


L'acquisition de données de haute qualité est devenue un goulot d'étranglement majeur dans la formation actuelle des grands modèles.
Il y a quelques jours, OpenAI a été poursuivi en justice par le New York Times et a exigé des milliards de dollars de compensation. La plainte énumère plusieurs preuves de plagiat par GPT-4.
Même le New York Times a appelé à la destruction de presque tous les grands modèles comme le GPT.

De nombreux grands noms de l’industrie de l’IA croient depuis longtemps que les « données synthétiques » pourraient être la meilleure solution à ce problème.

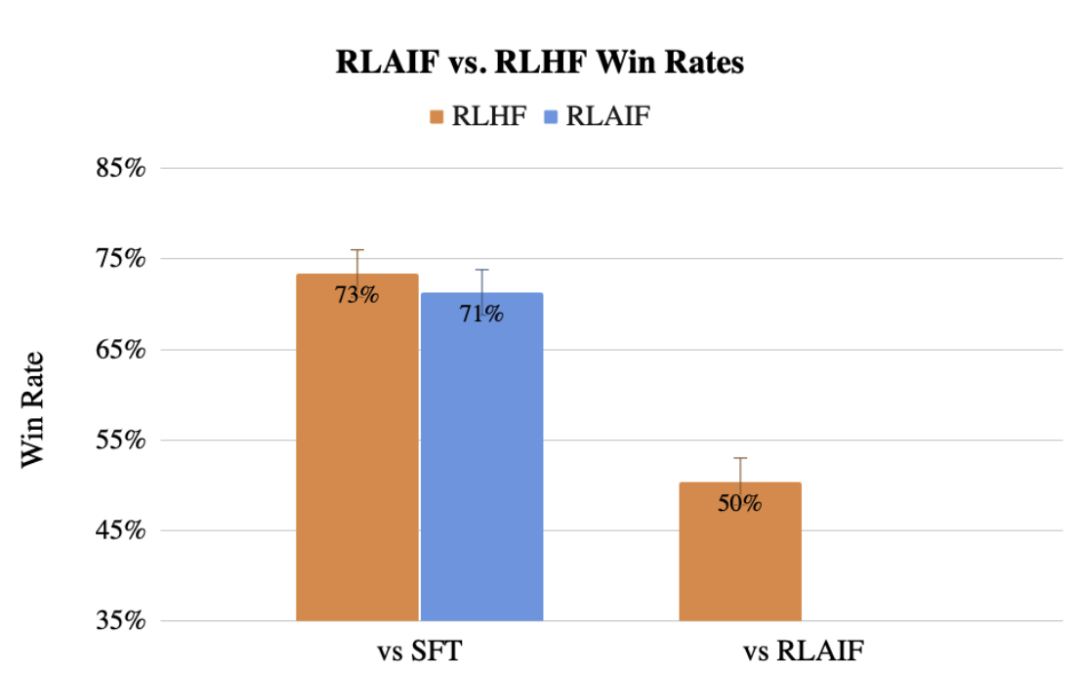
Auparavant, l'équipe de Google a également proposé une méthode d'utilisation de LLM pour remplacer les préférences d'étiquetage humaines RLAIF, et l'effet n'est même pas inférieur à celui des humains.
Maintenant, des chercheurs de Google et du MIT ont découvert que l'apprentissage à partir de grands modèles peut conduire à des représentations des meilleurs modèles formés à l'aide de données réelles.
Cette dernière méthode s'appelle SynCLR, une méthode d'apprentissage de représentations virtuelles entièrement à partir d'images synthétiques et de descriptions synthétiques, sans aucune donnée réelle.

Adresse papier : https://arxiv.org/abs/2312.17742
Les résultats expérimentaux montrent que la représentation apprise grâce à la méthode SynCLR peut être aussi bonne que l'effet de transmission du CLIP d'OpenAI sur ImageNet .
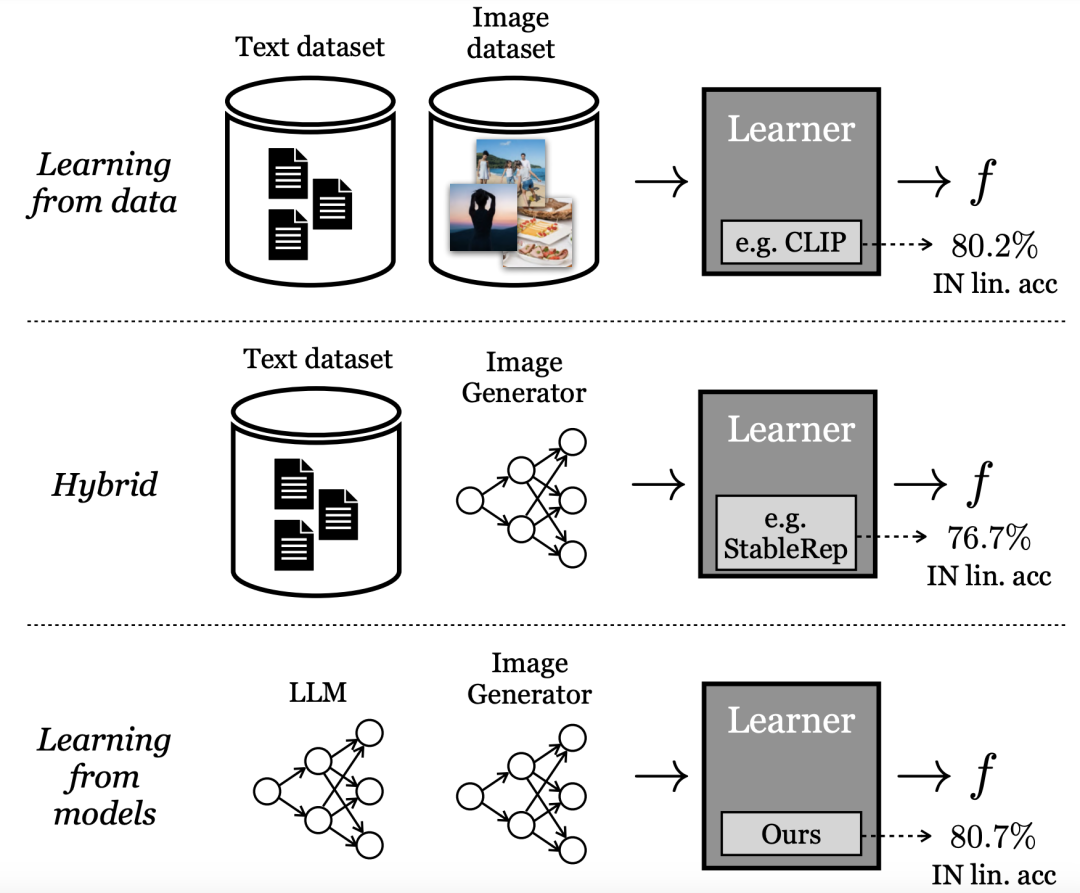
Les méthodes d'apprentissage par « représentation visuelle » les plus performantes s'appuient actuellement sur des ensembles de données réelles à grande échelle. Cependant, la collecte de données réelles se heurte à de nombreuses difficultés.
Pour réduire le coût de la collecte de données, les chercheurs de cet article posent la question :
Les données synthétiques échantillonnées à partir de modèles génératifs disponibles dans le commerce constituent-elles une voie viable vers des ensembles de données organisés à grande échelle ? former des représentations visuelles de pointe ?
Différent de l'apprentissage direct à partir des données, les chercheurs de Google appellent ce mode « apprentissage à partir du modèle ». En tant que source de données pour créer des ensembles de formation à grande échelle, les modèles présentent plusieurs avantages :
- Fournir de nouvelles méthodes de contrôle pour la gestion des données via leurs variables latentes, variables conditionnelles et hyperparamètres.
- Les modèles sont également plus faciles à partager et à stocker (puisque les modèles sont plus faciles à compresser que les données) et peuvent produire un nombre illimité d'échantillons de données.
De plus en plus de littérature étudie ces propriétés ainsi que d'autres avantages et inconvénients des modèles génératifs en tant que source de données pour la formation de modèles en aval.
Certaines de ces méthodes adoptent un modèle hybride, c'est-à-dire mélangent des ensembles de données réelles et synthétiques, ou nécessitent qu'un ensemble de données réels génère un autre ensemble de données synthétiques.
D'autres méthodes tentent d'apprendre des représentations à partir de « données purement synthétiques » mais sont loin derrière les modèles les plus performants.
Dans l'article, la dernière méthode proposée par les chercheurs utilise un modèle génératif pour redéfinir la granularité des classes de visualisation.
Comme le montre la figure 2, quatre images ont été générées à l'aide de 2 astuces "Un golden retriever portant des lunettes de soleil et un chapeau de plage faisant du vélo" et "Un joli golden retriever assis sur une maison faite de sushi" à l'intérieur".
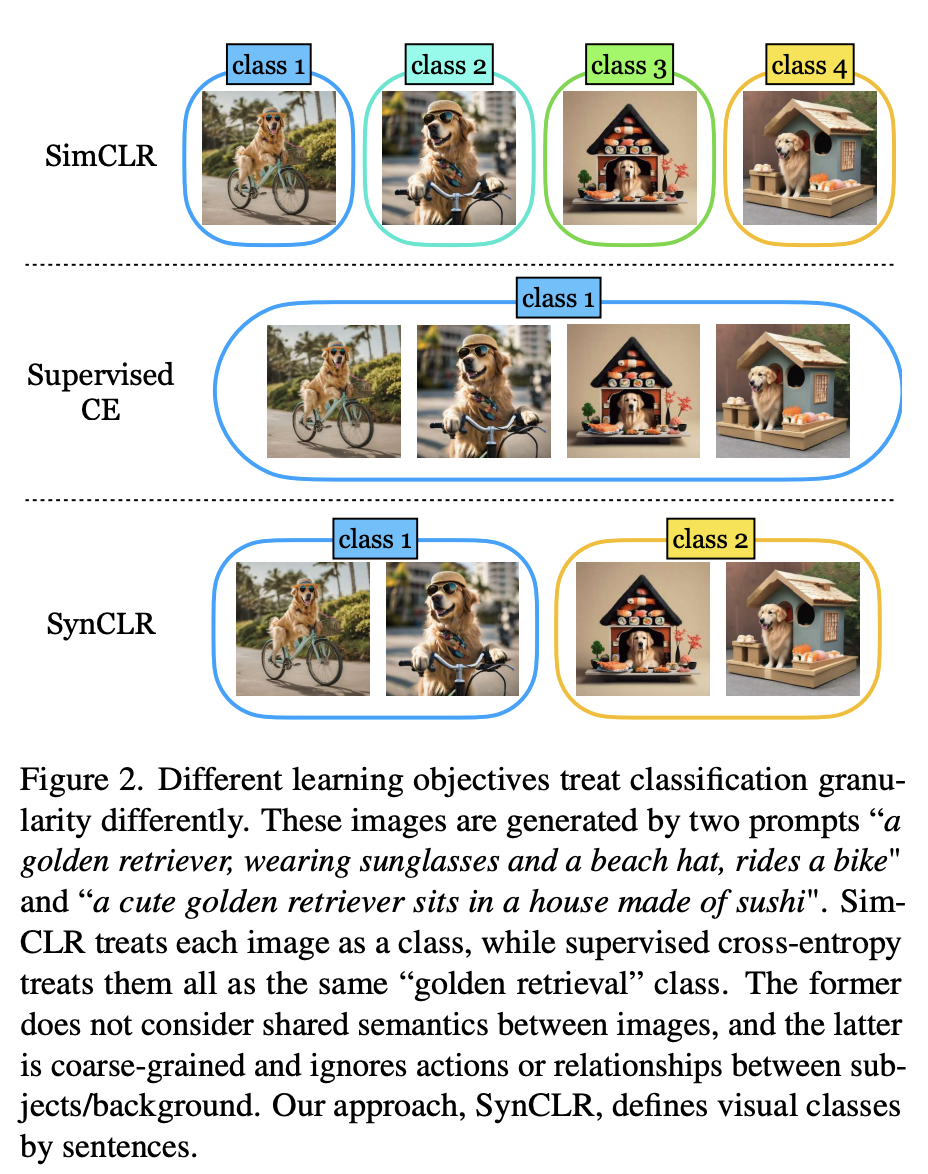
Les méthodes traditionnelles auto-supervisées (telles que Sim-CLR) traiteront ces images comme des classes différentes, et les intégrations de différentes images seront séparées, sans prendre explicitement en compte la sémantique partagée entre les images.
À l'autre extrême, les méthodes d'apprentissage supervisé (c'est-à-dire SupCE) traitent toutes ces images comme une seule classe (comme "golden retriever"). Cela ignore les nuances sémantiques des images, comme un chien faisant du vélo dans une paire d'images et un chien assis dans une maison de sushi dans une autre.
En revanche, l'approche SynCLR traite les descriptions comme des classes, c'est-à-dire une classe de visualisation par description.
De cette façon, nous pouvons regrouper les images selon les deux concepts « faire du vélo » et « s'asseoir dans un restaurant de sushi ».
Ce type de granularité est difficile à exploiter dans des données réelles car collecter plusieurs images par une description donnée n'est pas anodin, surtout lorsque le nombre de descriptions augmente.
Cependant, le modèle de diffusion texte-image a fondamentalement cette capacité.
En conditionnant simplement la même description et en utilisant différentes entrées de bruit, le modèle de diffusion texte-image peut générer différentes images qui correspondent à la même description.
Plus précisément, les auteurs étudient le problème de l'apprentissage des encodeurs visuels sans données d'image ou de texte réelles.
La dernière approche repose sur l'utilisation de 3 ressources clés : un modèle génératif de langage (g1), un modèle génératif de texte en image (g2) et une liste organisée de concepts visuels (c).
Le pré-traitement comprend trois étapes :
(1) Utilisez (g1) pour synthétiser un ensemble complet de descriptions d'images T, qui couvrent divers concepts visuels en C
(2) Pour Pour chacun ; titre dans T, plusieurs images sont générées à l'aide de (g2), générant finalement un vaste ensemble de données d'images synthétiques X
(3) est entraîné sur X pour obtenir un encodeur de représentation visuelle f ;
Ensuite, utilisez lama-27b et Stable Diffusion 1.5 comme (g1) et (g2) respectivement en raison de sa vitesse d'inférence rapide.
Descriptions synthétiques
Afin d'exploiter la puissance de puissants modèles texte-image pour générer de grands ensembles de données d'images d'entraînement, nous avons d'abord besoin d'un ensemble de descriptions qui non seulement décrivent avec précision les images, mais présentent également de la diversité. pour inclure un large éventail de concepts visuels.
En réponse, les auteurs ont développé une méthode évolutive pour créer un si grand ensemble de descriptions, en tirant parti des capacités d'apprentissage contextuel des grands modèles.
Ce qui suit montre trois exemples de modèles synthétiques.

Ce qui suit utilise Llama-2 pour générer des descriptions de contexte. Les chercheurs ont échantillonné au hasard trois exemples de contexte dans chaque exécution d'inférence.
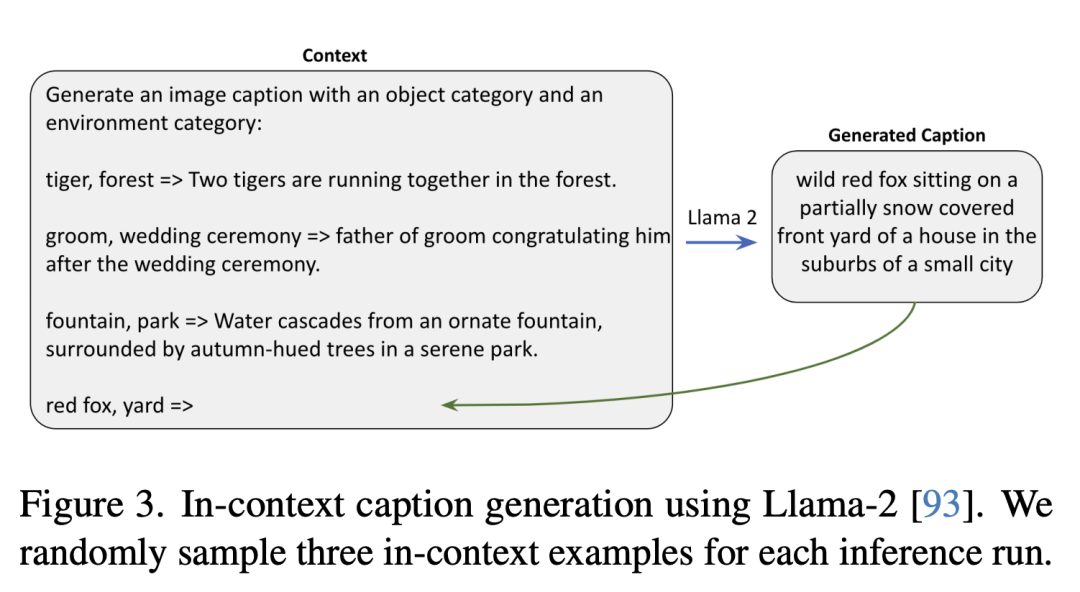
Images synthétiques
Pour chaque description textuelle, les chercheurs ont lancé le processus de rétrodiffusion avec différents bruits aléatoires, ce qui a donné lieu à diverses images.
Dans ce processus, le ratio CFG (classifier-free bootstrapping) est un facteur clé.
Plus l'échelle CFG est élevée, meilleure est la qualité des échantillons et la cohérence entre le texte et les images, tandis que plus l'échelle est basse, plus la diversité des échantillons est grande et meilleure est la cohérence entre les images basées sur le texte original conditionnel donné. distribution.

Apprentissage par représentation
Dans l'article, la méthode d'apprentissage par représentation est basée sur StableRep.
L'élément clé de la méthode proposée par les auteurs est la perte d'apprentissage par contraste multi-positif, qui fonctionne en alignant (dans l'espace d'intégration) les images générées à partir de la même description.
De plus, diverses techniques issues d'autres méthodes d'apprentissage auto-supervisées ont également été combinées dans la recherche.
Dans l'évaluation expérimentale, les chercheurs ont d'abord mené des études d'ablation pour évaluer l'efficacité de diverses conceptions et modules au sein du pipeline, puis ont continué à augmenter la quantité de données synthétiques.
L'image ci-dessous est une comparaison de différentes stratégies de synthèse de descriptions.
Les chercheurs rapportent la précision de l'évaluation linéaire et la précision moyenne d'ImageNet sur 9 ensembles de données à grain fin. Chaque élément comprend ici 10 millions de descriptions et 4 images par description.
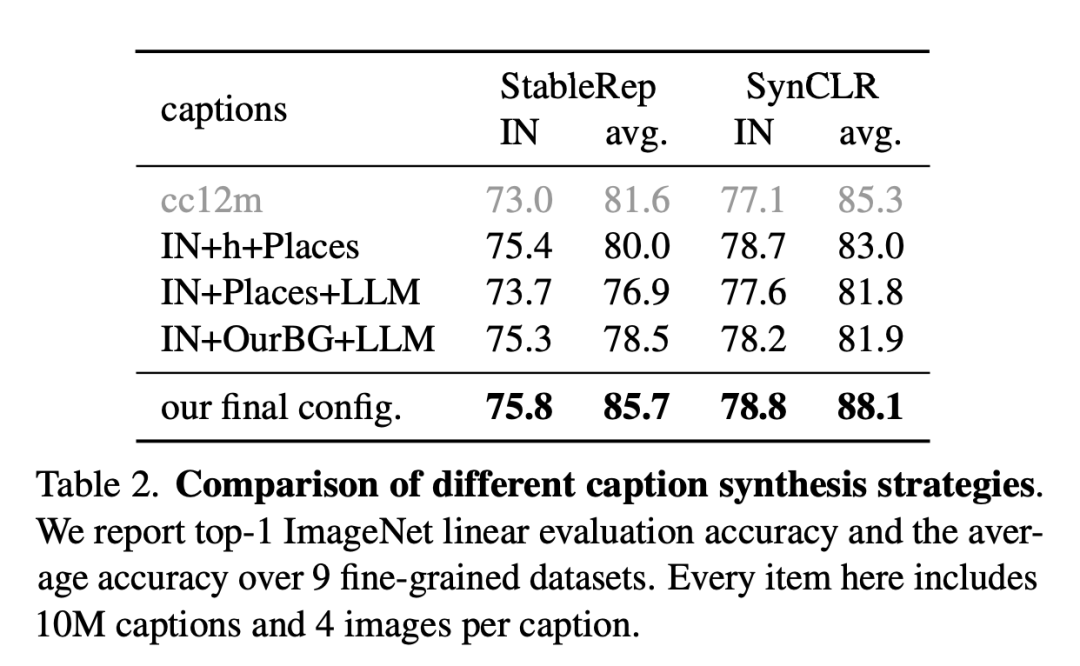
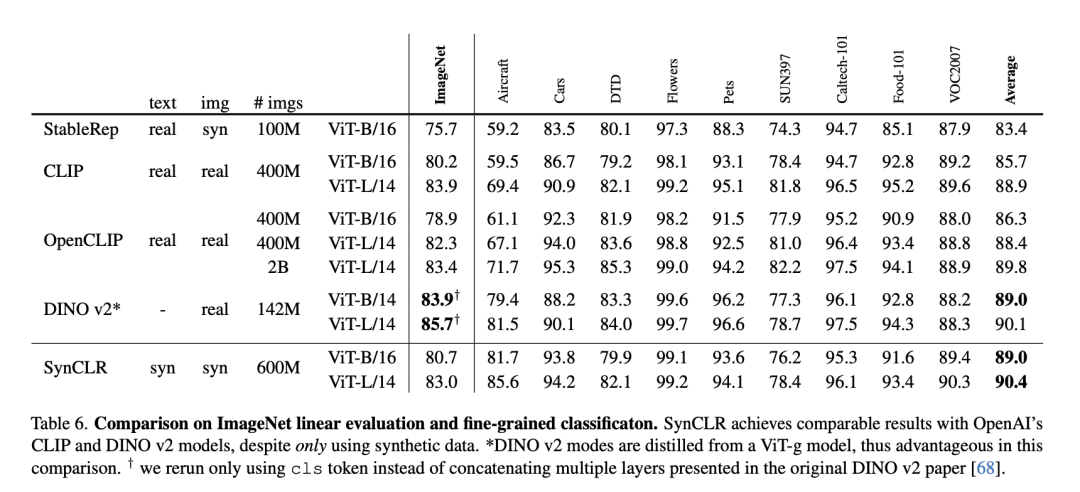
Le tableau suivant est une comparaison de l'évaluation linéaire ImageNet et de la classification à grain fin.
Malgré l'utilisation uniquement de données synthétiques, SynCLR a obtenu des résultats comparables à ceux des modèles CLIP et DINO v2 d'OpenAI.
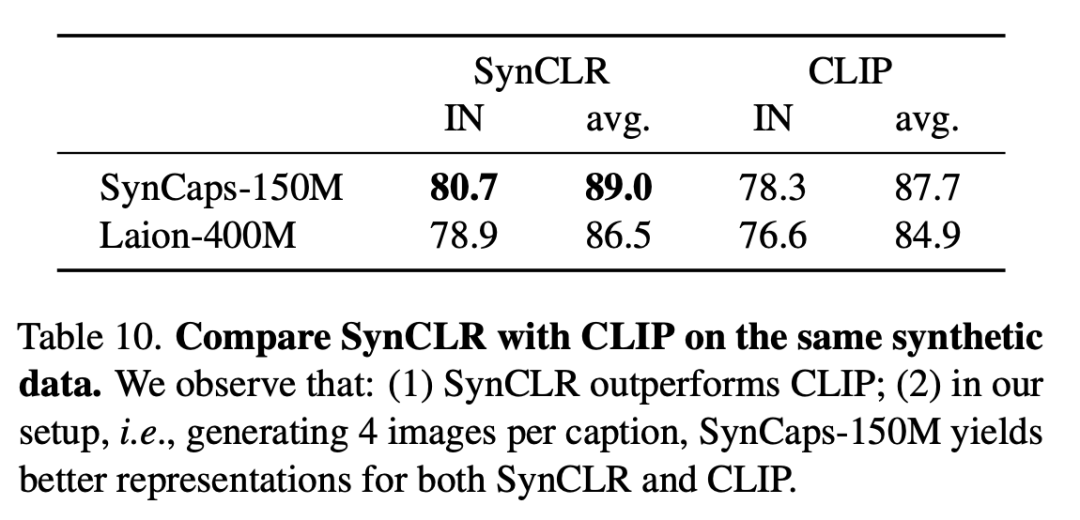
Le tableau suivant compare SynCLR et CLIP sur les mêmes données synthétiques. On voit que SynCLR est nettement meilleur que CLIP.
Spécifiquement configuré pour générer 4 images par titre, SynCaps-150M offre une meilleure représentation pour SynCLR et CLIP.
La visualisation PCA est la suivante. Suite à DINO v2, les chercheurs ont calculé la PCA entre les patchs du même ensemble d’images et les ont colorés en fonction de leurs 3 premiers composants.
Comparé à DINO v2, SynCLR est plus précis pour les dessins de voitures et d'avions, mais légèrement pire pour les dessins qui peuvent être dessinés.

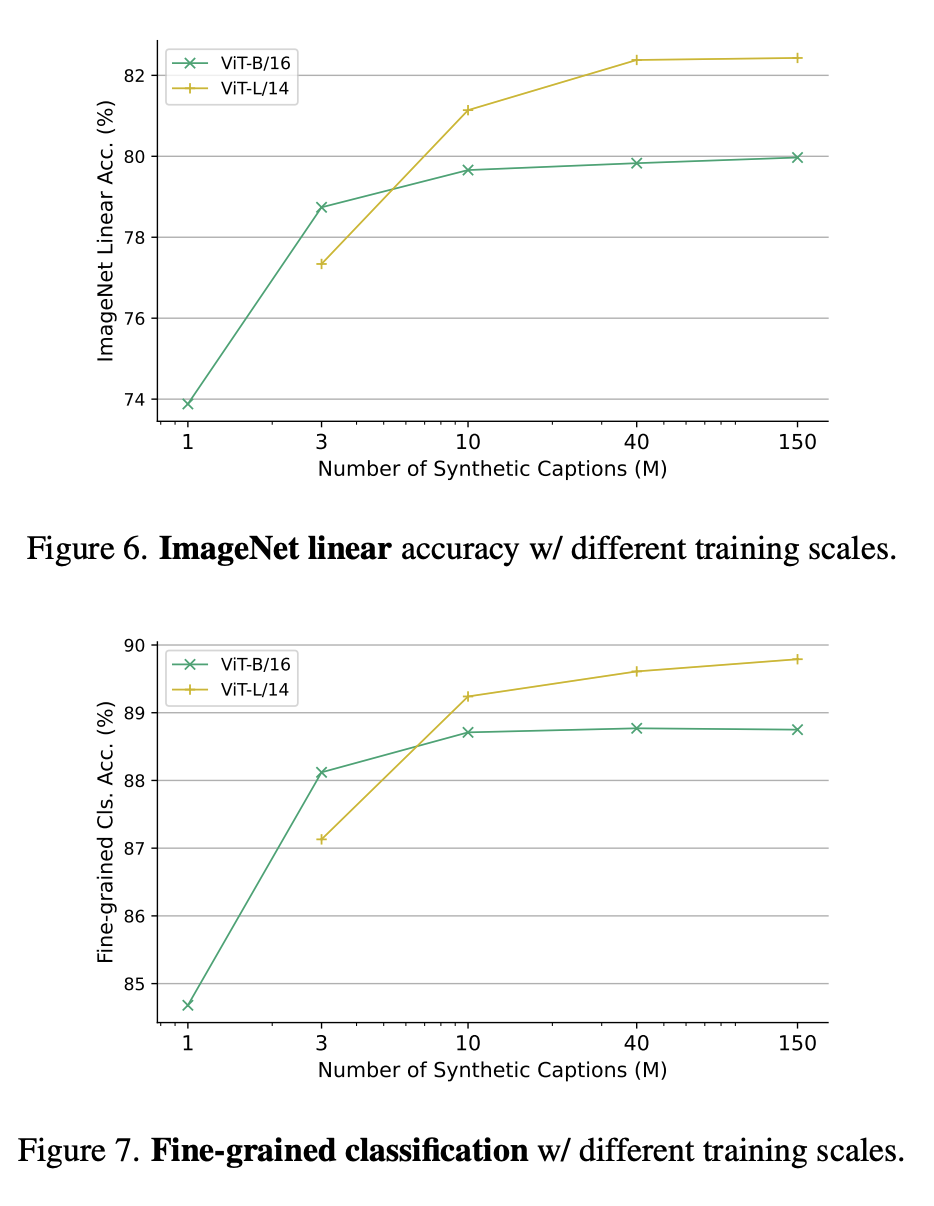
La figure 6 et la figure 7 montrent respectivement la précision linéaire d'ImageNet sous différentes échelles de formation et la classification fine sous différentes échelles de paramètres de formation.
Pourquoi apprendre des modèles génératifs ?
Une raison impérieuse est que les modèles génératifs peuvent fonctionner sur des centaines d'ensembles de données simultanément, offrant ainsi un moyen pratique et efficace de conserver les données d'entraînement.
En résumé, le dernier article étudie un nouveau paradigme d'apprentissage des représentations visuelles : l'apprentissage à partir de modèles génératifs.
Les représentations visuelles apprises par SynCLR sont comparables à celles apprises par les apprenants de pointe en représentation visuelle à usage général sans utiliser de données réelles.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



