


La dernière génération de modèles linguistiques (tels que GPT-4, PaLM et LLaMa) ont réalisé d'importantes avancées dans le traitement et la génération du langage naturel. Ces modèles à grande échelle sont capables d'accomplir des tâches allant de l'écriture de sonnets shakespeariens à la synthèse de rapports médicaux complexes et même à la résolution de problèmes de programmation de niveau compétition. Bien que ces modèles soient capables de résoudre un large éventail de problèmes, ils ne sont pas toujours corrects. Parfois, ils peuvent générer des résultats de réponse inexacts, trompeurs ou contradictoires. Par conséquent, lors de l’utilisation de ces modèles, il convient de veiller à évaluer et à vérifier l’exactitude et la fiabilité de leurs résultats.
À mesure que les coûts de fonctionnement des modèles diminuent, les gens commencent à envisager d'utiliser des systèmes d'échafaudage et des requêtes de modèle multilingues pour améliorer la précision et la stabilité de la sortie du modèle. Cette approche optimise les performances du modèle et offre une meilleure expérience aux utilisateurs.
Cette recherche de Stanford et OpenAI propose une nouvelle technologie qui peut être utilisée pour améliorer la puissance et les performances des modèles de langage appelée méta-invite.

Cette technologie implique la construction d'une invite "méta" de haut niveau, dont la fonction est de demander au modèle de langage d'effectuer la suivants :
1. Décomposer des tâches ou des problèmes complexes en sous-tâches plus petites et faciles à résoudre ;
2. Utiliser des instructions en langage naturel appropriées et détaillées pour attribuer ces sous-tâches à des modèles "experts" spécialisés ; la communication entre ces modèles experts ;
4. Appliquer leurs propres compétences de pensée critique, de raisonnement et de vérification à travers ce processus.
Pour un modèle de langage qui peut être appelé efficacement à l'aide de méta-invites, le rôle du modèle est d'agir comme un chef d'orchestre lors de son interrogation. Il génère un historique de message (ou récit) composé de réponses de plusieurs modèles experts. Ce modèle de langage est d'abord chargé de générer pour le commandant une partie de l'historique des messages, qui comprend la sélection des experts et la construction d'instructions spécifiques pour eux. Cependant, le même modèle de langage agit également comme un expert indépendant à part entière, générant des résultats basés sur l'expertise et les informations sélectionnées par le commandant pour chaque requête spécifique.
Cette approche permet à un modèle linguistique unifié unique de maintenir une ligne de raisonnement cohérente tout en tirant parti d'une variété de rôles d'experts. En sélectionnant dynamiquement le contexte d'incitation, ces experts peuvent apporter une nouvelle perspective au processus, tandis que le modèle de commandant conserve une vue d'ensemble de l'historique complet et maintient la coordination.
Ainsi, cette approche permet à un seul modèle de langage de boîte noire d'agir efficacement à la fois en tant que commandant central et en tant que série d'experts différents, ce qui permet d'obtenir des réponses plus précises, fiables et cohérentes.
La technologie de méta-invite nouvellement proposée ici combine et étend de nombreuses idées d'incitation différentes proposées par des recherches récentes, notamment la planification et la prise de décision de haut niveau, l'affectation dynamique des personnes, le débat multi-agents, l'auto-débogage et l'auto-débogage. réflexion.
Un aspect clé de la méta-invite est sa propriété d'être indépendante des tâches.
Contrairement aux méthodes d'échafaudage traditionnelles qui nécessitent des instructions ou des exemples spécifiques adaptés à chaque tâche, les méta-invites utilisent le même ensemble d'instructions de haut niveau pour plusieurs tâches et entrées. Cette polyvalence est particulièrement bénéfique pour les utilisateurs timides, car elle élimine le besoin de fournir des exemples détaillés ou des instructions spécifiques pour chaque tâche spécifique.
Par exemple, pour une requête ponctuelle telle que « Écrivez un sonnet shakespearien sur la prise d'un selfie », les utilisateurs n'ont pas besoin de la compléter avec des exemples de poésie néoclassique de haute qualité.
Les méthodes de méta-invite peuvent améliorer l'utilité des modèles de langage en fournissant un cadre large et flexible sans compromettre leur spécificité ou leur pertinence. De plus, pour démontrer la polyvalence et les capacités d’intégration de la méthode de méta-invite, l’équipe a également amélioré son système afin qu’il puisse appeler l’interpréteur Python. Cela permettra à la technologie de prendre en charge des applications plus dynamiques et plus complètes, augmentant ainsi son potentiel pour gérer efficacement un large éventail de tâches et de requêtes.
La figure 2 montre un exemple de flux de conversation de méta-invite.
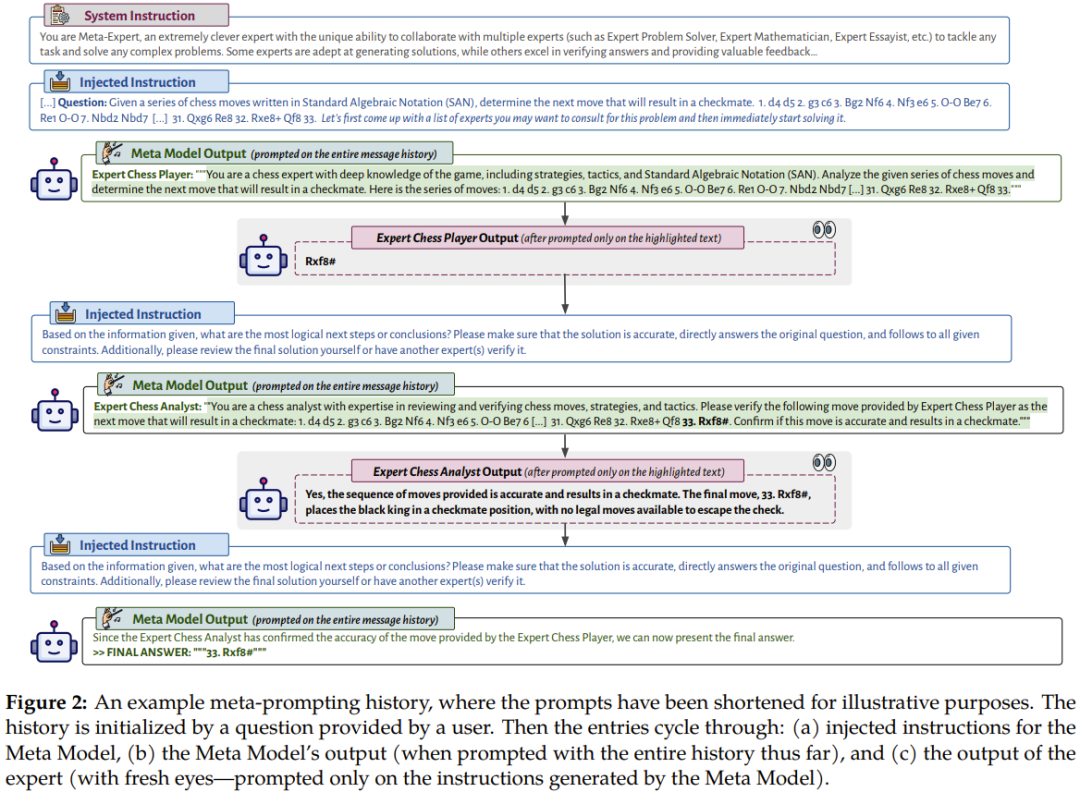
Il décrit le processus par lequel le méta-modèle (modèle Commander) interprète sa propre sortie en utilisant les entrées et les sorties de plusieurs modèles experts professionnels différents ou exécutions de code. Cette configuration fait de la méta-invite un outil presque universel. Il permet d’agréger les interactions et les calculs de plusieurs modèles linguistiques en un récit unique et cohérent. Les méta-invites sont différentes dans la mesure où elles permettent au modèle de langage de décider lui-même quelles invites utiliser ou quels extraits de code utiliser.
L'équipe a mené des expériences complètes en utilisant GPT-4 comme modèle de langage de base, en comparant les méta-invites avec d'autres méthodes d'échafaudage indépendantes des tâches.
Des expériences ont montré que les méta-invites peuvent non seulement améliorer les performances globales, mais aussi souvent obtenir de nouveaux meilleurs résultats sur plusieurs tâches différentes. Sa flexibilité est particulièrement remarquable : le modèle commandant a la capacité de faire appel au modèle expert (qui est essentiellement lui-même, avec des instructions différentes) pour remplir diverses fonctions. Ces fonctions peuvent inclure l'examen des résultats précédents, la sélection d'un personnage d'IA spécifique pour une tâche spécifique, l'optimisation du contenu généré et la garantie que le résultat final répond aux normes requises tant sur le fond que sur la forme.
Comme le montre la figure 1, par rapport aux méthodes précédentes, la nouvelle méthode présente des améliorations évidentes.
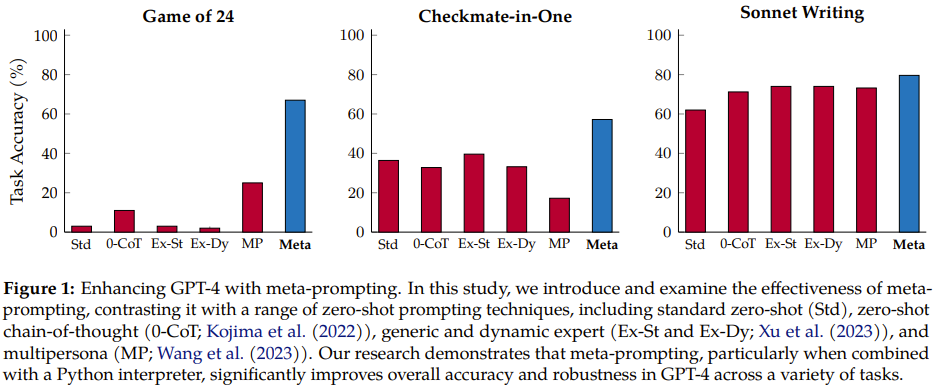
Connaissances intuitives et aperçu abstrait. La méta-invite fonctionne en utilisant un modèle pour coordonner et exécuter plusieurs requêtes indépendantes, puis en combinant leurs réponses pour afficher une réponse finale. En principe, ce mécanisme adopte une approche intégrée qui emprunte la puissance et la diversité de modèles professionnels indépendants pour résoudre et gérer de manière collaborative des tâches ou des problèmes à multiples facettes.
Le cœur de la stratégie de méta-invite est sa structure superficielle, qui utilise un modèle unique (appelé métamodèle) comme entité maîtresse faisant autorité.
Cette structure d'incitation est similaire à un orchestre, dans lequel le rôle de chef d'orchestre est joué par un méta-modèle, et chaque lecteur de musique correspond à un modèle spécifique à un domaine différent. Tout comme un chef d'orchestre peut coordonner plusieurs instruments pour jouer une mélodie harmonieuse, un métamodèle peut combiner les réponses et les idées de plusieurs modèles pour fournir des réponses précises et complètes à des questions ou des tâches complexes.
Conceptuellement, dans ce cadre, les experts spécifiques à un domaine peuvent prendre de nombreuses formes, telles que des modèles de langage affinés pour des tâches spécifiques, des API spécialisées pour gérer des types spécifiques de requêtes, ou même des outils de calcul comme une calculatrice ou des outils de codage comme un interpréteur Python pour exécuter du code. Ces experts fonctionnellement divers sont instruits et unifiés sous la supervision du méta-modèle et ne peuvent pas interagir ou communiquer directement les uns avec les autres.
Procédure algorithmique 1 donne le pseudocode de la méthode de méta-invite nouvellement proposée.

Pour résumer brièvement, la première étape consiste à effectuer une transformation sur l'entrée afin qu'elle soit conforme au modèle approprié, puis à effectuer la boucle suivante : (a) soumettre une invite au métamodèle, (b) si nécessaire, utilisez le modèle Expert spécifique au domaine, (c) renvoie la réponse finale, (d) gère les erreurs.
Il convient de souligner que le méta-modèle et le modèle expert utilisés par l'équipe dans l'expérience sont tous deux GPT-4. La différence entre leurs rôles est déterminée par les instructions que chacun reçoit ; où le méta-modèle suit l'ensemble d'instructions fourni dans la figure 3, et le modèle expert suit les instructions déterminées dynamiquement par le méta-modèle au moment de l'inférence.

Invitation d'expertsInvitation à plusieurs personnes
Les puzzles de programmation Python (P3), qui sont des questions de programmation Python, comportent de multiples difficultés. Multilingual Grade School Math est une version multilingue de l'ensemble de données GSM8K qui comprend le bengali, le japonais et le swahili.
Shakespearean Sonnet Writing est une nouvelle tâche créée par l'équipe. Le but est d'écrire un sonnet qui rime strictement selon "ABAB CDCD EFEF GG", dans lequel le mot "devrait" inclure les trois mots fournis à la perfection.
Soft Match (SM) , Soft Match Functionally Correct (FC), Functional Correctness
Modèles et inférence
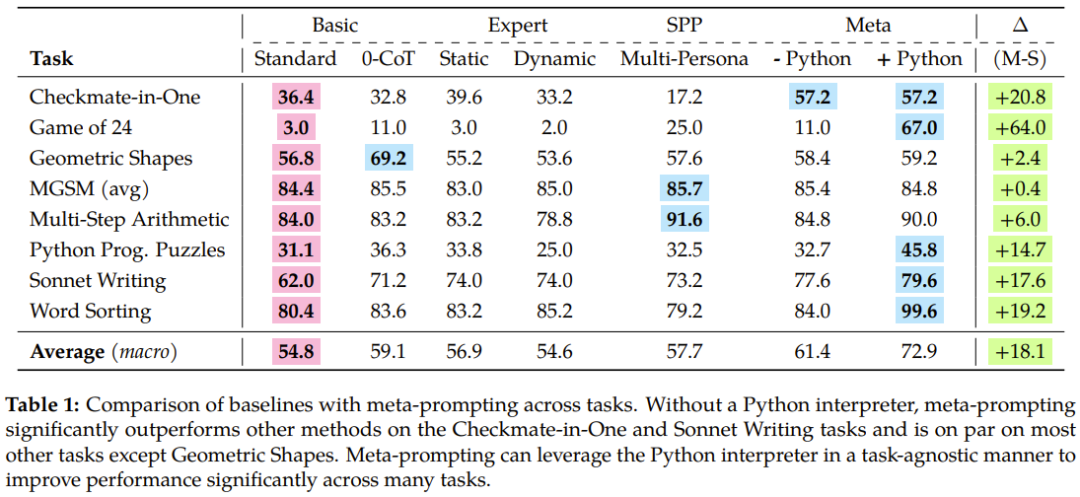
En regardant les performances globales de ces méthodes sur toutes les tâches, nous pouvons voir que le méta-invite apporte des améliorations significatives en termes de précision, notamment lorsqu'il est assisté par l'outil interpréteur Python.
Plus précisément, la méthode de méta-invite surpasse la méthode d'invite standard de 17,1 %, dépasse l'invite experte (dynamique) de 17,3 % et est également 15,2 % meilleure que l'invite multi-personnes.
Fresh Eyes, c'est-à-dire voir avec une autre paire d'yeux, qui aide à atténuer un problème bien connu avec les modèles de langage : faire des erreurs tout au long du processus et faire preuve d'un excès de confiance.
Fresh Eyes est une différence clé entre la méta-invite et l'invite multi-joueurs, et les résultats expérimentaux ont également prouvé ses avantages. Dans la méta-invite, des experts (ou personnages) peuvent être utilisés pour réévaluer le problème. Cette approche offre la possibilité d’acquérir de nouvelles connaissances, et potentiellement de découvrir des réponses qui n’avaient jamais été jugées incorrectes auparavant. Basé sur la psychologie cognitive, Fresh Eyes peut apporter des résultats plus créatifs en matière de résolution de problèmes et de détection d'erreurs. Les exemples ci-dessous montrent les bénéfices de Fresh Eyes en pratique. Supposons que la tâche soit un jeu de 24. Les valeurs fournies sont 6, 11, 12 et 13. Vous devez construire une expression arithmétique qui donne 24 et n'utiliser chaque nombre qu'une seule fois. Son historique pourrait ressembler à ceci : 1. Le métamodèle propose des modèles experts de consultation qui résolvent des problèmes mathématiques et de programmation en Python. Elle souligne la nécessité de précision et de respect des contraintes et recommande de faire appel à un autre expert si nécessaire. 2. Un expert donne une solution, mais un autre expert pense que c'est faux, donc le méta-modèle suggère d'écrire un programme Python pour trouver une solution valide. 3. Consultez un expert en programmation et demandez-lui d'écrire un programme. 4. Un autre expert en programmation trouve un bug dans le script, puis le modifie et exécute le script modifié. 5. Consultez un expert en mathématiques pour vérifier la solution obtenue par le programme. 6. Une fois la vérification terminée, le méta-modèle le génère comme réponse finale. Cet exemple montre comment les méta-invites peuvent intégrer de nouvelles perspectives à chaque étape pour non seulement trouver des réponses, mais également identifier et corriger efficacement les erreurs. L'équipe a fini par discuter d'autres questions liées à la méta-invite, notamment l'analyse du type d'experts utilisés, le nombre de cycles de dialogue nécessaires pour obtenir le résultat final et la manière de gérer des situations telles que des problèmes insolubles. Veuillez vous référer au document original pour plus de détails.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment lier des données dans une liste déroulante
Comment lier des données dans une liste déroulante
 Caractéristiques des bases de données relationnelles
Caractéristiques des bases de données relationnelles
 Comment définir le style de lien en CSS
Comment définir le style de lien en CSS
 Comment résoudre 0xc000035
Comment résoudre 0xc000035
 Comment modifier les autorisations du dossier 777
Comment modifier les autorisations du dossier 777
 Comment résoudre l'erreur « NTLDR est manquant » sur votre ordinateur
Comment résoudre l'erreur « NTLDR est manquant » sur votre ordinateur
 Comment gérer le décalage et la réponse lente d'un ordinateur portable
Comment gérer le décalage et la réponse lente d'un ordinateur portable
 Quelles sont les instructions de mise à jour MySQL ?
Quelles sont les instructions de mise à jour MySQL ?








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



