


Récemment, GPT-4, qui a inspiré le mathématicien Terence Tao, a commencé à apprendre aux robots à tourner les stylos dans les chats

Le projet s'appelle Agent Eureka, qui a été développé par NVIDIA, l'Université de Pennsylvanie, le California Institute of Technologie et Université du Texas à Austin Développé conjointement par les écoles secondaires. Leurs recherches combinent la puissance de la structure GPT-4 avec les avantages de l’apprentissage par renforcement, permettant à Eureka de concevoir des fonctions de récompense exquises.
Les capacités de programmation de GPT-4 confèrent à Eureka de puissantes compétences en matière de conception de fonctions de récompense. Cela signifie que dans la plupart des tâches, les systèmes de récompense d’Eureka sont encore meilleurs que ceux des experts humains. Cela lui permet d'accomplir certaines tâches difficiles à accomplir pour les humains, notamment tourner des stylos, ouvrir des tiroirs, plaquer des noix et des tâches encore plus complexes, comme lancer et attraper une balle, faire fonctionner des ciseaux, etc.
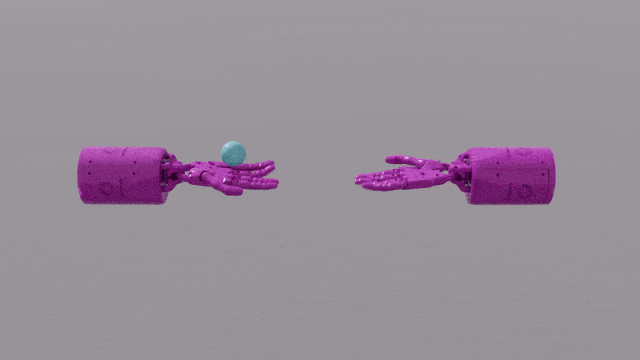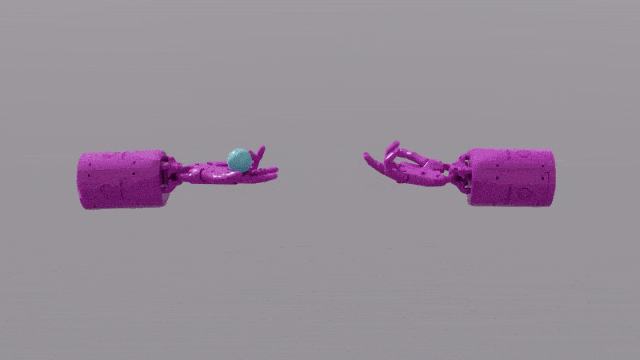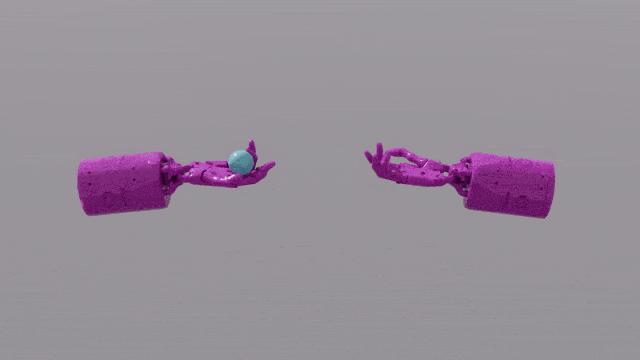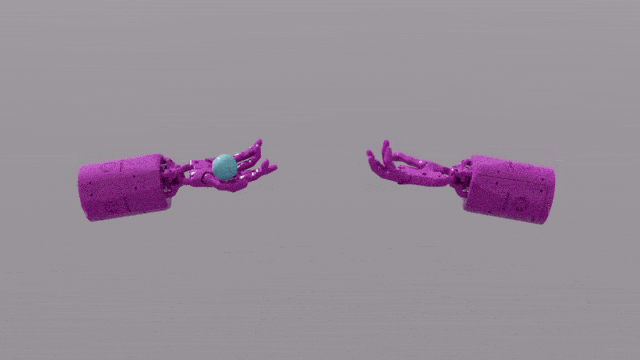 Photos
Photos
 Photos
Photos
Bien que celles-ci soient actuellement réalisées dans un environnement simulé, c'est déjà très puissant.
Le projet a été open source, et l'adresse du projet et l'adresse du papier ont été placées à la fin de l'article
Un bref résumé des points essentiels du document.
L'article explore comment utiliser les grands modèles de langage (LLM) pour concevoir et optimiser les fonctions de récompense dans l'apprentissage automatique. Il s’agit d’un sujet important car concevoir une bonne fonction de récompense peut grandement améliorer les performances des modèles d’apprentissage automatique, mais concevoir une telle fonction est très difficile.
Des chercheurs ont proposé un nouvel algorithme appelé EUREKA. EUREKA adopte LLM pour générer et améliorer les fonctions de récompense. Lors des tests, EUREKA a atteint des performances de niveau humain dans 29 environnements d'apprentissage par renforcement différents et a surpassé les fonctions de récompense conçues par des experts humains dans 83 % des tâches.
EUREKA a résolu avec succès certains problèmes qui étaient auparavant impossibles à concevoir manuellement des fonctions de récompense. Résout des tâches opérationnelles complexes, telles que comme simulant le fonctionnement de "Shadow Hand" pour tourner rapidement un stylo
De plus, EUREKA propose une toute nouvelle méthode qui peut générer une fonction de récompense plus efficace et plus conforme aux attentes humaines basées sur les commentaires humains
EUREKA fonctionne en trois étapes principales :
Environnement comme contexte : EUREKA utilise le code source de l'environnement comme contexte pour générer des fonctions de récompense exécutables
2 Recherche évolutive : EUREKA propose en permanence une recherche évolutive et une amélioration de la fonction de récompense
3. : EUREKA génère des résumés textuels de la qualité des récompenses sur la base des statistiques issues de la formation politique, améliorant ainsi automatiquement et de manière ciblée la fonction de récompense. 3. Réflexion sur les récompenses : EUREKA génère des résumés textuels de la qualité des récompenses basés sur les statistiques de la formation politique pour améliorer automatiquement et de manière ciblée les fonctions de récompense.
Cette recherche peut avoir un impact profond sur le domaine de l'apprentissage par renforcement et de la conception des fonctions de récompense, car elle est nouvelle et efficace. La méthode est fournie pour générer et améliorer automatiquement les fonctions de récompense, et les performances de cette méthode dépassent celles des experts humains dans de nombreux cas.
Adresse du projet ://m.sbmmt.com/link/e6b738eca0e6792ba8a9cbcba6c1881d
Lien papier ://m.sbmmt.com/link/ce128c3e8f0c0ae4b3e843dc7cbab0f7
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



