

 Tutoriel système
Linux
Explication détaillée du développement du minuteur du noyau Linux et du pilote de travail différé
Tutoriel système
Linux
Explication détaillée du développement du minuteur du noyau Linux et du pilote de travail différé
Explication détaillée du développement du minuteur du noyau Linux et du pilote de travail différé

Les minuteries du noyau Linux et les tâches de retard sont deux mécanismes couramment utilisés pour implémenter des tâches planifiées et des tâches d'exécution retardées. Ils permettent au pilote d'exécuter des fonctions spécifiques au moment approprié pour s'adapter aux besoins et aux caractéristiques du périphérique matériel. Mais comment utiliser correctement les timers du noyau Linux pour gérer les retards ? Cet article présentera les connaissances et les compétences de base du développement de pilotes de minuterie et de retard du noyau Linux sous les aspects théoriques et pratiques, ainsi que certains problèmes et solutions courants.

Minuterie du noyau
La minuterie du logiciel repose en fin de compte sur l'horloge matérielle. En termes simples, le noyau détectera si chaque minuterie enregistrée dans le noyau a expiré après l'expiration de l'horloge, il rappellera la fonction d'enregistrement correspondante et la sauvegardera. . Effectué comme moitié inférieure d’interruption. En fait, le gestionnaire d'interruption d'horloge déclenche l'interruption logicielle TIMER_SOFTIRQ et exécute toutes les minuteries qui ont expiré sur le processeur actuel.
Les pilotes de périphériques qui souhaitent obtenir des informations temporelles et nécessitent des services de synchronisation peuvent utiliser des minuteries du noyau.
jiffies
Pour parler du timer du noyau, il faut d'abord parler d'un concept important de temps dans le noyau : variable jiffies, comme base de l'horloge du noyau, les jiffies augmenteront de 1 à chaque temps fixe, ce qui s'appelle ajouter un battement . , cet intervalle fixe est implémenté par des interruptions de minuterie. Le nombre d'interruptions de minuterie générées par seconde est déterminé par la macro
//kernel/time/timekeeping.c 473 /** 474 * do_gettimeofday - Returns the time of day in a timeval 475 * @tv: pointer to the timeval to be set 476 * 477 * NOTE: Users should be converted to using getnstimeofday() 478 */ 479 void do_gettimeofday(struct timeval *tv)
Afin de laisser au matériel suffisamment de temps pour effectuer certaines tâches, le pilote doit souvent retarder l'exécution d'un code spécifique pendant un certain temps en fonction de la durée du délai, de deux types, délai long et délai court. , sont utilisés dans le concept de développement du noyau. La définition d'un long délai est : temps de retard > plusieurs jiffies Pour obtenir un long délai, vous pouvez utiliser la méthode d'interrogation des jiffies :
.time_before(jiffies, new_jiffies); time_after(new_jiffiesmjiffies);
**La définition du délai court est la suivante : l'événement de retard est proche ou inférieur à un jiffy. Pour obtenir un délai court, vous pouvez appeler
.udelay(); mdelay();
Les deux fonctions sont des fonctions d'attente occupées, qui consomment beaucoup de temps CPU. La première utilise des boucles logicielles pour retarder un nombre spécifié de microsecondes, et la seconde utilise l'imbrication de la première pour obtenir des retards de l'ordre de la milliseconde.
Minuterie
Le pilote peut enregistrer un minuteur de noyau pour spécifier une fonction à exécuter à un certain moment dans le futur. Le minuteur commence à compter lorsqu'il est enregistré dans le noyau, et la fonction enregistrée sera exécutée une fois le temps spécifié atteint. Autrement dit, la valeur du délai d'attente est une valeur en jiffies. Lorsque la valeur en jiffies est supérieure à timer->expires, la fonction timer-> sera exécutée. L'API est la suivante
//定一个定时器 struct timer_list my_timer; //初始化定时器 void init_timer(struct timer_list *timer); mytimer.function = my_function; mytimer.expires = jiffies +HZ; //增加定时器 void add_timer(struct timer_list *timer); //删除定时器 int del_tiemr(struct timer_list *timer);
Instances
static struct timer_list tm;
struct timeval oldtv;
void callback(unsigned long arg)
{
struct timeval tv;
char *strp = (char*)arg;
do_gettimeofday(&tv);
printk("%s: %ld, %ld\n", __func__,
tv.tv_sec - oldtv.tv_sec,
tv.tv_usec- oldtv.tv_usec);
oldtv = tv;
tm.expires = jiffies+1*HZ;
add_timer(&tm);
}
static int __init demo_init(void)
{
init_timer(&tm);
do_gettimeofday(&oldtv);
tm.function= callback;
tm.data = (unsigned long)"hello world";
tm.expires = jiffies+1*HZ;
add_timer(&tm);
return 0;
}
Travaux retardés
En plus d'utiliser le minuteur du noyau pour effectuer le travail de retard planifié, le noyau Linux fournit également un ensemble de "raccourcis" encapsulés - delayed_work, qui est similaire au minuteur du noyau. Son essence est également implémentée à l'aide de files d'attente de travail et de minuteurs,
//include/linux/workqueue.h
100 struct work_struct {
101 atomic_long_t data;
102 struct list_head entry;
103 work_func_t func;
104 #ifdef CONFIG_LOCKDEP
105 struct lockdep_map lockdep_map;
106 #endif
107 };
113 struct delayed_work {
114 struct work_struct work;
115 struct timer_list timer;
116
117 /* target workqueue and CPU ->timer uses to queue ->work */
118 struct workqueue_struct *wq;
119 int cpu;
120 };
«
struct work_struct
–103–>需要延迟执行的函数, typedef void (work_func_t)(struct work_struct work);”
至此,我们可以使用一个delayed_work对象以及相应的调度API实现对指定任务的延时执行
//注册一个延迟执行 591 static inline bool schedule_delayed_work(struct delayed_work *dwork,unsigned long delay) //注销一个延迟执行 2975 bool cancel_delayed_work(struct delayed_work *dwork)
和内核定时器一样,延迟执行只会在超时的时候执行一次,如果要实现循环延迟,只需要在注册的函数中再次注册一个延迟执行函数。
schedule_delayed_work(&work,msecs_to_jiffies(poll_interval));
本文从理论和实践两方面,详细介绍了Linux内核定时器与延迟工作驱动开发的基本知识和技巧。我们首先了解了Linux内核定时器与延迟工作的概念、原理、特点和API函数,然后学习了如何使用Linux内核定时器与延迟工作来实现按键事件的检测和处理。最后,我们介绍了一些在Linux内核定时器与延迟工作驱动开发过程中可能遇到的问题,以及相应的解决方法。
通过本文,我们希望能够帮助你掌握Linux内核定时器与延迟工作驱动开发的基本方法和技巧,为你在嵌入式Linux领域的进一步学习和工作打下坚实的基础。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undress AI Tool
Images de déshabillage gratuites

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1793
1793
 16
1737
56
1588
29
267
587
16
1737
56
1588
29
267
587

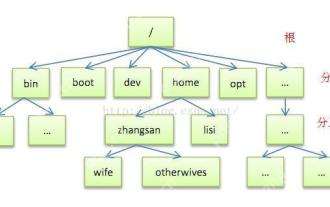 Introduction détaillée à chaque répertoire de Linux et de chaque répertoire (réimprimé)
May 22, 2025 pm 07:54 PM
Introduction détaillée à chaque répertoire de Linux et de chaque répertoire (réimprimé)
May 22, 2025 pm 07:54 PM
[DESCRIPTION DU RÉPERTOIRE COMMUN] DIRECTEUR / BIN STORES Fichiers exécutables (LS, CAT, MKDIR, etc.), et les commandes communes sont généralement là. / ETC stocke la gestion du système et les fichiers de configuration / Home Stores tous les fichiers utilisateur. Le répertoire racine du répertoire personnel de l'utilisateur est la base du répertoire domestique de l'utilisateur. Par exemple, le répertoire domestique de l'utilisateur d'utilisateur est / home / utilisateur. Vous pouvez utiliser ~ User pour représenter / USR pour stocker les applications système. Le répertoire plus important / USR / répertoire d'installation du logiciel d'administrateur système local local (installer les applications au niveau du système). Il s'agit du plus grand répertoire, et presque toutes les applications et fichiers à utiliser sont dans ce répertoire. / USR / X11R6 Répertoire pour stocker x fenêtre / usr / bin beaucoup
 Où est l'interpréteur PyCharm?
May 23, 2025 pm 10:09 PM
Où est l'interpréteur PyCharm?
May 23, 2025 pm 10:09 PM
La définition de l'emplacement de l'interprète dans PyCharm peut être réalisée via les étapes suivantes: 1. Ouvrez PyCharm, cliquez sur le menu "Fichier" et sélectionnez "Paramètres" ou "Préférences". 2. Recherchez et cliquez sur "Projet: [Nom de votre projet]" et sélectionnez "PythonInterpreter". 3. Cliquez sur "addterpreter", sélectionnez "SystemInterpreter", accédez au répertoire d'installation Python, sélectionnez le fichier exécutable Python, puis cliquez sur "OK". Lors de la configuration de l'interprète, vous devez prêter attention à l'exactitude du chemin, à la compatibilité des versions et à l'utilisation de l'environnement virtuel pour assurer le fonctionnement fluide du projet.
 La différence entre la programmation en Java et d'autres langues Analyse des avantages des caractéristiques multiplateformes de Java
May 20, 2025 pm 08:21 PM
La différence entre la programmation en Java et d'autres langues Analyse des avantages des caractéristiques multiplateformes de Java
May 20, 2025 pm 08:21 PM
La principale différence entre Java et d'autres langages de programmation est sa caractéristique multiplateforme de "l'écriture à la fois, en cours d'exécution partout". 1. La syntaxe de Java est proche de C, mais il supprime les opérations de pointeur qui sont sujettes aux erreurs, ce qui le rend adapté aux grandes applications d'entreprise. 2. Comparé à Python, Java présente plus d'avantages dans les performances et le traitement des données à grande échelle. L'avantage multiplateforme de Java provient de la machine virtuelle Java (JVM), qui peut exécuter le même bytecode sur différentes plates-formes, simplifiant le développement et le déploiement, mais veillez à éviter d'utiliser des API spécifiques à la plate-forme pour maintenir la plateformité transversale.
 Tutoriel d'installation de MySQL vous apprenez étape par étape les étapes détaillées pour l'installation et la configuration de MySQL étape par étape
May 23, 2025 am 06:09 AM
Tutoriel d'installation de MySQL vous apprenez étape par étape les étapes détaillées pour l'installation et la configuration de MySQL étape par étape
May 23, 2025 am 06:09 AM
L'installation et la configuration de MySQL peuvent être terminées via les étapes suivantes: 1. Téléchargez le package d'installation adapté au système d'exploitation à partir du site officiel. 2. Exécutez l'installateur, sélectionnez l'option "Default Default" et définissez le mot de passe de l'utilisateur racine. 3. Après l'installation, configurez les variables d'environnement pour vous assurer que le répertoire bac de MySQL est dans le chemin du chemin. 4. Lors de la création d'un utilisateur, suivez le principe des autorisations minimales et définissez un mot de passe fort. 5. Ajustez les paramètres Innodb_Buffer_Pool_Size et Max_Connections lors de l'optimisation des performances. 6. Sauvegarder régulièrement la base de données et optimiser les instructions de requête pour améliorer les performances.
 Expérience dans la participation aux activités d'échange de technologie hors ligne VSCODE
May 29, 2025 pm 10:00 PM
Expérience dans la participation aux activités d'échange de technologie hors ligne VSCODE
May 29, 2025 pm 10:00 PM
J'ai beaucoup d'expérience dans la participation aux activités d'échange de technologie hors ligne VSCODE, et mes principaux gains comprennent le partage du développement plug-in, des démonstrations pratiques et une communication avec d'autres développeurs. 1. Partage du développement plug-in: J'ai appris à utiliser l'API plug-in de VScode pour améliorer l'efficacité de développement, telles que la mise en forme automatique et les plug-ins d'analyse statique. 2. Démonstration pratique: j'ai appris à utiliser VScode pour le développement à distance et j'ai réalisé sa flexibilité et son évolutivité. 3. Communiquez avec les développeurs: j'ai obtenu des compétences pour optimiser la vitesse de démarrage VSCODE, telles que la réduction du nombre de plug-ins chargés au démarrage et la gestion de l'ordre de chargement du plug-in. En bref, cet événement m'a beaucoup profité et je recommande vivement ceux qui sont intéressés par VSCODE de participer.
 Comment limiter les ressources des utilisateurs dans Linux? Comment configurer Ulimit?
May 29, 2025 pm 11:09 PM
Comment limiter les ressources des utilisateurs dans Linux? Comment configurer Ulimit?
May 29, 2025 pm 11:09 PM
Linux System restreint les ressources utilisateur via la commande UliMIT pour éviter une utilisation excessive des ressources. 1.Ulimit est une commande shell intégrée qui peut limiter le nombre de descripteurs de fichiers (-n), la taille de la mémoire (-v), le nombre de threads (-u), etc., qui sont divisés en limite douce (valeur effective actuelle) et limite dure (limite supérieure maximale). 2. Utilisez directement la commande ulimit pour une modification temporaire, telle que Ulimit-N2048, mais elle n'est valable que pour la session en cours. 3. Pour un effet permanent, vous devez modifier /etc/security/limits.conf et les fichiers de configuration PAM, et ajouter SessionRequiredPam_limits.so. 4. Le service SystemD doit définir Lim dans le fichier unitaire
 Comparaison entre Informrix et MySQL sur Linux
May 29, 2025 pm 11:21 PM
Comparaison entre Informrix et MySQL sur Linux
May 29, 2025 pm 11:21 PM
Informrix et MySQL sont tous deux des systèmes de gestion de base de données relationnels populaires. Ils fonctionnent bien dans les environnements Linux et sont largement utilisés. Ce qui suit est une comparaison et une analyse des deux sur la plate-forme Linux: Installation et configurer Informrix: le déploiement d'informations sur Linux nécessite le téléchargement des fichiers d'installation correspondants, puis la réalisation du processus d'installation et de configuration en fonction de la documentation officielle. MySQL: Le processus d'installation de MySQL est relativement simple et peut être facilement installé via des outils de gestion des packages système (tels que APT ou YUM), et il existe un grand nombre de didacticiels et une prise en charge de la communauté sur le réseau pour référence. Performance Informrix: Informrix a d'excellentes performances et
 Comment intégrer Filebeat et Elasticsearch sous Debian
May 28, 2025 pm 05:09 PM
Comment intégrer Filebeat et Elasticsearch sous Debian
May 28, 2025 pm 05:09 PM
Dans le système d'exploitation Debian, l'intégration de Filebeat et Elasticsearch peut simplifier la collecte, la transmission et le stockage des données de journal. Voici les étapes de mise en œuvre spécifiques: Étape 1: La première tâche de déploiement d'Elasticsearch est de terminer l'installation d'Elasticsearch dans le système Debian. Vous pouvez télécharger la version correspondante du progiciel Elasticsearch à partir du site officiel élastique et terminer le processus d'installation selon les directives officielles. Téléchargez et installez elasticsearchwgethttps: //artifacts.elastic.co/downloads/elasticse
