


L'émergence récente de grands modèles de langage (LLM) et de leurs stratégies avancées d'indication signifie que la recherche sur les modèles de langage a fait des progrès significatifs, en particulier dans les tâches classiques de traitement du langage naturel (NLP). Une innovation importante est la technologie d’incitation à la chaîne de pensée (CoT), saluée pour sa capacité à résoudre des problèmes en plusieurs étapes. La technologie CoT suit le raisonnement séquentiel humain et démontre d'excellentes performances dans une variété de défis, notamment les tâches interdomaines, de généralisation à long terme et multilingues. Grâce à son approche de raisonnement logique étape par étape, CoT offre une interprétabilité cruciale dans des scénarios complexes de résolution de problèmes.
Bien que CoT ait fait de grands progrès, la communauté des chercheurs n'est pas encore parvenue à un consensus sur son mécanisme spécifique et pourquoi il fonctionne. Ce manque de connaissances signifie que l’amélioration des performances du CoT reste un territoire inexploré. Actuellement, les essais et erreurs constituent le principal moyen d’explorer les améliorations du CoT, car les chercheurs ne disposent pas d’une méthodologie systématique et ne peuvent s’appuyer que sur des conjectures et des expérimentations. Cependant, cela signifie également qu’il existe d’importantes opportunités de recherche dans ce domaine : développer une compréhension approfondie et structurée du fonctionnement interne des CoT. Atteindre cet objectif permettrait non seulement de démystifier les processus CoT actuels, mais ouvrirait également la voie à une application plus fiable et plus efficace de cette technique dans une variété de tâches complexes de PNL.
Des recherches menées par des chercheurs tels que l'Université Northwestern, l'Université de Liverpool et l'Institut de technologie du New Jersey explorent plus en détail la relation entre la longueur des étapes de raisonnement et l'exactitude des conclusions pour aider les gens à mieux comprendre comment résoudre efficacement le traitement du langage naturel ( PNL). Cette étude explore si l'étape d'inférence est la partie la plus critique de l'invite qui permet au texte ouvert continu (CoT) de fonctionner. Dans l'expérience, les chercheurs ont strictement contrôlé les variables, en particulier lors de l'introduction de nouvelles étapes de raisonnement, afin de garantir qu'aucune connaissance supplémentaire n'était introduite. Dans l'expérience sur échantillon zéro, les chercheurs ont ajusté l'invite initiale de « Veuillez réfléchir étape par étape » à « Veuillez réfléchir étape par étape et essayez de penser à autant d'étapes que possible ». Pour le problème du petit échantillon, les chercheurs ont conçu une expérience qui a étendu les étapes de raisonnement de base tout en gardant constants tous les autres facteurs. Grâce à ces expériences, les chercheurs ont découvert une corrélation entre la durée des étapes de raisonnement et l’exactitude des conclusions. Plus précisément, les participants avaient tendance à fournir des conclusions plus précises lorsque le message leur demandait de réfléchir à plusieurs étapes. Cela montre que lors de la résolution de problèmes de PNL, la précision de la résolution de problèmes peut être améliorée en étendant les étapes de raisonnement. Cette recherche est d'une grande importance pour une compréhension approfondie de la façon dont les problèmes de PNL sont résolus et fournit des conseils utiles pour optimiser et améliorer davantage la technologie NLP.

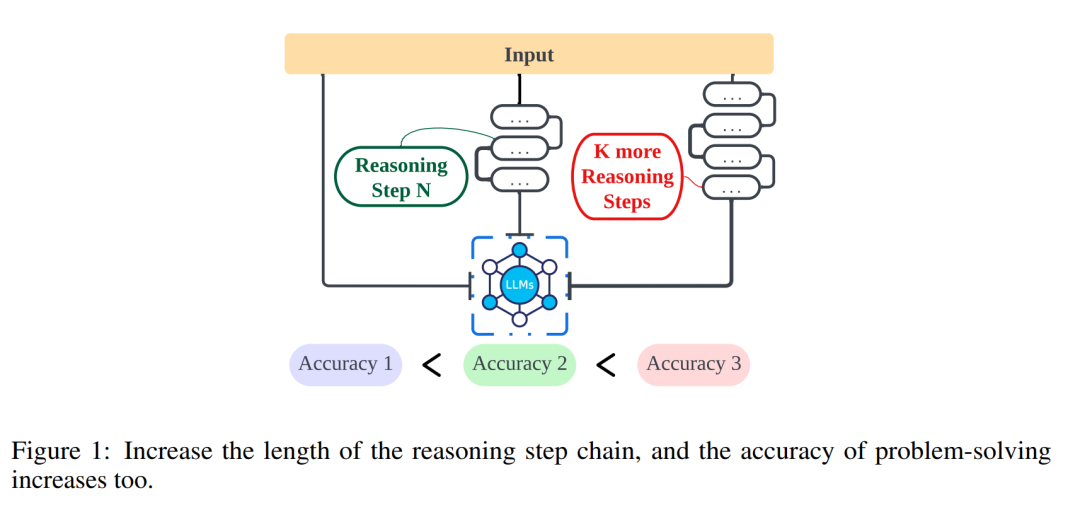
La première série d'expériences de cet article vise à évaluer l'amélioration des performances d'inférence pour les tâches à tir nul et à petit tir utilisant la technologie Auto-CoT dans le cadre de la stratégie ci-dessus. Ensuite, la précision de différentes méthodes à différents nombres d'étapes d'inférence a été évaluée. Par la suite, les chercheurs ont élargi l’objet de recherche et comparé l’efficacité de la stratégie proposée dans cet article sur différents LLM (tels que GPT-3.5 et GPT-4). Les résultats de la recherche montrent que dans une certaine fourchette, il existe une corrélation claire entre la longueur de la chaîne de raisonnement et la capacité du LLM. Il convient de considérer que lorsque les chercheurs introduisent des informations trompeuses dans la chaîne d’inférence, les performances s’améliorent encore. Cela nous amène à une conclusion importante : le facteur clé affectant la performance semble être la longueur de la chaîne de pensée, et non sa précision.
Les principales conclusions de cet article sont les suivantes :
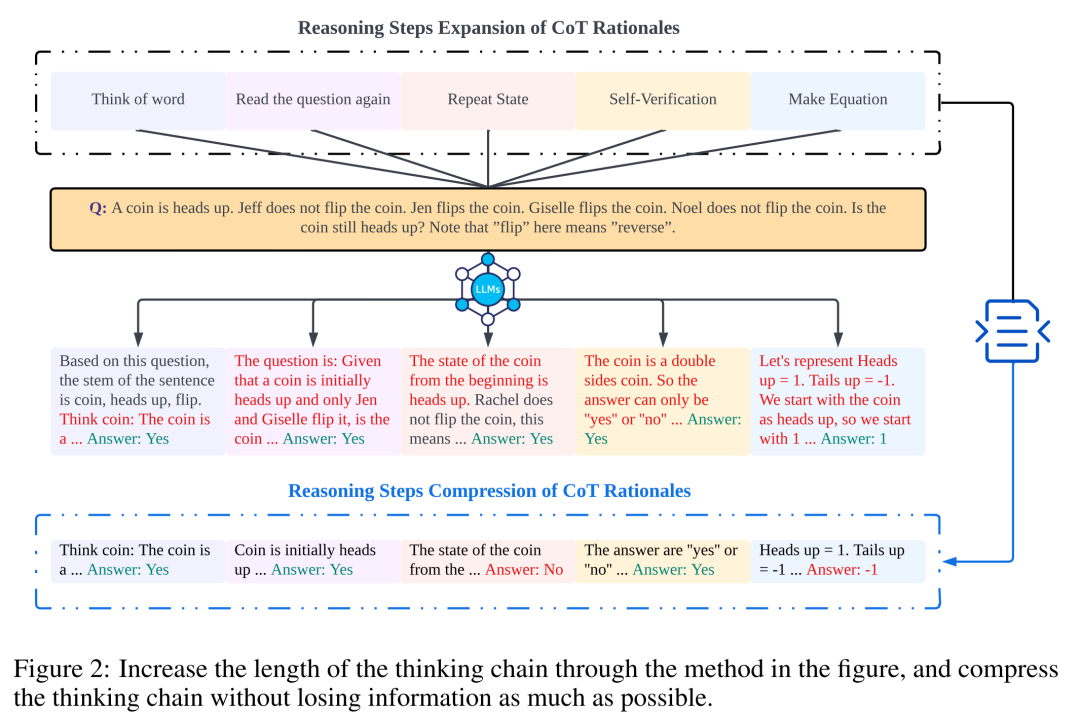
Les chercheurs ont utilisé l'analyse pour examiner la relation entre les étapes de raisonnement et les performances des invites CoT. L'hypothèse fondamentale de leur approche est que l'étape de sérialisation est la composante la plus critique des signaux CoT lors de l'inférence. Ces étapes permettent au modèle de langage d'appliquer plus de logique de raisonnement lors de la génération du contenu de réponse. Pour tester cette idée, les chercheurs ont conçu une expérience visant à modifier le processus de raisonnement du CoT en élargissant et en comprimant successivement les étapes de raisonnement de base. Dans le même temps, ils ont maintenu constants tous les autres facteurs. Plus précisément, les chercheurs ont uniquement modifié systématiquement le nombre d’étapes de raisonnement sans introduire de nouveau contenu de raisonnement ni supprimer le contenu de raisonnement existant. Ci-dessous, ils évaluent les signaux CoT à zéro et à quelques tirs. L’ensemble du processus expérimental est illustré à la figure 2. Grâce à cette approche d'analyse à variables contrôlées, les chercheurs ont élucidé comment CoT affecte la capacité de LLM à générer des réponses logiquement solides.
Analyse CoT à échantillon zéro
Dans le scénario à échantillon zéro, le chercheur a modifié l'invite initiale de "Veuillez réfléchir étape par étape" à "Veuillez réfléchir étape par étape et essayez de pensez à autant de solutions que possible" étape ". Ce changement a été apporté car contrairement à l'environnement CoT à quelques tirs, les utilisateurs ne peuvent pas introduire d'étapes d'inférence supplémentaires pendant l'utilisation. En modifiant l'invite initiale, les chercheurs ont guidé LLM vers une réflexion plus large. L'importance de cette approche réside dans sa capacité à améliorer la précision du modèle sans nécessiter de formation incrémentielle ou de méthodes d'optimisation supplémentaires basées sur des exemples, typiques des scénarios à quelques tirs. Cette stratégie de raffinement garantit un processus d'inférence plus complet et détaillé, améliorant considérablement les performances du modèle dans des conditions d'échantillon nul.
Analyse CoT sur petits échantillons
Cette section modifiera la chaîne d'inférence dans CoT en ajoutant ou en compressant des étapes d'inférence. L'objectif est d'étudier comment les changements dans la structure du raisonnement affectent les décisions du LLM. Au cours de l’expansion de l’étape d’inférence, les chercheurs doivent éviter d’introduire de nouvelles informations pertinentes pour la tâche. De cette manière, l’étape de raisonnement est devenue la seule variable étudiée.
À cette fin, les chercheurs ont conçu les stratégies de recherche suivantes pour étendre les étapes d'inférence de différentes applications LLM. Les gens ont souvent des schémas fixes dans leur façon de réfléchir aux problèmes, comme répéter le problème encore et encore pour mieux comprendre, créer des équations mathématiques pour réduire la charge de mémoire, analyser le sens des mots dans le problème pour aider à comprendre le sujet, résumer l'état actuel pour simplifier Une description du sujet. En s'inspirant du CoT à échantillon zéro et de l'Auto-CoT, les chercheurs s'attendent à ce que le processus CoT devienne un modèle standardisé et obtienne des résultats corrects en limitant la direction de la réflexion CoT dans la partie invite. Le cœur de cette méthode est de simuler le processus de pensée humaine et de remodeler la chaîne de pensée. Cinq stratégies d'invite courantes sont présentées dans le tableau 6.

En général, les stratégies en temps réel décrites dans cet article se reflètent dans le modèle. Ce qui est présenté dans le tableau 1 n'est qu'un exemple, et des exemples des quatre autres stratégies peuvent être consultés dans le document original.

La relation entre les étapes d'inférence et la précision
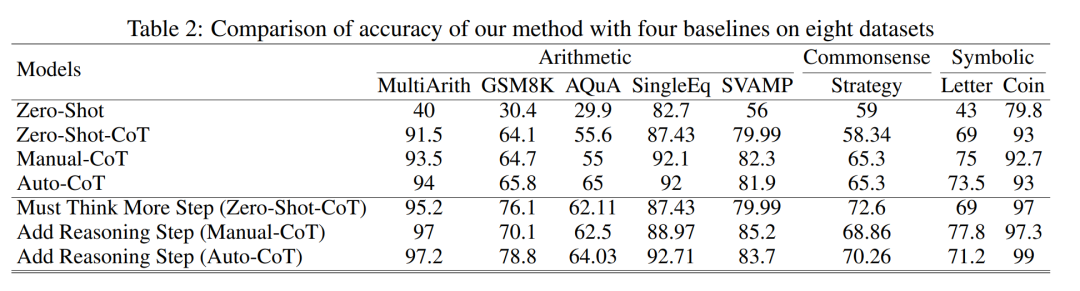
Le tableau 2 compare l'utilisation de GPT-3.5-turbo-1106 sur huit ensembles de données pour trois types de tâches d'inférence .
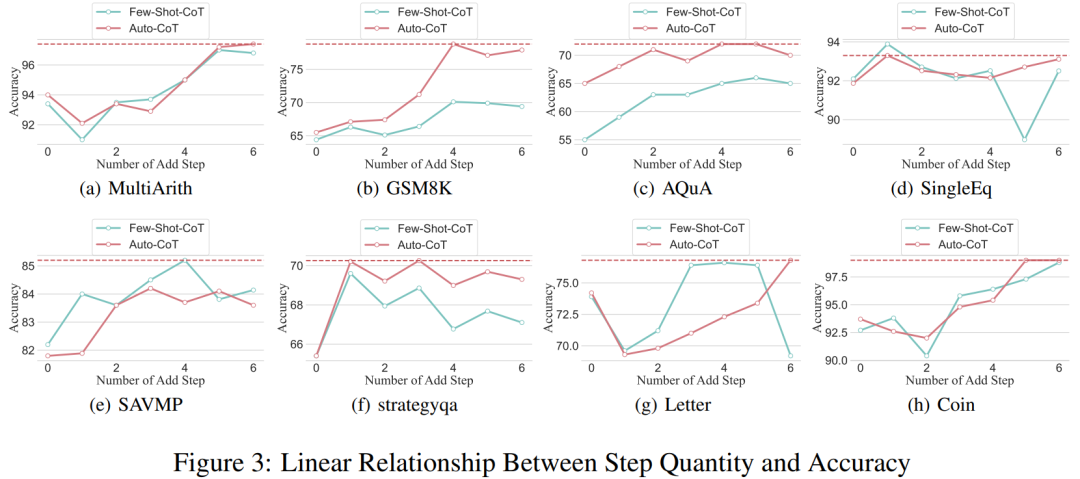
Grâce aux chercheurs ayant pu standardiser le processus de la chaîne de pensée, il est alors possible de quantifier l'amélioration de la précision en ajoutant des étapes au processus de base du CoT. Les résultats de cette expérience peuvent répondre à la question posée précédemment : quelle est la relation entre les étapes d'inférence et les performances du CoT ? Cette expérience est basée sur le modèle GPT-3.5-turbo-1106. Les chercheurs ont découvert qu'un processus CoT efficace, tel que l'ajout de six étapes supplémentaires de processus de réflexion au processus CoT, améliorerait la capacité de raisonnement des grands modèles de langage, et cela se reflète dans tous les ensembles de données. En d’autres termes, les chercheurs ont découvert une certaine relation linéaire entre la précision et la complexité du CoT.
Impact des mauvaises réponses
L'étape d'inférence est-elle le seul facteur affectant les performances du LLM ? Les chercheurs ont fait les tentatives suivantes. Remplacez une étape de l'invite par une description incorrecte et voyez si cela affecte la chaîne de pensée. Pour cette expérience, nous avons ajouté une erreur à toutes les invites. Voir le tableau 3 pour des exemples spécifiques.

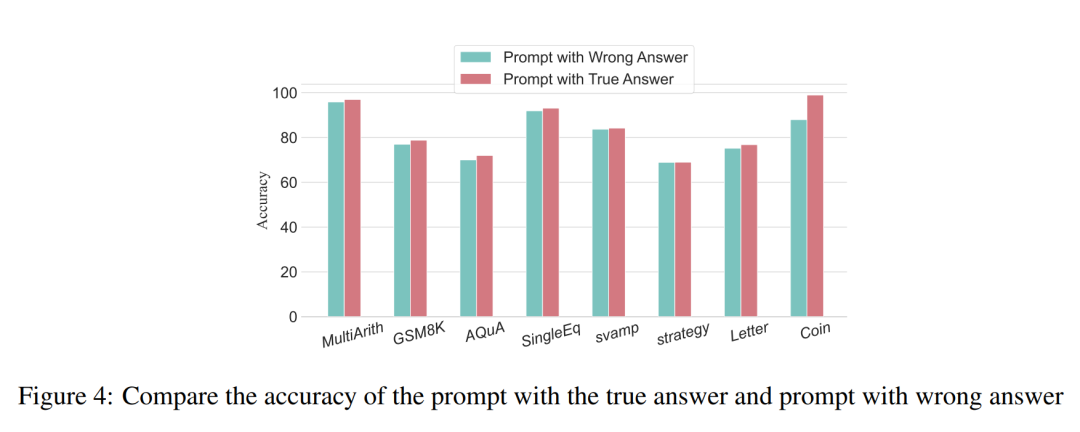
Pour les problèmes de type arithmétique, même si l'un des résultats rapides est biaisé, l'impact sur la chaîne de pensée dans le processus de raisonnement sera minime. Par conséquent, les chercheurs pensent que lors de la résolution de problèmes de type arithmétique, un langage volumineux est utilisé. les modèles sont très importants pour les invites. Il y a plus à apprendre dans la chaîne des modèles mentaux que dans un seul calcul. Pour les problèmes logiques tels que les données sur les pièces de monnaie, un écart dans le résultat rapide entraînera souvent la fragmentation de toute la chaîne de réflexion. Les chercheurs ont également utilisé GPT-3.5-turbo-1106 pour mener à bien cette expérience et ont garanti des performances basées sur le nombre optimal d'étapes pour chaque ensemble de données obtenu lors d'expériences précédentes. Les résultats sont présentés dans la figure 4.
Étapes de raisonnement compressées
Des expériences précédentes ont démontré que l'ajout d'étapes d'inférence peut améliorer la précision de l'inférence LLM. Alors, la compression des étapes d'inférence sous-jacentes nuit-elle aux performances de LLM dans les problèmes de petits échantillons ? À cette fin, les chercheurs ont mené une expérience de compression des étapes d'inférence et ont utilisé les techniques décrites dans la configuration expérimentale pour condenser le processus d'inférence en Auto CoT et Few-Shot-CoT afin de réduire le nombre d'étapes d'inférence. Les résultats sont présentés dans la figure 5.
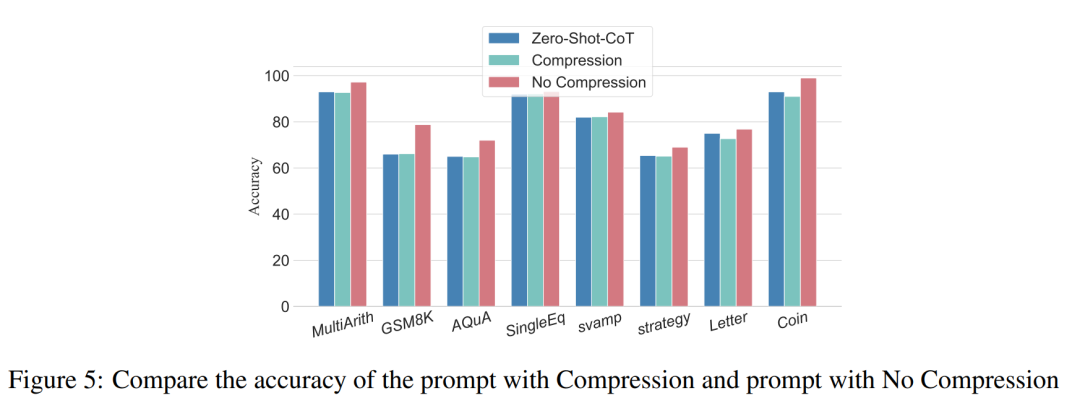
Les résultats montrent que les performances du modèle chutent significativement et reviennent à un niveau fondamentalement équivalent à la méthode de l'échantillon zéro. Ce résultat démontre en outre que l’augmentation des étapes d’inférence CoT peut améliorer les performances du CoT et vice versa.
Comparaison des performances de modèles de spécifications différentes
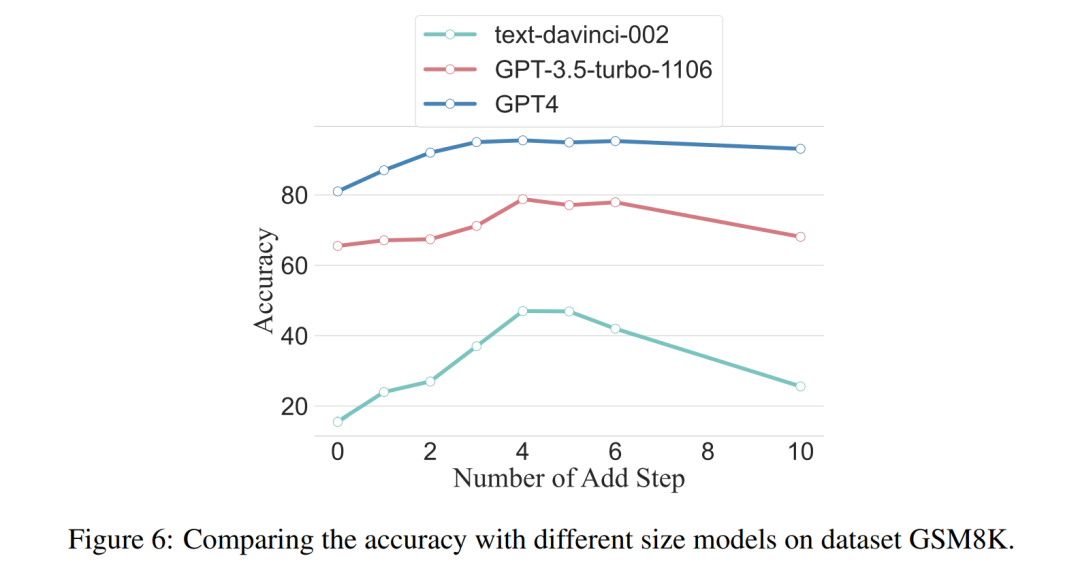
Les chercheurs ont également demandé : pouvons-nous observer le phénomène de mise à l'échelle, c'est-à-dire que les étapes d'inférence requises sont liées à la taille du LLM ? Les chercheurs ont étudié le nombre moyen d'étapes d'inférence utilisées dans divers modèles, notamment text-davinci-002, GPT-3.5-turbo-1106 et GPT-4. Les étapes d'inférence moyennes requises pour que chaque modèle atteigne des performances maximales ont été calculées grâce à des expériences sur GSM8K. Parmi les 8 ensembles de données, cet ensemble de données présente la plus grande différence de performances avec text-davinci-002, GPT-3.5-turbo-1106 et GPT-4. On peut voir que dans le modèle text-davinci-002 avec les pires performances initiales, la stratégie proposée dans cet article a l'effet d'amélioration le plus élevé. Les résultats sont présentés dans la figure 6.
Impact des problèmes dans les exemples de travail collaboratif
Quel est l'impact des problèmes sur les capacités de raisonnement LLM ? Les chercheurs voulaient déterminer si la modification du raisonnement du CoT affecterait les performances du CoT. Puisque cet article étudie principalement l’impact de l’étape d’inférence sur les performances, le chercheur doit confirmer que le problème lui-même n’a aucun impact sur les performances. Par conséquent, les chercheurs ont choisi les ensembles de données MultiArith et GSM8K et deux méthodes CoT (auto-CoT et quelques-coups-CoT) pour mener des expériences dans GPT-3.5-turbo-1106. L'approche expérimentale de cet article implique des modifications délibérées des exemples de problèmes dans ces ensembles de données mathématiques, telles que la modification du contenu des questions du tableau 4.

Il convient de noter que les observations préliminaires montrent que ces modifications du problème lui-même ont le plus faible impact sur les performances parmi plusieurs facteurs, comme le montre le tableau 5.
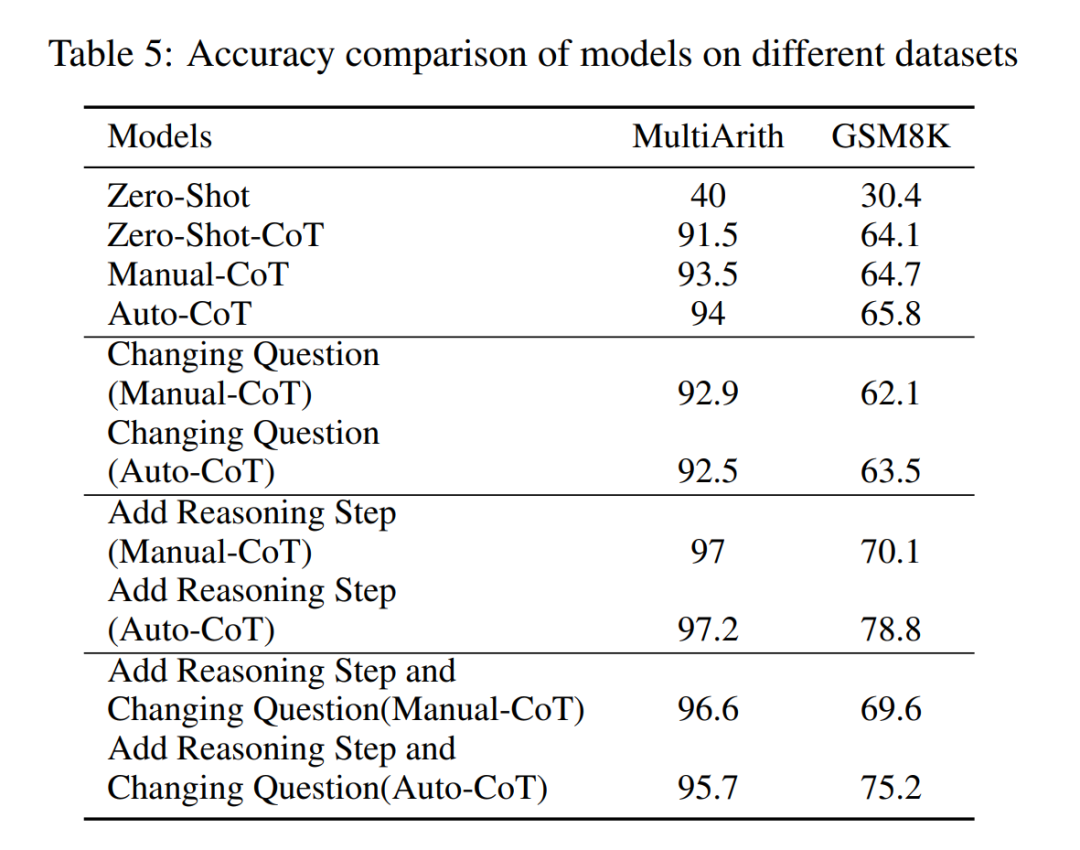
Cette découverte préliminaire montre que la longueur des étapes du processus de raisonnement est le facteur le plus important affectant la capacité de raisonnement des grands modèles, et que le problème lui-même n'est pas la plus grande influence.
Pour plus de détails, veuillez lire l'article original.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment lier des données dans une liste déroulante
Comment lier des données dans une liste déroulante
 Comment connecter PHP à la base de données mssql
Comment connecter PHP à la base de données mssql
 Méthode BigDecimal pour comparer les tailles
Méthode BigDecimal pour comparer les tailles
 Comment compresser des fichiers HTML en zip
Comment compresser des fichiers HTML en zip
 Plateforme de mégadonnées
Plateforme de mégadonnées
 psrpc.dll solution introuvable
psrpc.dll solution introuvable
 Comment vérifier l'utilisation de la mémoire JVM
Comment vérifier l'utilisation de la mémoire JVM
 Solution contre le virus de l'exe de dossier
Solution contre le virus de l'exe de dossier








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



