


La légendaire "arme magique" de l'architecture GPT-4 - MoE (Mixed Expert), vous pouvez l'utiliser vous-même !
Un gourou de l'apprentissage automatique sur Hugging Face a expliqué comment créer un système MoE complet à partir de zéro.

Ce projet est appelé MakeMoE par l'auteur, et le processus depuis la construction de l'attention jusqu'à la formation d'un modèle MoE complet est décrit en détail.
Selon l'auteur, MakeMoE a été inspiré et basé sur le makemore du membre fondateur d'OpenAI, Andrej Karpathy.
makemore est un projet pédagogique sur le traitement du langage naturel et l'apprentissage automatique, destiné à aider les apprenants à comprendre et à mettre en œuvre certains modèles de base.
De même, MakeMoE aide également les apprenants à mieux comprendre le modèle expert hybride dans le processus de construction étape par étape.
Alors, de quoi parle exactement ce « Guide du frottement des mains » ?
Par rapport au makemore de Karpathy, MakeMoE remplace le réseau neuronal à action directe isolé par un mélange clairsemé d'experts, tout en ajoutant la logique de déclenchement nécessaire.
Dans le même temps, comme la fonction d'activation ReLU doit être utilisée dans le processus, la méthode d'initialisation par défaut dans makemore est remplacée par la méthode Kaiming He.

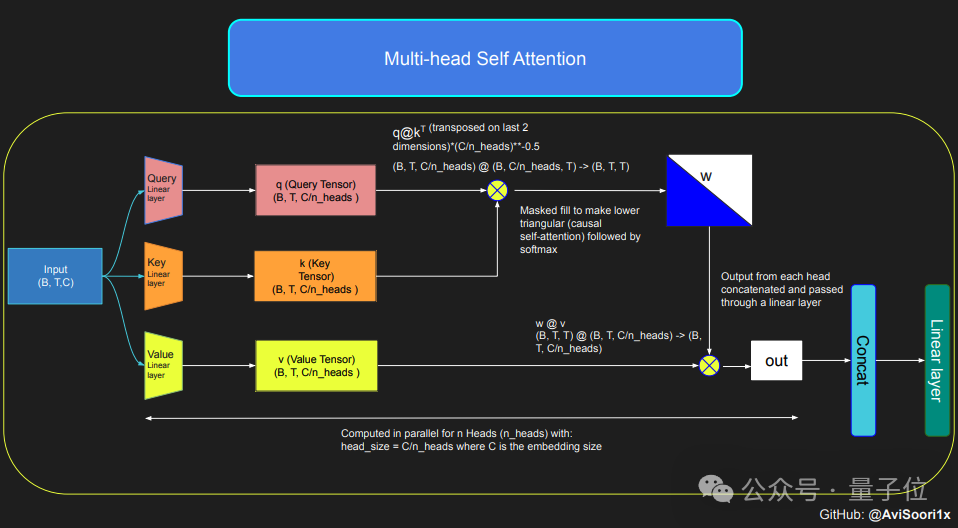
Si vous souhaitez créer un modèle MoE, vous devez d'abord comprendre le mécanisme d'auto-attention.
Le modèle transforme d'abord la séquence d'entrée en paramètres représentés par des requêtes (Q), des clés (K) et des valeurs (V) par transformation linéaire.
Ces paramètres sont ensuite utilisés pour calculer les scores d'attention, qui déterminent l'attention que le modèle accorde à chaque position de la séquence lors de la génération de chaque jeton.
Afin de garantir les caractéristiques autorégressives du modèle lors de la génération de texte, c'est-à-dire qu'il ne peut prédire le prochain jeton que sur la base du jeton déjà généré, l'auteur utilise une machine d'auto-attention causale multi-têtes.
Ce mécanisme est mis en œuvre en fixant le score d'attention des positions non traitées à l'infini négatif via un masque, afin que le poids de ces positions devienne nul.
La causalité multi-têtes permet au modèle d'effectuer plusieurs calculs d'attention de ce type en parallèle, chaque tête se concentrant sur différentes parties de la séquence.
Après avoir terminé la configuration du mécanisme d'auto-attention, vous pouvez créer le module expert. Le "module expert" est ici un perceptron multicouche.
Chaque module expert contient une couche linéaire qui mappe le vecteur d'intégration à une dimension plus grande, puis via une fonction d'activation non linéaire (telle que ReLU), et une autre couche linéaire pour mapper le vecteur à la dimension d'intégration d'origine.
Cette conception permet à chaque expert de se concentrer sur le traitement de différentes parties de la séquence d'entrée et utilise le réseau de contrôle pour décider quels experts doivent être activés lors de la génération de chaque jeton.
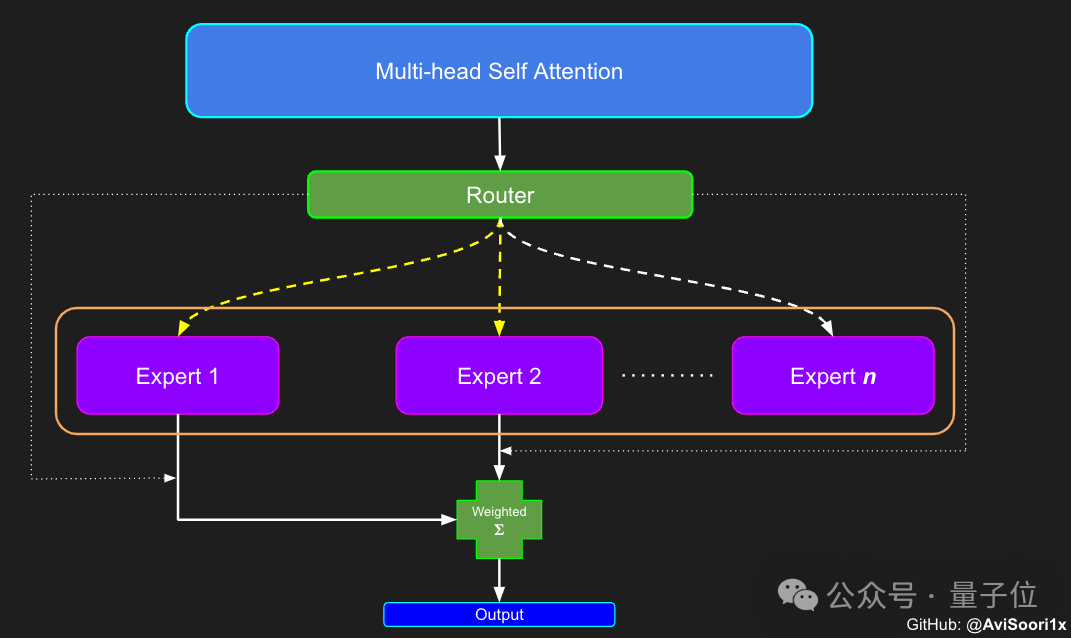
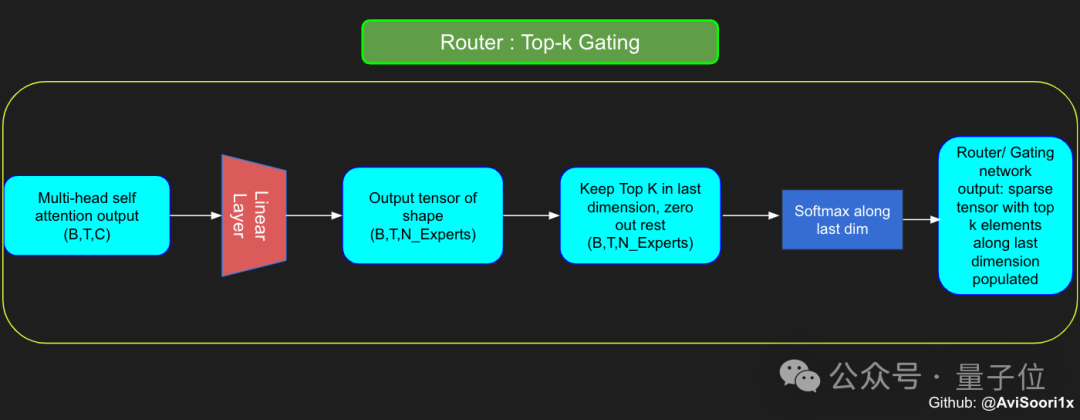
La prochaine étape consiste donc à commencer à construire le composant d'attribution et de gestion des experts - le réseau de contrôle des portes.
Le réseau de contrôle ici est également implémenté via une couche linéaire, qui mappe la sortie de la couche d'auto-attention au nombre de modules experts.
La sortie de cette couche linéaire est un vecteur de score, chaque score représente l'importance du module expert correspondant pour le jeton actuellement traité.
Le réseau fermé calculera les k premières valeurs de ce vecteur de score et enregistrera son indice, puis sélectionnera parmi elles les k premiers scores les plus élevés pour pondérer la sortie du module expert correspondant.
Afin d'augmenter l'explorabilité du modèle pendant le processus de formation, l'auteur a également introduit du bruit pour éviter que tous les jetons aient tendance à être traités par les mêmes experts.
Ce bruit est généralement obtenu en ajoutant un bruit gaussien aléatoire au vecteur fractionnaire.
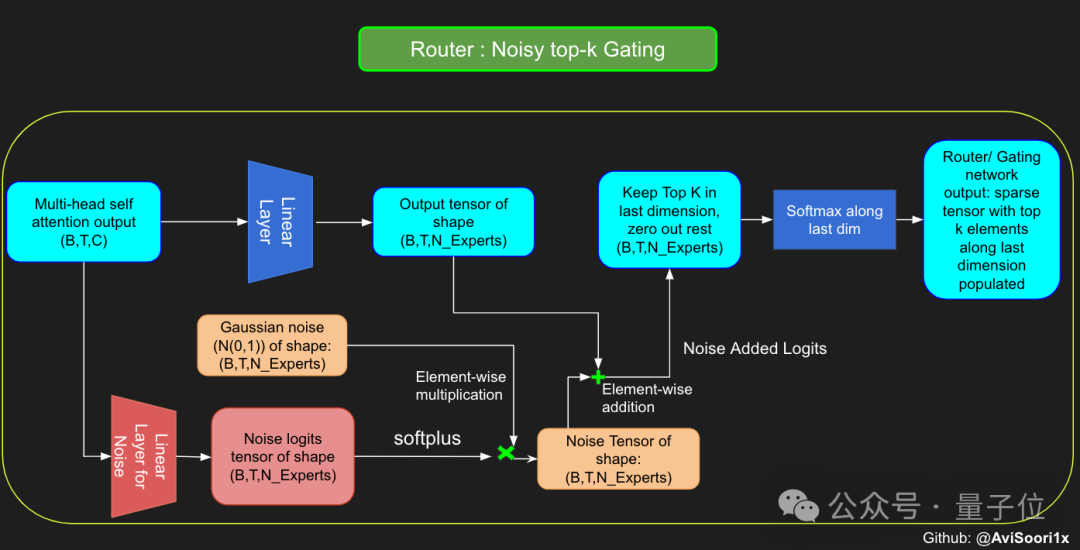
Après avoir obtenu les résultats, le modèle multiplie sélectivement les k premières valeurs avec les sorties des k meilleurs experts pour le jeton correspondant, puis les ajoute pour former une somme pondérée pour former la sortie du modèle.
Enfin, rassemblez ces modules pour obtenir un modèle MoE.
Pour l'ensemble du processus ci-dessus, l'auteur a fourni le code correspondant, vous pouvez en apprendre davantage à ce sujet dans l'article original.
De plus, l'auteur a également produit des notes Jupyter de bout en bout, qui peuvent être exécutées directement lors de l'apprentissage de chaque module.
Si vous êtes intéressé, apprenez-le vite !
Adresse originale : https://huggingface.co/blog/AviSoori1x/makemoe-from-scratch
Version note (GitHub) : https://github.com/AviSoori1x/makeMoE/tree/main
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment lier des données dans une liste déroulante
Comment lier des données dans une liste déroulante
 Quels sont les logiciels antivirus ?
Quels sont les logiciels antivirus ?
 c'est-à-dire que le raccourci ne peut pas être supprimé
c'est-à-dire que le raccourci ne peut pas être supprimé
 Détails de configuration des paramètres du vivox100s
Détails de configuration des paramètres du vivox100s
 Comment résoudre le problème selon lequel les CAO ne peuvent pas être copiés dans le presse-papiers
Comment résoudre le problème selon lequel les CAO ne peuvent pas être copiés dans le presse-papiers
 Logiciel de base de données couramment utilisé
Logiciel de base de données couramment utilisé
 Que signifie ping ?
Que signifie ping ?
 Quelles sont les exigences pour la diffusion en direct de Douyin ?
Quelles sont les exigences pour la diffusion en direct de Douyin ?








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



