loin et intègre les avantages de Transformer, Mamba et Mix of Experts (MoE) à travers l'architecture Joint Attention et Mamba, tout en optimisant la mémoire, le débit et les performances.

Jamba est la première architecture hybride à atteindre l'échelle de production (paramètres 52B).
Comme le montre la figure ci-dessous, l'architecture Jamba d'AI21 adopte une approche blocs et couches, permettant à Jamba d'intégrer avec succès les deux architectures.
Chaque bloc Jamba se compose d'une couche d'attention ou d'une couche Mamba, suivie d'un perceptron multicouche (MLP).
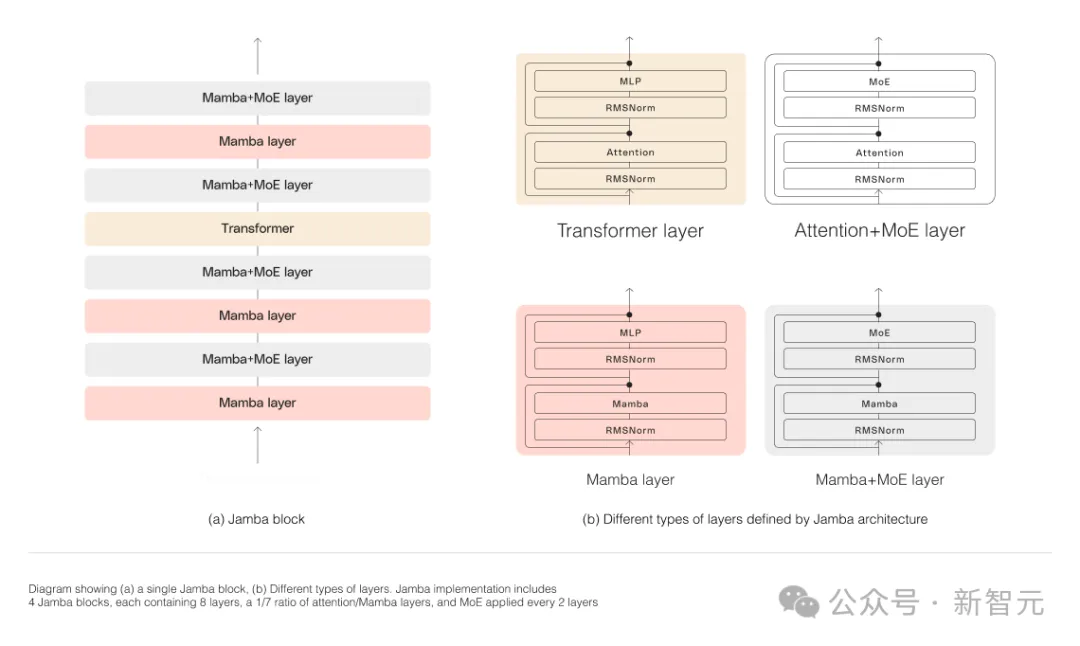
La deuxième fonctionnalité de Jamba est d'utiliser MoE pour augmenter le nombre total de paramètres du modèle tout en simplifiant le nombre de paramètres actifs utilisés dans l'inférence, augmentant ainsi la capacité du modèle sans augmenter les exigences de calcul.
Pour maximiser la qualité et le débit du modèle sur un seul GPU de 80 Go, les chercheurs ont optimisé le nombre de couches MoE et d'experts utilisés, laissant suffisamment de mémoire pour les charges de travail d'inférence courantes.
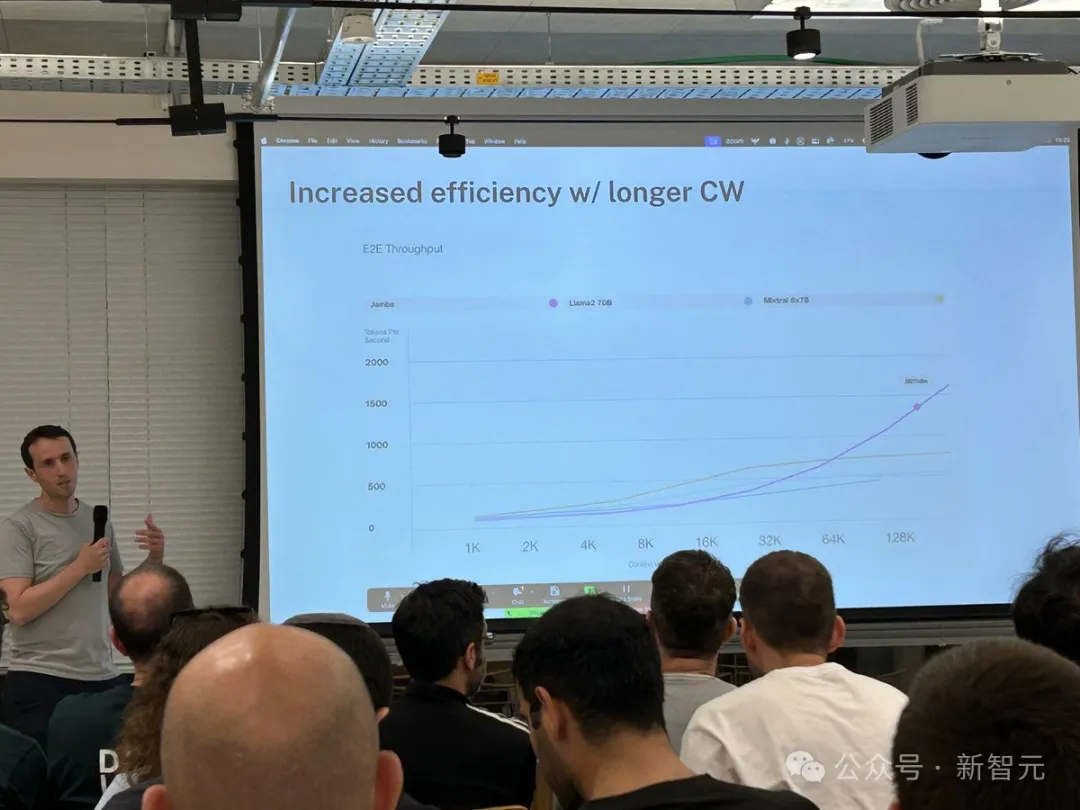
Par rapport aux modèles basés sur Transformer de taille similaire tels que Mixtral 8x7B, Jamba a atteint une accélération 3 fois supérieure sur des contextes longs.
Jamba sera bientôt ajouté au répertoire API NVIDIA.
Récemment, les grandes entreprises déploient le contexte long.
Les modèles avec des fenêtres contextuelles plus petites ont tendance à oublier le contenu des conversations récentes, tandis que les modèles avec un contexte plus large évitent cet écueil et peuvent mieux comprendre le flux de données qu'ils reçoivent.
Cependant, les modèles avec de longues fenêtres contextuelles ont tendance à nécessiter beaucoup de calculs.
Le modèle génératif de la startup AI21 Labs prouve que ce n'est pas le cas.

Jamba peut gérer jusqu'à 140 000 jetons lorsqu'il est exécuté sur un seul GPU (comme un A100) avec au moins 80 Go de mémoire vidéo.
Cela équivaut à environ 105 000 mots, soit 210 pages, soit la longueur d'un roman de longueur moyenne.
En comparaison, la fenêtre contextuelle de Meta Llama 2 ne contient que 32 000 jetons et nécessite 12 Go de mémoire GPU.
Selon les normes actuelles, cette fenêtre contextuelle est évidemment petite.
À cet égard, certains internautes ont immédiatement déclaré que les performances n'étaient pas importantes. La clé est que Jamba a un contexte de 256 Ko. À l'exception de Gemini, personne d'autre n'est aussi long - et Jamba est open source.
En apparence, Jamba peut sembler sans prétention.
Qu'il s'agisse de DBRX ou de Llama 2, qui était à l'honneur hier, il existe désormais un grand nombre de modèles d'IA générative gratuits et téléchargeables.
Le caractère unique de Jamba est caché sous le modèle : il combine deux architectures de modèles en même temps - le transformateur et le modèle d'espace d'état SSM.
D'une part, Transformer est l'architecture privilégiée pour les tâches de raisonnement complexes. Sa principale caractéristique est le « mécanisme d’attention ». Pour chaque élément de données d'entrée, le transformateur évalue la pertinence de toutes les autres entrées et en extrait pour générer la sortie.
D'autre part, SSM combine de nombreux avantages des modèles d'IA antérieurs, tels que les réseaux de neurones récurrents et les réseaux de neurones convolutifs, afin de pouvoir traiter de longues séquences de données avec une plus grande efficacité de calcul.
Bien que SSM ait ses propres limites. Mais certains premiers représentants, tels que Mamba proposé par Princeton et CMU, peuvent gérer des résultats plus importants que le modèle Transformer et sont meilleurs dans les tâches de génération de langage.
À cet égard, Dagan, chef de produit chez AI21 Labs, a déclaré :
Bien qu'il existe quelques exemples préliminaires de modèles SSM, Jamba est le premier modèle de qualité commerciale à l'échelle de production.
À son avis, en plus d'être innovant et intéressant pour la communauté à étudier plus en profondeur, Jamba offre également d'énormes possibilités d'efficacité et de débit.
Actuellement, Jamba est publié sous la licence Apache 2.0, qui a moins de restrictions d'utilisation mais ne peut pas être utilisée commercialement. Les versions ultérieures affinées devraient être lancées d’ici quelques semaines.
Même s'il en est encore aux premiers stades de la recherche, Dagan affirme que Jamba montre sans aucun doute la grande promesse de l'architecture SSM.
"La valeur ajoutée de ce modèle - à la fois due à sa taille et à son innovation architecturale - peut être facilement installée sur un seul GPU
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment utiliser DataReader
Comment utiliser DataReader Est-il légal d'acheter et de vendre du Bitcoin sur Huobi.com ?
Est-il légal d'acheter et de vendre du Bitcoin sur Huobi.com ? qu'est-ce que le CSS
qu'est-ce que le CSS Solution d'erreur 3004 inconnue
Solution d'erreur 3004 inconnue quelle est l'adresse mac
quelle est l'adresse mac Comment convertir chm en txt
Comment convertir chm en txt Quels sont les niveaux de notation par étoiles des utilisateurs mobiles ?
Quels sont les niveaux de notation par étoiles des utilisateurs mobiles ? Qu'est-ce que la programmation de socket
Qu'est-ce que la programmation de socket




















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



