


Seulement 2 photos , pas besoin de mesurer de données supplémentaires -
Dangdang, un ours 3D complet est là :
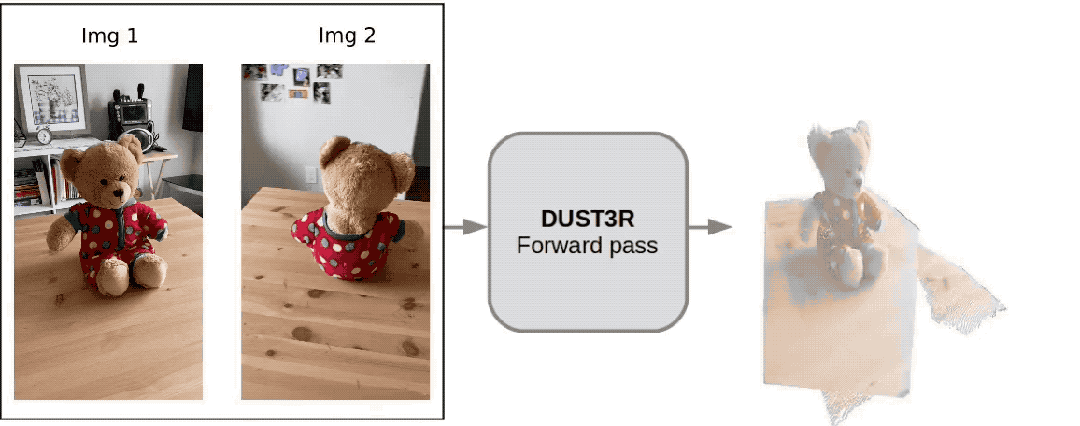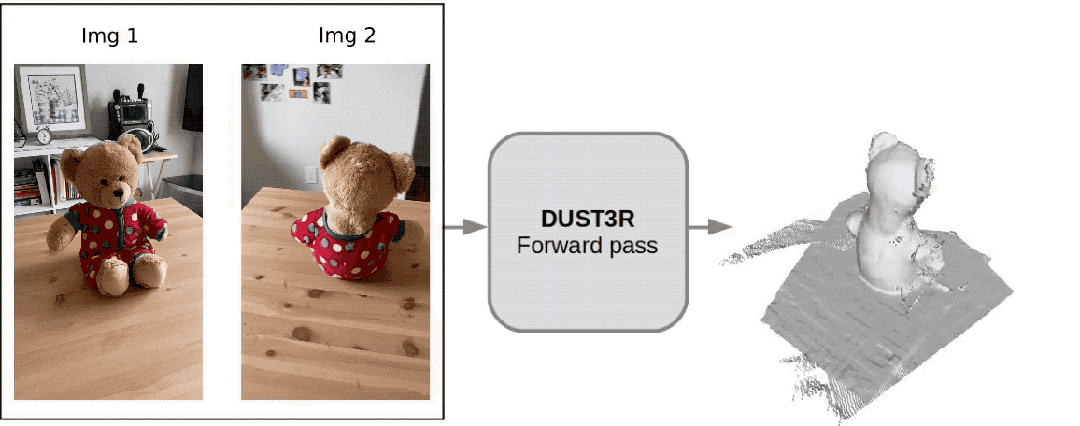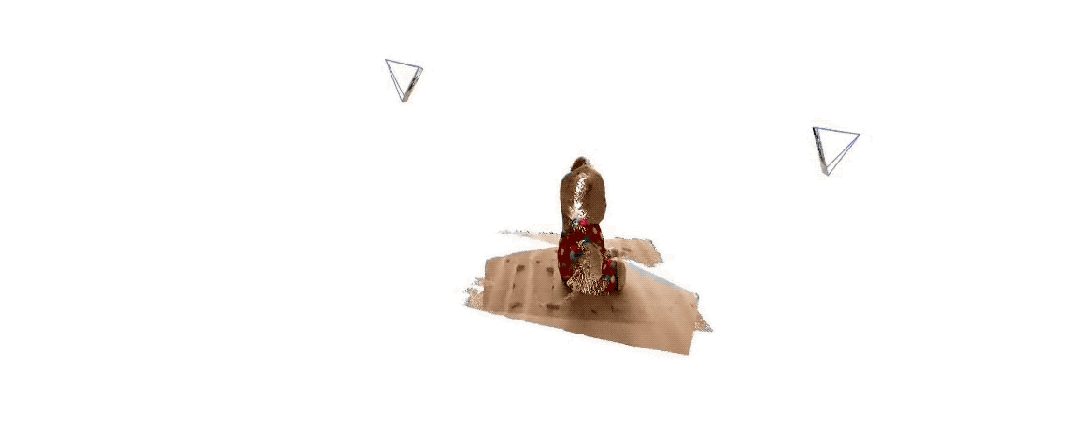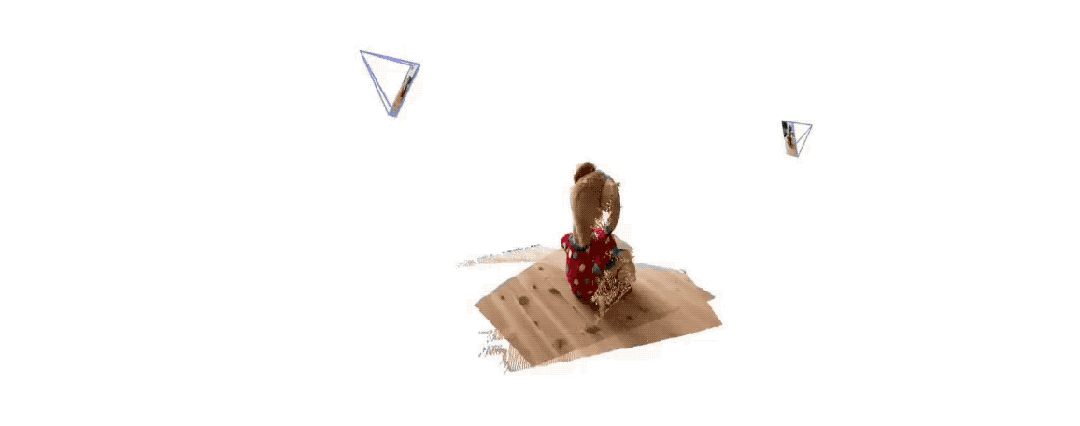
Ce nouvel outil appelé DUSt3R est très populaire, peu de temps après. a été lancé, il s'est classé deuxième sur la GitHub hot list.
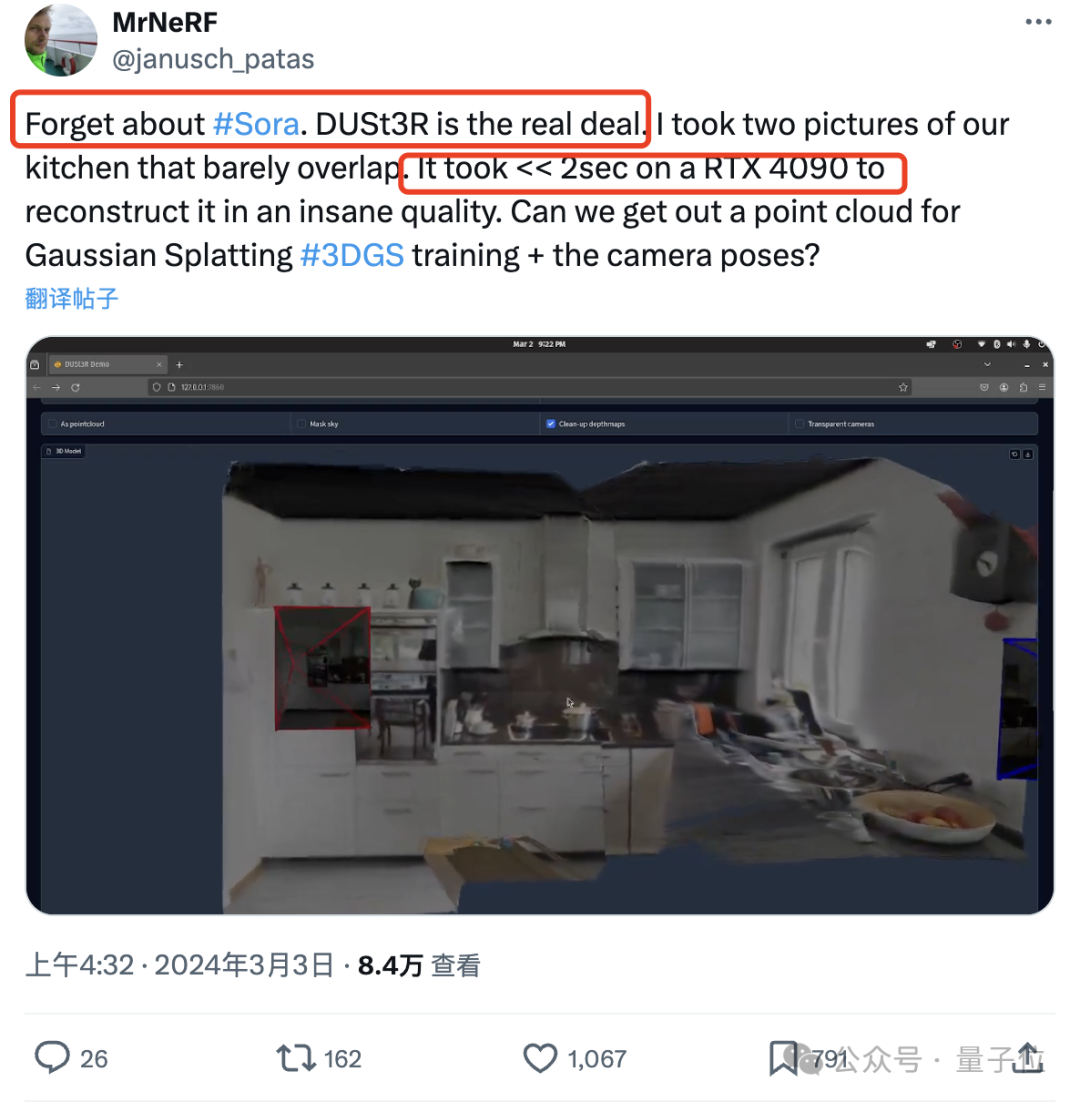
Un internaute a testé et a pris deux photos pour vraiment reconstituer sa cuisine. L'ensemble du processus a pris moins de 2 secondes !
(En plus des cartes 3D, il peut également fournir des cartes de profondeur, des cartes de confiance et des cartes de nuages de points)
Cet ami a été tellement choqué qu'il a dit :
Tout le mondeOubliez Sora d'abord Eh bien, c'est ce que nous pouvons vraiment voir et toucher.
Les expériences montrent que DUSt3R atteint SOTA dans les trois tâches d'estimation de la profondeur monoculaire/multi-vues et d'estimation de la pose relative.
L'équipe des auteurs (de l'Université Aalto, Finlande + branche européenne de l'Institut de recherche sur l'intelligence artificielle de NAVER LABS)Le « manifeste » de
est également plein d'élan :Nous voulons rendre le monde plus difficile à résoudre en vision 3D Tâches.Alors, comment ça se passe ? « tout-en-un »
Pour la tâche de reconstruction stéréo multi-vues (MVS)
, la première étape consiste à estimer les paramètres de la caméra, y compris les paramètres internes et externes. Cette opération est ennuyeuse et fastidieuse, mais elle est indispensable pour la triangulation ultérieure des pixels dans l'espace tridimensionnel, et c'est une partie indissociable de presque tous les algorithmes MVS avec de meilleures performances. Dans l’étude de cet article, DUSt3R présenté par l’équipe de l’auteur a adopté une approche complètement différente.Ilne nécessite aucune information préalable sur l'étalonnage de la caméra ou la pose du point de vue
, et peut effectuer une reconstruction 3D dense ou sans contrainte d'images arbitraires. Ici, l'équipe formule le problème de reconstruction par paires sous forme de régression par points, unifiant les situations de reconstruction monoculaire et binoculaire. Lorsque plus de deux images d'entrée sont fournies, toutes les paires d'images de points sont représentées dans un cadre de référence commun grâce à une stratégie d'alignement globale simple et efficace. Comme le montre la figure ci-dessous, étant donné un ensemble de photos avec des poses de caméra et des caractéristiques intrinsèques inconnues, DUSt3R génère un ensemble correspondant de cartes de points, à partir desquelles nous pouvons directement récupérer diverses quantités géométriques qui sont généralement difficiles à estimer simultanément, telles que paramètres de la caméra, correspondance des pixels, carte de profondeur et effet de reconstruction 3D totalement cohérent.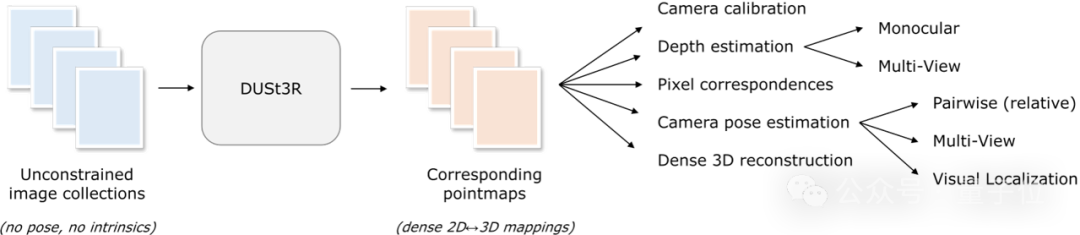
(L'auteur rappelle que DUSt3R convient également pour une image à entrée unique)
En termes d'architecture réseau spécifique, DUSt3R est basé sur le encodeur et décodeur standard Transformer, qui a été influencé par CroCo (via cross Une étude sur la pré-entraînement auto-supervisée aux tâches de vision 3D s'est inspirée de
et a été entraînée à l'aide d'une simple perte de régression.Comme indiqué ci-dessous, les deux vues (I1, I2) de la scène sont d'abord encodées à la manière siamoise à l'aide de l'encodeur ViT partagé.
La représentation symbolique résultante (F1 et F2) est ensuite transmise à deux décodeurs Transformer, qui échangent continuellement des informations par attention croisée.
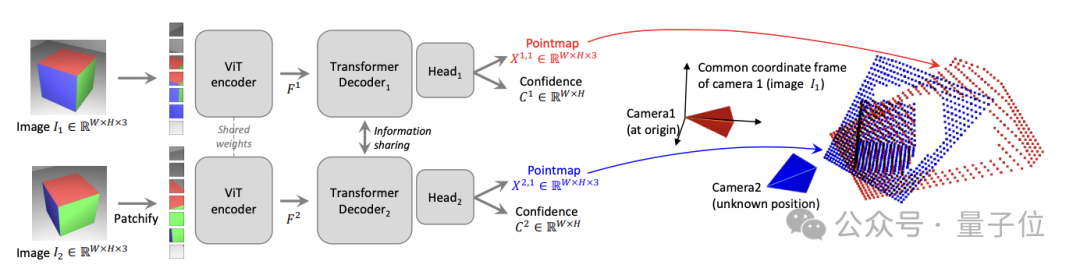
Enfin, les deux têtes de régression génèrent deux cartes de points correspondantes et des cartes de confiance associées.
Le point clé est que les deux tracés de points doivent être représentés dans le même système de coordonnées de la première image.
L'expérience a d'abord évalué les performances de DUSt3R sur la tâche d'estimation de pose absolue sur les ensembles de données 7Scenes (7 scènes d'intérieur) et Cambridge Landmarks (8 scènes d'extérieur) . Les indicateurs sont les erreurs de traduction et. rotation. Erreur (plus la valeur est petite, mieux c'est) .
L'auteur a déclaré que par rapport à d'autres méthodes existantes de correspondance de fonctionnalités et de bout en bout, les performances de DUSt3R sont remarquables.
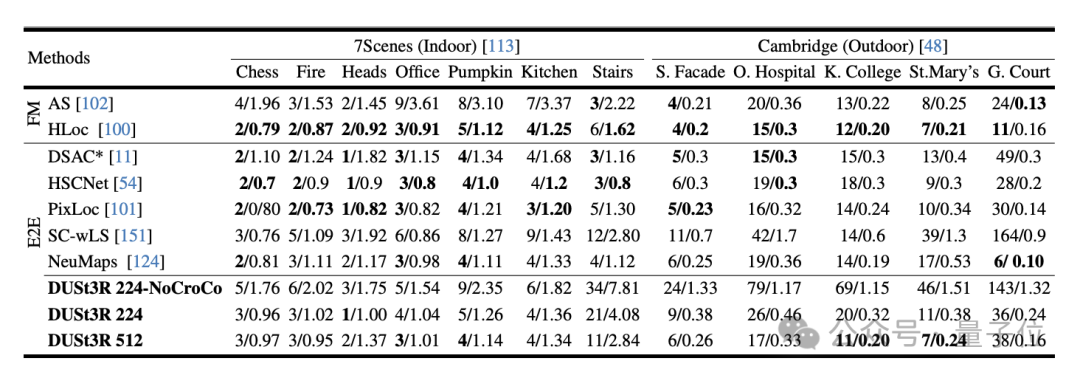
Parce que d'une part, il n'a jamais reçu de formation en positionnement visuel, et d'autre part, il n'a pas rencontré d'images de requête ni d'images de base de données pendant le processus de formation.
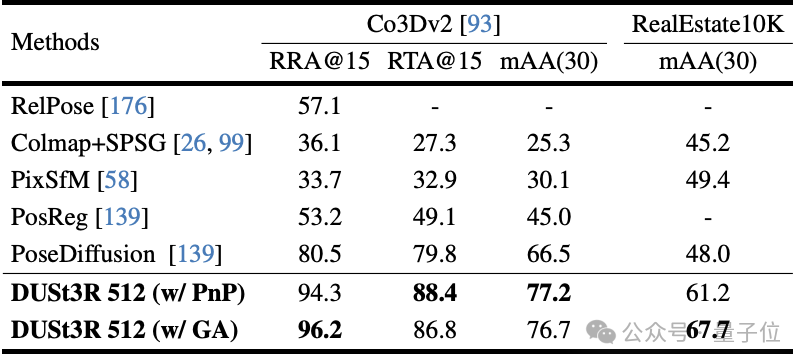
Deuxièmement, la tâche de régression de pose multi-vues est effectuée sur 10 images aléatoires. Résultats DUST3R a obtenu les meilleurs résultats sur les deux ensembles de données.
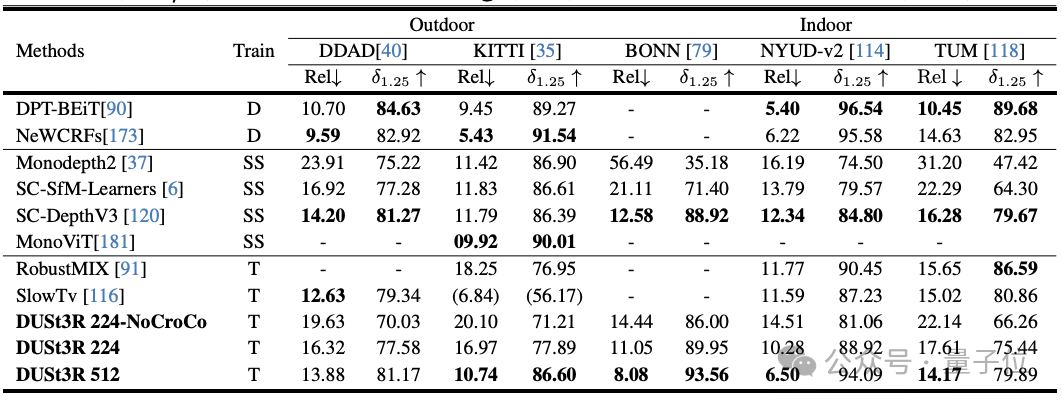
Sur la tâche d'estimation de profondeur monoculaire, DUSt3R peut également bien gérer les scènes intérieures et extérieures, avec des performances meilleures que les lignes de base auto-supervisées et à égalité avec les lignes de base supervisées les plus avancées.
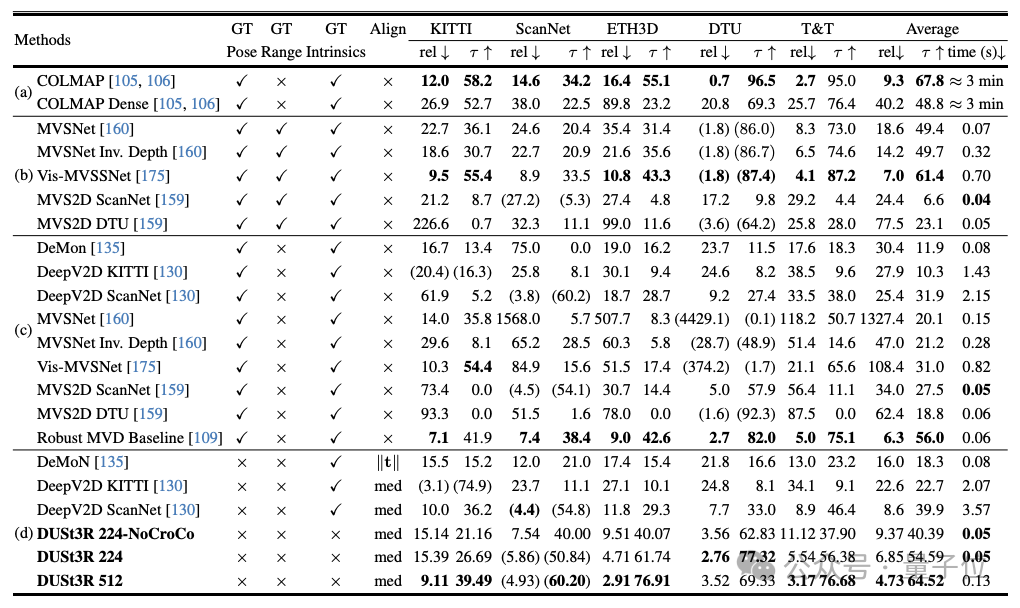
DUST3R fonctionne également bien dans l'estimation de la profondeur multi-vues.
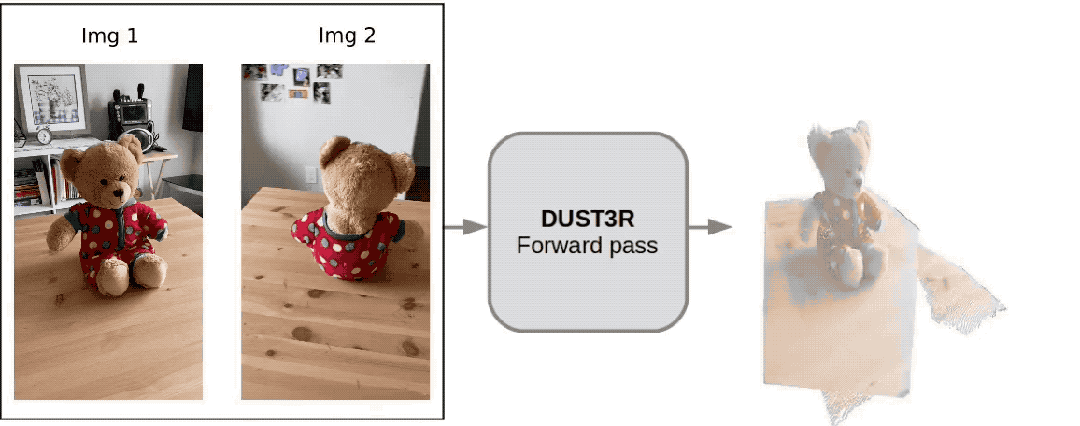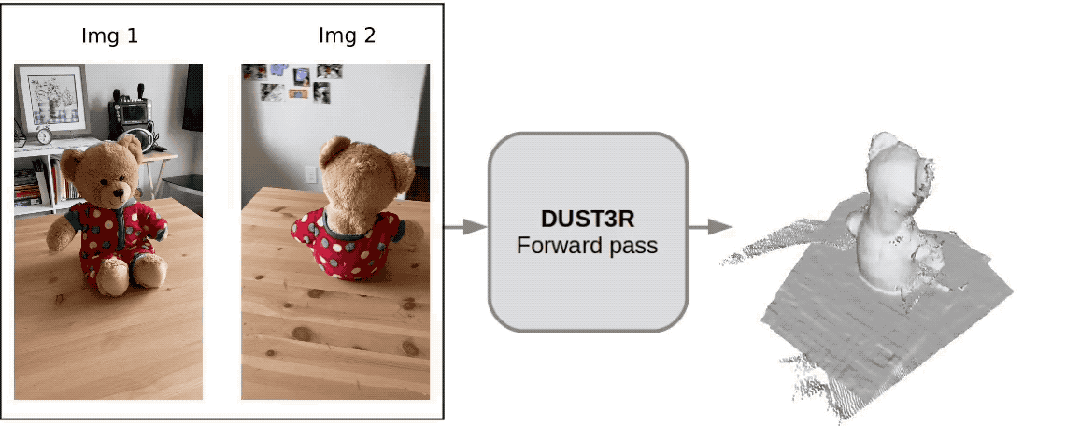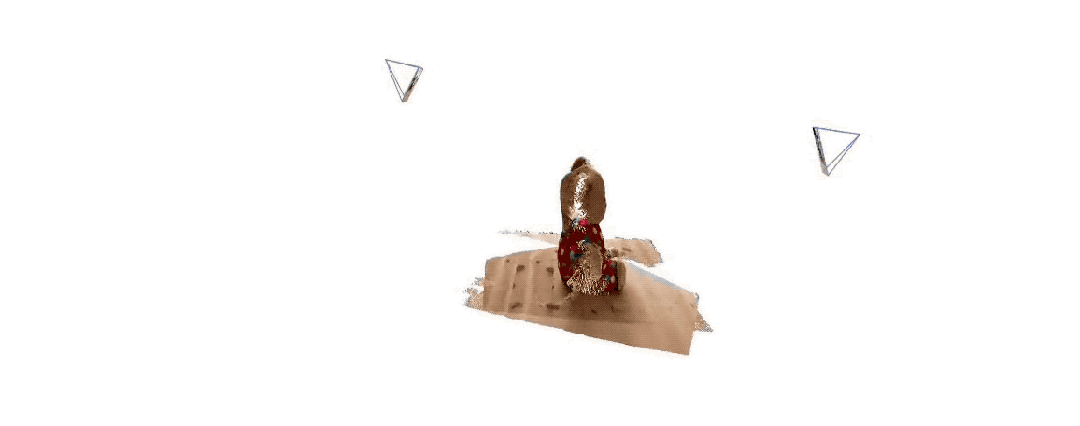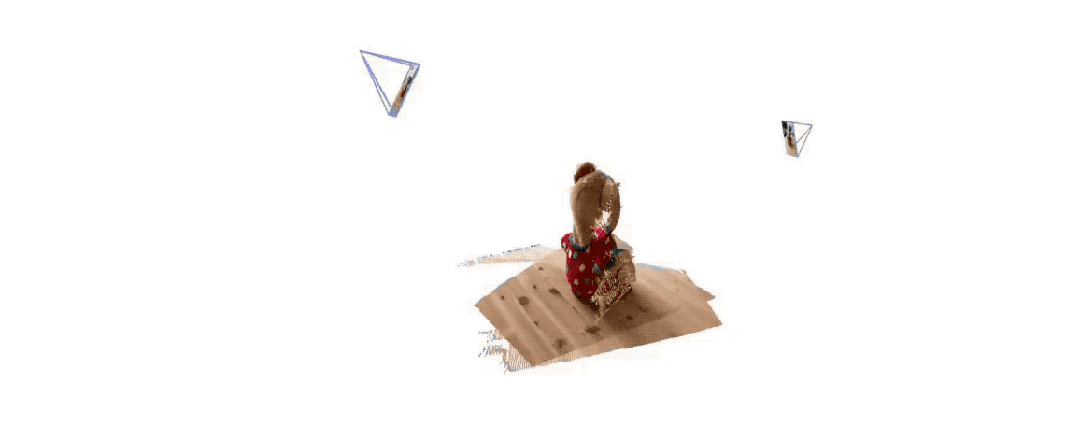
Voici les effets de reconstruction 3D donnés par les deux groupes Pour vous donner une idée, ils n'ont saisi que deux images :
(1)

(2)


 En réponse, certains internautes ont dit que cela signifie que cette méthode n'y fait pas de "mesures objectives", mais se comporte plutôt comme une IA.
En réponse, certains internautes ont dit que cela signifie que cette méthode n'y fait pas de "mesures objectives", mais se comporte plutôt comme une IA.
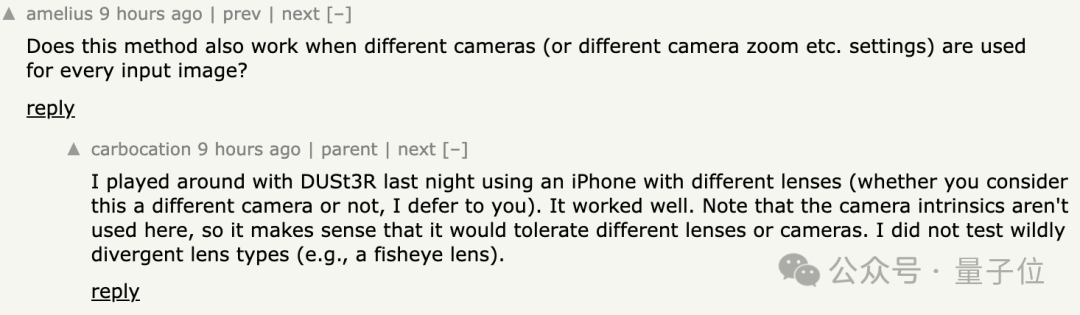
 De plus, certaines personnes sont curieuses
De plus, certaines personnes sont curieuses
? Certains internautes l'ont essayé, et la réponse est
oui!
[1] Article https://arxiv.org/abs/2312.14132
[2] Code https://github.com/naver/dust3r
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



