


De manière générale, le déploiement de grands modèles de langage adopte généralement la méthode du « pré-entraînement-réglage fin ». Cependant, lorsque l’on peaufine le modèle de base pour plusieurs tâches (telles que les assistants personnalisés), le coût de la formation et du service devient très élevé. L'adaptation LowRank (LoRA) est une méthode efficace de réglage fin des paramètres, qui est généralement utilisée pour adapter le modèle de base à plusieurs tâches, générant ainsi un grand nombre d'adaptateurs LoRA dérivés
Réécrit : L'inférence par lots offre de nombreuses opportunités pendant le service, et il a été démontré que ce modèle permet d'obtenir des performances comparables à un réglage fin complet en ajustant avec précision les poids des adaptateurs. Bien que cette approche permette une inférence à faible latence sur un seul adaptateur et une exécution en série sur plusieurs adaptateurs, elle réduit considérablement le débit global du service et augmente la latence globale lors du service simultané de plusieurs adaptateurs. Par conséquent, on ne sait toujours pas comment résoudre le problème de service à grande échelle de ces variantes affinées.
Récemment, des chercheurs de l'UC Berkeley, Stanford et d'autres universités ont proposé une nouvelle méthode de réglage fin appelée S-LoRA dans un article

S-LoRA est un système conçu pour le service évolutif de nombreux adaptateurs LoRA. Il stocke tous les adaptateurs dans la mémoire principale et récupère l'adaptateur utilisé par la requête en cours d'exécution dans la mémoire GPU.
S-LoRA propose la technologie "Unified Paging", qui utilise un pool de mémoire unifié pour gérer différents niveaux de poids d'adaptateur dynamiques et des tenseurs de cache KV de différentes longueurs de séquence. De plus, S-LoRA utilise une nouvelle stratégie de parallélisme tensoriel et des noyaux CUDA personnalisés hautement optimisés pour permettre le traitement par lots hétérogène des calculs LoRA.
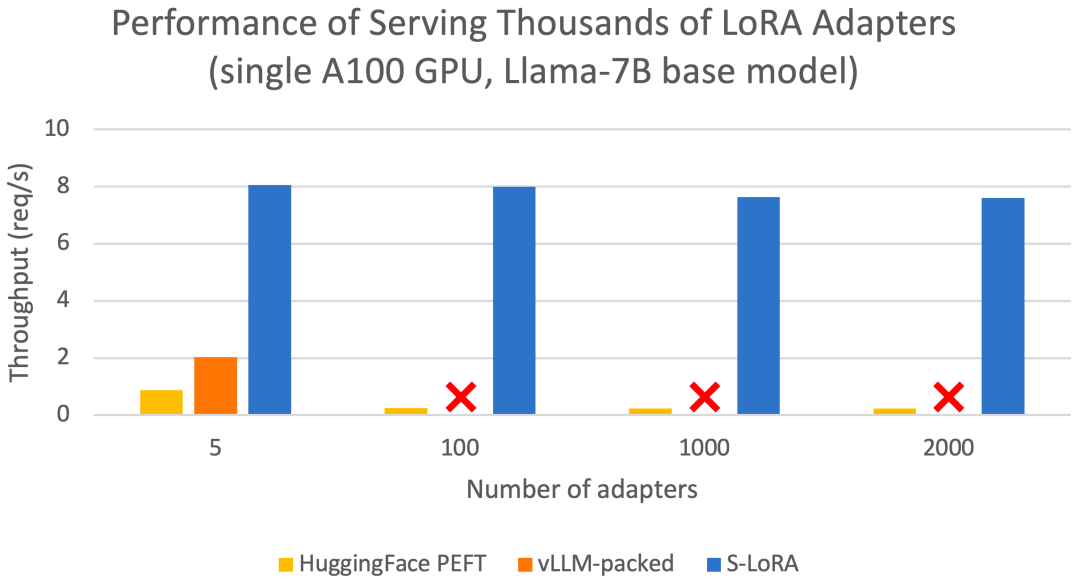
Ces fonctionnalités permettent à S-LoRA de servir des milliers d'adaptateurs LoRA sur un ou plusieurs GPU à une fraction du coût (desservant 2000 adaptateurs simultanément) et de minimiser les coûts de calcul LoRA supplémentaires. En comparaison, vLLM-packed doit conserver plusieurs copies de poids et ne peut servir que moins de 5 adaptateurs en raison des limitations de mémoire GPU
Par rapport aux technologies de pointe telles que HuggingFace PEFT et vLLM (prend uniquement en charge le service LoRA ) Par rapport à la bibliothèque, le débit de S-LoRA peut être augmenté jusqu'à 4 fois et le nombre d'adaptateurs servis peut être augmenté de plusieurs ordres de grandeur. Par conséquent, S-LoRA est en mesure de fournir des services évolutifs pour de nombreux modèles de réglage précis spécifiques à des tâches et offre le potentiel de personnalisation à grande échelle des services de réglage fin.
S-LoRA contient trois principales parties innovantes. La section 4 présente la stratégie de traitement par lots utilisée pour décomposer les calculs entre le modèle de base et l'adaptateur LoRA. En outre, les chercheurs ont également résolu les problèmes de planification de la demande, notamment des aspects tels que le regroupement d'adaptateurs et le contrôle d'admission. La possibilité de traiter par lots sur des adaptateurs simultanés pose de nouveaux défis en matière de gestion de la mémoire. Dans la cinquième partie, les chercheurs font la promotion de PagedAttention to Unfied Paging pour prendre en charge le chargement dynamique des adaptateurs LoRA. Cette approche utilise un pool de mémoire unifié pour stocker le cache KV et les poids de l'adaptateur de manière paginée, ce qui peut réduire la fragmentation et équilibrer les tailles changeantes dynamiquement du cache KV et des poids de l'adaptateur. Enfin, la partie 6 présente une nouvelle stratégie tensorielle parallèle qui peut découpler efficacement le modèle de base et l'adaptateur LoRA
Voici les points forts :
Pour un seul adaptateur, Hu et al. (2021) ont proposé une méthode recommandée, qui consiste à fusionner les poids de l'adaptateur avec les poids du modèle de base, ce qui donne lieu à un nouveau modèle (voir l'équation 1). L'avantage est qu'il n'y a pas de surcharge d'adaptateur supplémentaire pendant l'inférence puisque le nouveau modèle a le même nombre de paramètres que le modèle de base. En fait, il s'agissait également d'une caractéristique notable du travail LoRA original
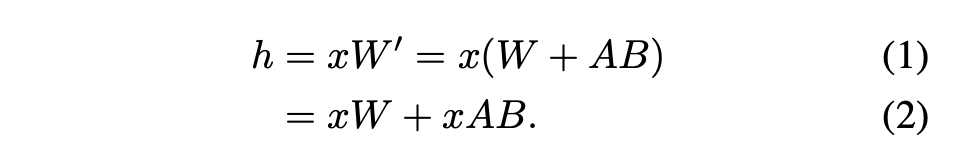
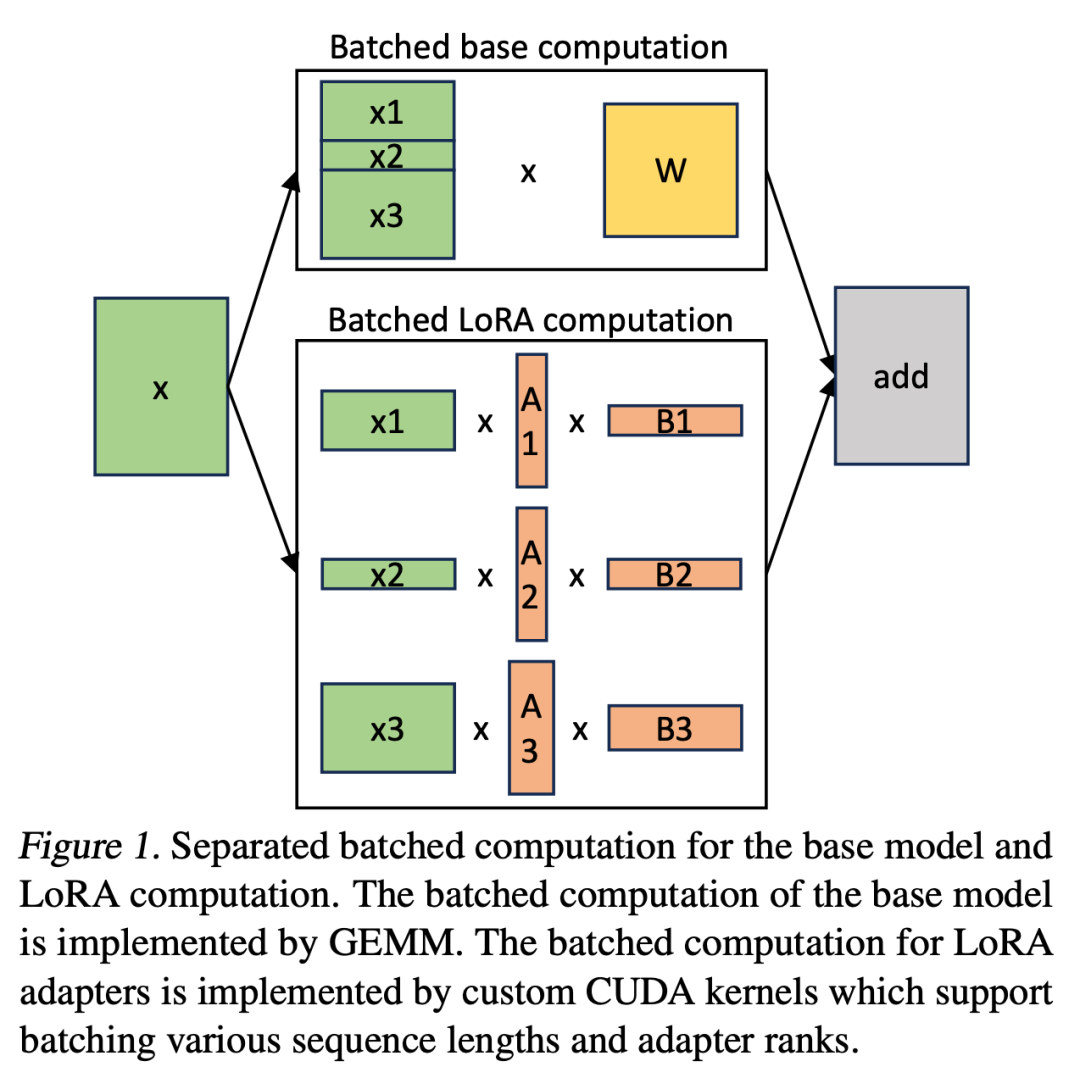
Cet article souligne que la fusion des adaptateurs LoRA dans le modèle de base est inefficace pour les configurations de services multi-LoRA à haut débit. Au lieu de cela, les chercheurs proposent de calculer LoRA en temps réel pour calculer xAB (comme le montre l’équation 2).
Dans S-LoRA, le calcul du modèle de base est effectué par lots, puis un xAB supplémentaire est effectué pour tous les adaptateurs individuellement à l'aide d'un noyau CUDA personnalisé. Ce processus est illustré à la figure 1. Au lieu d'utiliser le remplissage et les noyaux GEMM par lots de la bibliothèque BLAS pour calculer LoRA, nous avons implémenté un noyau CUDA personnalisé pour obtenir un calcul plus efficace sans remplissage. Les détails d'implémentation se trouvent dans la sous-section 5.3.
Le nombre d'adaptateurs LoRA pourrait être important s'ils étaient stockés dans la mémoire principale, mais actuellement, le nombre d'adaptateurs LoRA requis pour exécuter un lot est contrôlable car la taille du lot est limitée par la mémoire GPU. Pour en profiter, nous stockons tous les adaptateurs LoRA dans la mémoire principale et, lors de l'inférence pour le lot en cours d'exécution, récupérons uniquement les adaptateurs LoRA requis pour ce lot dans la RAM GPU. Dans ce cas, le nombre maximum d'adaptateurs réparables est limité par la taille de la mémoire principale. La figure 2 illustre ce processus. La section 5 aborde également les techniques de gestion efficace de la mémoire
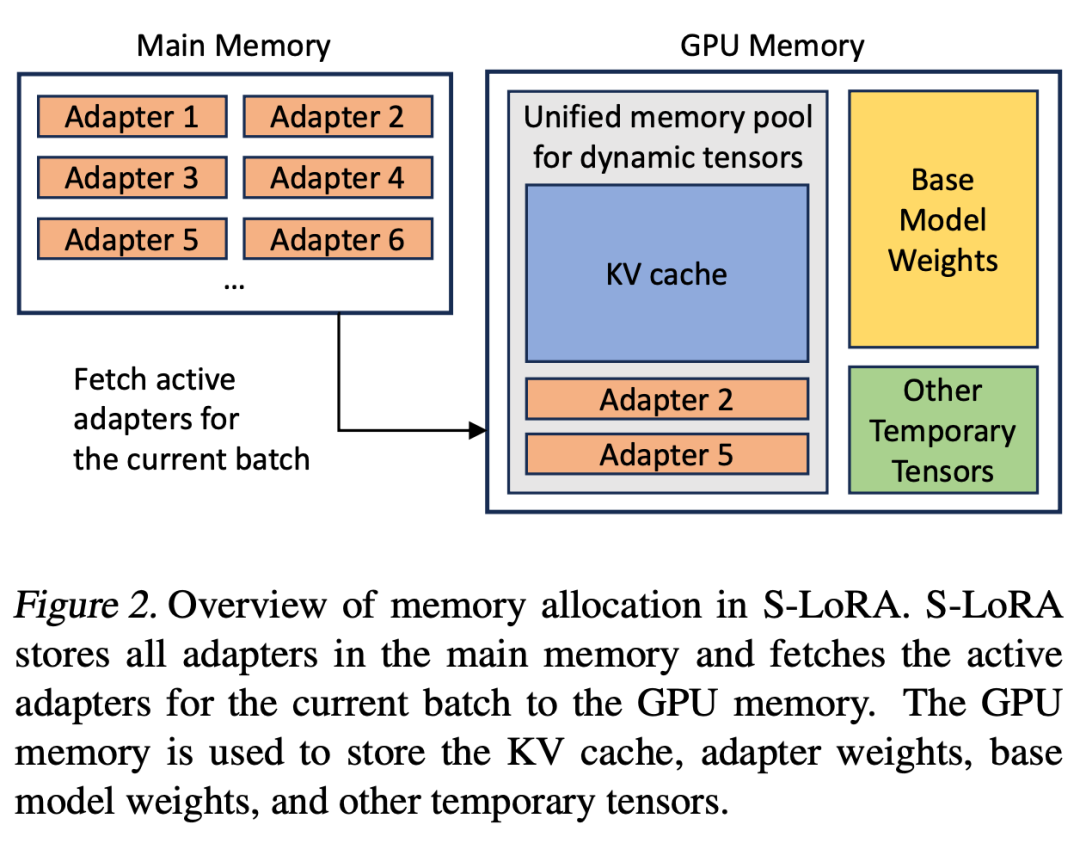
Par rapport à la gestion d'un modèle de base unique, la gestion simultanée de plusieurs cartes adaptateurs LoRA apportera de nouveaux défis en matière de gestion de la mémoire. Pour prendre en charge plusieurs adaptateurs, S-LoRA les stocke dans la mémoire principale et charge dynamiquement les poids d'adaptateur requis pour le lot en cours d'exécution dans la RAM GPU.
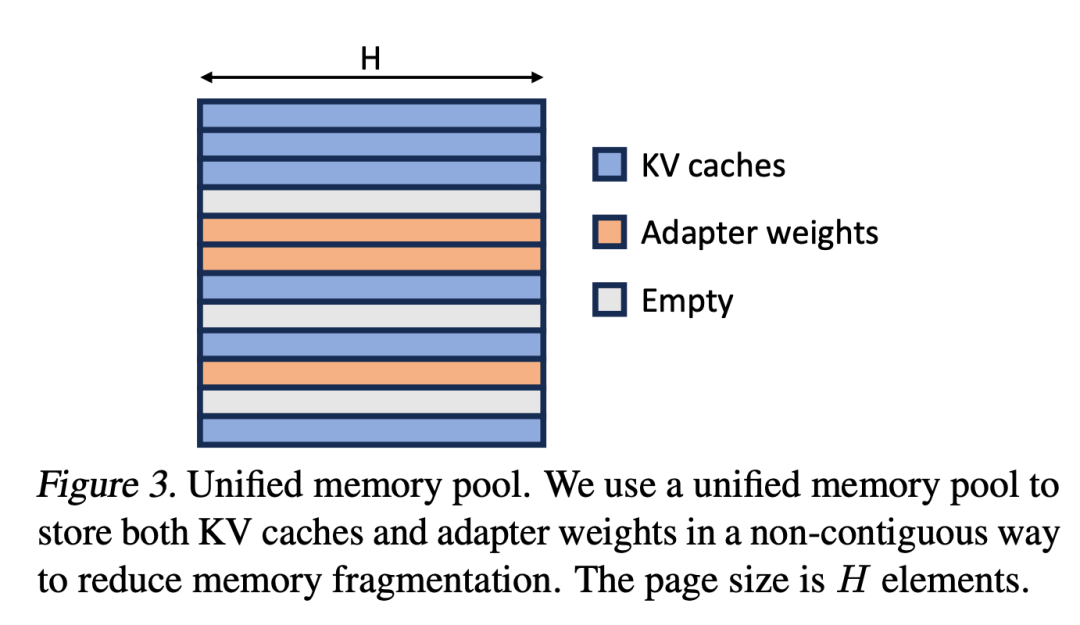
Dans ce processus, il y a deux défis évidents. Le premier est le problème de fragmentation de la mémoire, provoqué par le chargement et le déchargement dynamiques de poids d'adaptateur de différentes tailles. Le second est la surcharge de latence provoquée par le chargement et le déchargement de l’adaptateur. Afin de résoudre efficacement ces problèmes, les chercheurs ont proposé le concept de « pagination unifiée » et ont implémenté le chevauchement des E/S et des calculs en prélevant les poids des adaptateurs
Unified Paging
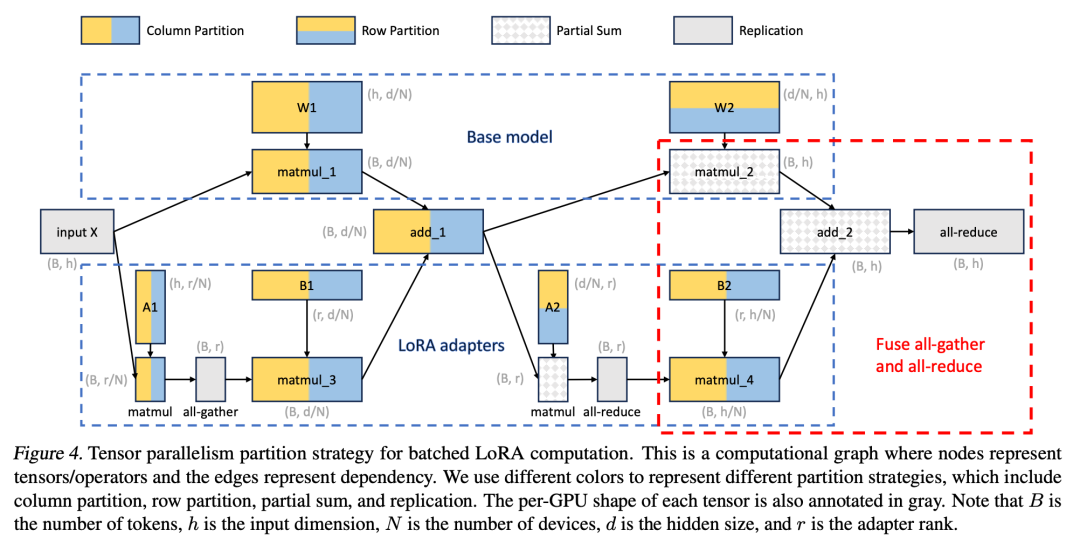
Chercheur Étendre le concept de PagedAttention à la pagination unifiée. La pagination unifiée est utilisée non seulement pour gérer le cache KV, mais également pour gérer les poids des adaptateurs. La pagination unifiée utilise un pool de mémoire unifié pour gérer conjointement le cache KV et les poids des adaptateurs. Pour y parvenir, ils allouent d’abord statiquement un grand tampon au pool de mémoire, qui utilise tout l’espace disponible, à l’exception de l’espace utilisé pour stocker les poids du modèle de base et les tenseurs d’activation temporaires. Le cache KV et les poids de l'adaptateur sont stockés dans le pool de mémoire de manière paginée, et chaque page correspond à un vecteur H. Par conséquent, un tenseur de cache KV avec une longueur de séquence S occupe S pages, tandis qu'un tenseur de poids LoRA de niveau R occupe R pages. La figure 3 montre la disposition du pool de mémoire, dans lequel le cache KV et les poids de l'adaptateur sont stockés de manière entrelacée et non contiguë. Cette approche réduit considérablement la fragmentation et garantit que différents niveaux de poids d'adaptateur peuvent coexister avec le cache KV dynamique de manière structurée et systématique. La stratégie tenseur parallèle est conçue pour prendre en charge l'inférence multi-GPU de grands modèles de transformateurs. Le parallélisme tensoriel est l'approche parallèle la plus largement utilisée car son paradigme à programme unique et données multiples simplifie sa mise en œuvre et son intégration avec les systèmes existants. Le parallélisme tensoriel peut réduire l'utilisation de la mémoire et la latence par GPU lors de la diffusion de modèles volumineux. Dans ce contexte, des adaptateurs LoRA supplémentaires introduisent de nouvelles matrices de poids et multiplications matricielles, qui nécessitent de nouvelles stratégies de partitionnement pour ces ajouts.
Enfin, les chercheurs ont évalué S-LoRA en servant Llama-7B/13B/30B/70B
Pour plus de détails sur la recherche, veuillez vous référer à l'article original.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



