


Cet article évalue les NFNets à grande échelle et remet en question l'idée selon laquelle les ConvNets fonctionnent moins bien que les ViT sur des problèmes à grande échelle
Les premiers succès de l'apprentissage profond peuvent être attribués à l'utilisation de réseaux de neurones convolutifs (ConvNets) développer. Les ConvNets dominent les benchmarks de vision par ordinateur depuis près d’une décennie. Ces dernières années, ils ont toutefois été de plus en plus remplacés par des ViT (Vision Transformers).
Beaucoup de gens pensent que les ConvNets fonctionnent bien sur des ensembles de données de petite ou moyenne taille, mais ne peuvent pas rivaliser avec les ViT sur des ensembles de données de plus grande taille.
Entre-temps, la communauté CV est passée de l'évaluation des performances de réseaux initialisés de manière aléatoire sur des ensembles de données spécifiques (tels que ImageNet) à l'évaluation des performances de réseaux pré-entraînés sur de grands ensembles de données générales collectées à partir du réseau. Cela nous amène à une question importante : les Vision Transformers surpassent-ils les architectures ConvNets pré-entraînées avec des budgets de calcul similaires ?
Dans cet article, des chercheurs de Google DeepMind étudient ce problème. En pré-entraînant plusieurs modèles NFNet sur l'ensemble de données JFT-4B à différentes échelles, ils ont obtenu des performances similaires à celles des ViT sur ImageNet

Adresse du lien papier : https://arxiv.org/pdf/ 2310.16764.pdf
Le Les recherches présentées dans cet article traitent du budget informatique de pré-formation compris entre 0,4 000 et 110 000 heures de calcul de base TPU-v4, et utilisent l'augmentation de la profondeur et de la largeur de la famille de modèles NFNet pour effectuer une série de formations réseau. La recherche a révélé qu'il existe une loi d'échelle log-log entre la perte supportée et le budget informatique
Par exemple, cet article sera basé sur JFT-4B, où l'heure de base du TPU-v4 (heure de base) passe de 0,4 k à étendu à 110k et NFNet est pré-entraîné. Après un réglage fin, le plus grand modèle a atteint une précision de 90,4 % sur ImageNet Top-1, rivalisant avec le modèle ViT pré-entraîné avec le même budget de calcul
On peut dire que cet article, en évaluant les NFNets à grande échelle, Remettre en question l’idée selon laquelle les ConvNets fonctionnent moins bien que les ViT sur des ensembles de données à grande échelle. De plus, avec suffisamment de données et de calculs, les ConvNets restent compétitifs, et la conception et les ressources du modèle sont plus importantes que l'architecture.
Après avoir vu cette recherche, Yann LeCun, lauréat du prix Turing, a déclaré : « Pour une quantité de calcul donnée, ViT et ConvNets sont équivalents sur le plan informatique. Bien que les ViT aient obtenu un succès impressionnant en vision par ordinateur, mais à mon avis, il n'y a aucune preuve solide que Le ViT pré-entraîné est meilleur que les ConvNets pré-entraînés lorsqu'il est évalué de manière équitable. Google DeepMind dit que les ConvNets ne disparaîtront jamais
Jetons un coup d'œil au contenu spécifique du document.
Les NFNets pré-entraînés suivent la loi de mise à l'échelle
Dans le tableau ci-dessous, nous pouvons voir trois modèles sur une gamme de budgets d'époque. Le meilleur taux d'apprentissage observé ( c'est-à-dire celui qui minimise la perte de validation). Les chercheurs ont découvert que pour les budgets d’époque inférieurs, la famille de modèles NFNet présentait tous des taux d’apprentissage optimaux similaires, autour de 1,6. Cependant, le taux d'apprentissage optimal diminue à mesure que le budget d'époque augmente, et il diminue plus rapidement pour les modèles plus grands. Les chercheurs ont déclaré que l'on peut supposer que le taux d'apprentissage optimal diminue lentement et de manière monotone avec l'augmentation de la taille du modèle et du budget d'époque, de sorte que le taux d'apprentissage peut être ajusté efficacement entre les essais

Ce qui doit être réécrit est : il convient de noter que certains des modèles pré-entraînés de la figure 2 n'ont pas fonctionné comme prévu. L'équipe de recherche estime que la raison de cette situation est que si l'exécution de formation est anticipée/redémarrée, le processus de chargement des données ne peut pas garantir que chaque échantillon de formation puisse être échantillonné une fois à chaque époque. Si l'exécution de la formation est redémarrée plusieurs fois, certains échantillons de formation peuvent être sous-échantillonnés
NFNet vs ViT
Les expériences sur ImageNet montrent que NFNet et Vision Transformer affinés fonctionnent de manière comparable
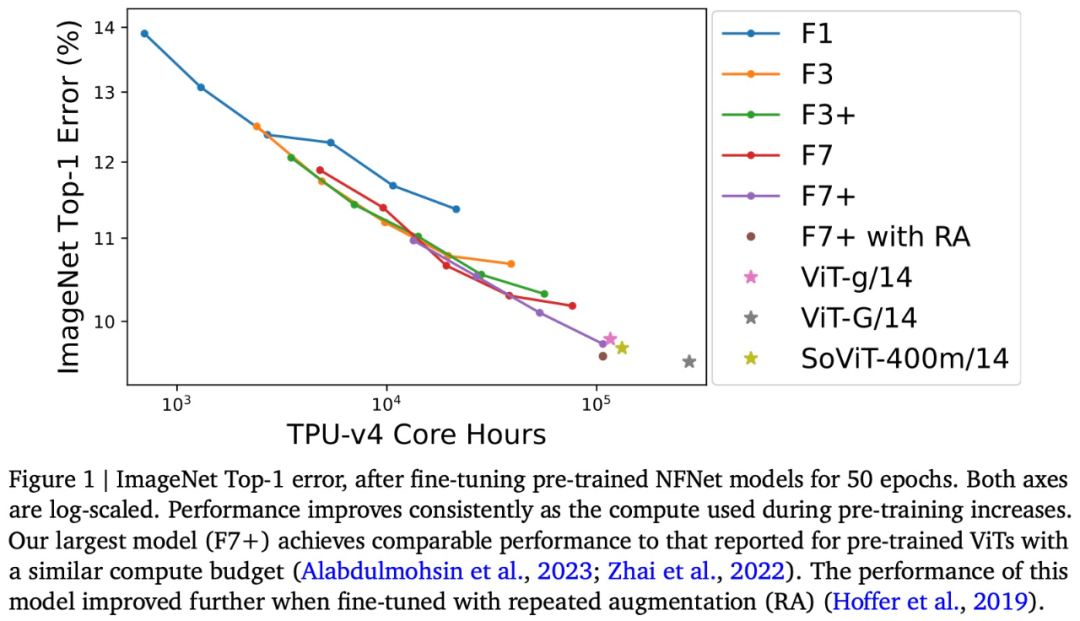
Il a été spécifiquement dit que cette étude a affiné- a réglé le NFNet de pré-formation sur ImageNet et tracé la relation entre le calcul de pré-formation et l'erreur Top-1, comme le montre la figure 1 ci-dessus.
La précision d'ImageNet Top-1 continue de s'améliorer à mesure que le budget augmente. Parmi eux, le modèle pré-entraîné le plus cher est NFNet-F7+, qui est pré-entraîné pendant 8 époques et a une précision de 90,3 % dans ImageNet Top-1. Le pré-entraînement et le réglage précis nécessitent environ 110 000 heures de base TPU-v4 et 1,6 000 heures de base TPU-v4. De plus, si des techniques d'amélioration répétitives supplémentaires sont introduites lors du réglage fin, une précision Top-1 de 90,4 % peut être obtenue. NFNet bénéficie grandement d'une pré-formation à grande échelle
Bien qu'il existe des différences évidentes entre les deux architectures modèles NFNet et ViT, les performances de NFNet pré-entraîné et de ViT pré-entraîné sont comparables. Par exemple, après avoir pré-entraîné JFT-3B avec 210 000 heures de base TPU-v3, ViT-g/14 a atteint une précision Top-1 de 90,2 % sur ImageNet tout en exécutant plus de 500 000 TPU-v3 sur JFT-3B après les heures de base ; de pré-entraînement, ViT-G/14 a atteint une précision Top-1 de 90,45 %
Cet article évalue la vitesse de pré-entraînement de ces modèles sur TPU-v4 et estime que ViT-g/14 nécessite 120 000 cœurs TPU-v4 heures pour se pré-entraîner, tandis que ViTG/14 nécessitera 280 000 heures de base TPU-v4 et SoViT-400m/14 nécessitera 130 000 heures de base TPU-v4. Cet article utilise ces estimations pour comparer l'efficacité de pré-formation de ViT et de NFNet dans la figure 1. L'étude a noté que NFNet est optimisé pour TPU-v4 et fonctionne mal lorsqu'il est évalué sur d'autres appareils.
Enfin, cet article note que les points de contrôle pré-entraînés obtiennent la perte de validation la plus faible sur JFT-4B, mais n'atteignent pas toujours la précision Top-1 la plus élevée sur ImageNet après un réglage fin. En particulier, cet article révèle que dans le cadre d'un budget de calcul fixe avant la formation, le mécanisme de réglage fin a tendance à sélectionner un modèle légèrement plus grand et un budget d'époque légèrement plus petit. Intuitivement, les modèles plus grands ont une plus grande capacité et sont donc mieux à même de s’adapter aux nouvelles tâches. Dans certains cas, un taux d'apprentissage légèrement plus élevé (lors de la pré-entraînement) peut également conduire à de meilleures performances après un réglage fin
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Prix du marché d'Ethereum aujourd'hui
Prix du marché d'Ethereum aujourd'hui Méthode d'ouverture de l'autorisation de portée
Méthode d'ouverture de l'autorisation de portée Pourquoi n'y a-t-il aucun signal sur le moniteur après avoir allumé l'ordinateur ?
Pourquoi n'y a-t-il aucun signal sur le moniteur après avoir allumé l'ordinateur ? Le cœur du logiciel du système informatique
Le cœur du logiciel du système informatique A quoi sert l'image Docker ?
A quoi sert l'image Docker ? Que fait Xiaohongshu ?
Que fait Xiaohongshu ? Quel est le nom de l'application de télécommunications ?
Quel est le nom de l'application de télécommunications ? La différence entre fprintf et printf
La différence entre fprintf et printf




















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



