


Cet article est réimprimé avec l'autorisation du compte public Heart of Autonomous Driving. Veuillez contacter la source originale pour la réimpression
Bien que cet article. a 21 ans, mais de nombreux nouveaux articles l'utilisent comme base de comparaison, il est donc également nécessaire de comprendre sa méthode
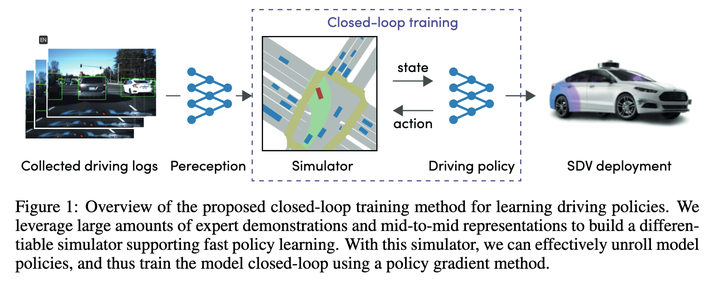
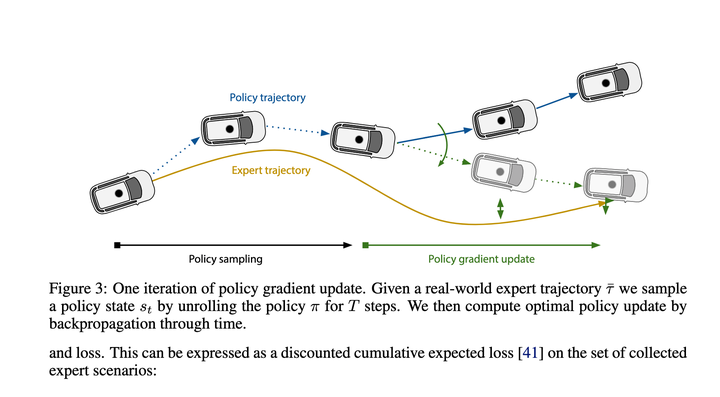
Après un examen approximatif, il utilise principalement les gradients de politique pour apprendre la fonction de cartographie de Etat->Action récente. Avec cette cartographie, la fonction peut déduire l'intégralité de la trajectoire d'exécution étape par étape. La perte finale est de rendre la trajectoire donnée par cette déduction aussi proche que possible de la trajectoire experte.
L'effet devrait être plutôt bon à ce moment-là, il peut donc devenir la base de référence pour de nouveaux algorithmes.
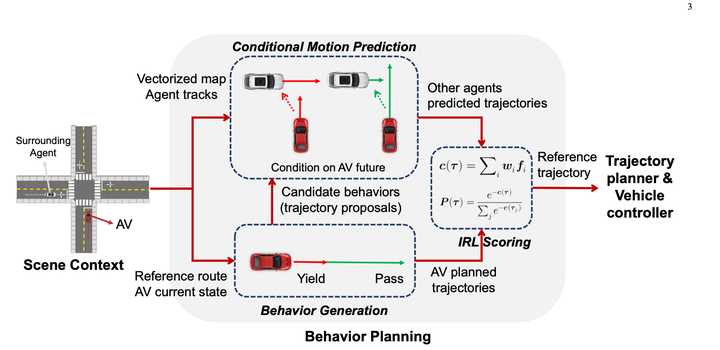
Utilisez d'abord des règles pour énumérer une variété de comportements et générer 10 à 30 trajectoires. (Résultats de prédiction non utilisés)
Utilisez la prédiction conditionnelle pour calculer les résultats de prédiction pour la trajectoire candidate de chaque véhicule hôte, puis utilisez IRL pour noter la trajectoire candidate.
Le modèle de prédiction conjointe conditionnelle ressemble à ceci :
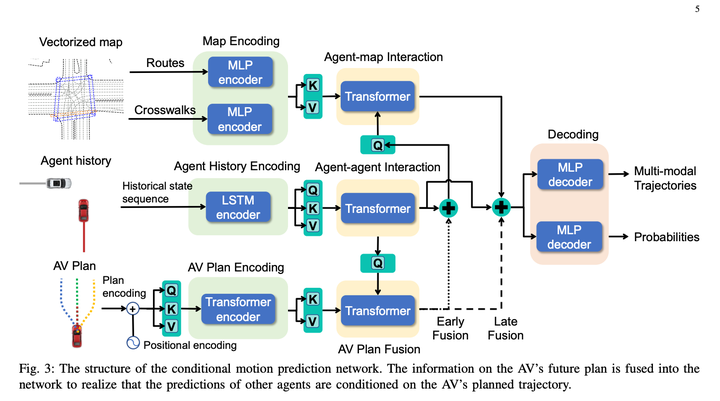
Ce qui est fondamentalement génial avec cette méthode, c'est qu'elle utilise la prédiction conjointe conditionnelle pour compléter des prédictions interactives, donnant à l'algorithme une certaine capacité de jeu.
Mais je pense personnellement que le défaut de l'algorithme est que seulement 10 à 30 trajectoires étaient générées auparavant, et les prédictions n'étaient pas prises en compte lors de la génération des trajectoires, et au final, une de ces trajectoires sera directement sélectionnée comme résultat final après IRL notation, ce qui facilite la tâche pour 10 à 30 situations qui n'étaient pas idéales après avoir pris en compte les prédictions. Cela équivaut à choisir un général parmi les infirmes, et ceux choisis sont toujours des infirmes. Basé sur cette solution, ce sera un bon moyen de résoudre le problème de la qualité de la génération d'échantillons à l'avant. 3. Solution NVIDIA : 2023.02 Planification de politiques structurées en arborescence avec des modèles de comportement appris
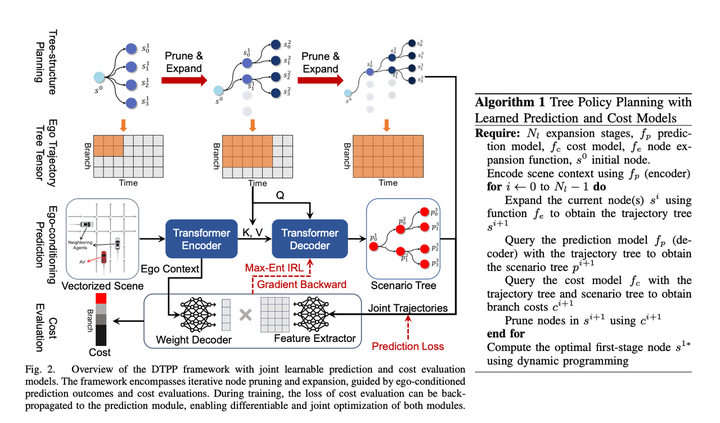
4. Dernier plan conjoint de l'Université technologique de Nanyang et de NVIDIA en octobre 2023 : DTPP : Prédiction conditionnelle conjointe différenciable et évaluation des coûts pour la planification des politiques d'arbres dans la conduite autonome
2. Il est différentiable et peut renvoyer tout le gradient afin que les prédictions puissent être entraînées avec IRL. C'est également une condition nécessaire pour pouvoir construire une conduite autonome de bout en bout. Troisièmement, la planification des politiques arborescentes peut avoir certaines capacités de déduction interactives. Après l'avoir lu attentivement, j'ai trouvé cet article très informatif et la méthode très instructive. intelligent.
 1. Le module de prédiction conditionnelle saisit une trajectoire historique du véhicule principal + une trajectoire rapide + une trajectoire historique du véhicule obstacle, et donne la trajectoire prédite du véhicule principal approchant de la trajectoire rapide et la trajectoire prédite du véhicule obstacle qui est cohérente. avec le comportement du véhicule principal.
1. Le module de prédiction conditionnelle saisit une trajectoire historique du véhicule principal + une trajectoire rapide + une trajectoire historique du véhicule obstacle, et donne la trajectoire prédite du véhicule principal approchant de la trajectoire rapide et la trajectoire prédite du véhicule obstacle qui est cohérente. avec le comportement du véhicule principal.
3. Module de recherche de politiques arborescentes, utilisé pour générer un ensemble de trajectoires candidates
L'algorithme de recherche arborescente est utilisé pour explorer la solution réalisable du véhicule principal. Chaque étape du processus d'exploration prend la trajectoire explorée comme entrée, utilise l'algorithme de prédiction conditionnelle pour générer les trajectoires prédites du véhicule principal et du véhicule obstacle, et appelle le module de notation pour évaluer l'excellence de la trajectoire est médiocre, affectant ainsi la direction de la prochaine recherche de nœuds d'expansion. Grâce à cette méthode, vous pouvez générer certaines trajectoires principales du véhicule qui sont différentes des autres solutions et prendre en compte l'interaction avec le véhicule obstacle lors de la génération des trajectoires.
L'IRL traditionnel crée manuellement de nombreuses fonctionnalités, telles qu'un ensemble de fonctionnalités avant et arrière Diverses caractéristiques des obstacles dans la dimension temporelle de la trajectoire (telles que s, l et ttc relatifs. Dans cet article, afin de rendre le modèle différenciable, le contexte ego MLP de prédiction est directement utilisé pour générer un tableau de poids (taille = 1 *). C), représente implicitement les informations environnementales autour du véhicule hôte, puis utilise MLP pour convertir directement la trajectoire du véhicule hôte + les résultats de prédiction multimodaux correspondants en un tableau de fonctionnalités (taille = C * N, N fait référence au nombre de trajectoires candidates ) , puis les deux matrices sont multipliées pour obtenir le score final de la trajectoire. Ensuite, IRL a laissé les experts marquer les points les plus élevés. Personnellement, je pense que cela peut être dû à l'efficacité du calcul, en rendant le décodeur aussi simple que possible, mais il y a quand même une certaine perte des informations principales du véhicule. Si vous ne faites pas attention à l'efficacité du calcul, vous pouvez utiliser des réseaux plus complexes pour le faire. connecter le contexte de l'ego et les trajectoires prédites, et le niveau d'effet devrait être meilleur ? Ou si vous abandonnez la différentiabilité, vous pouvez toujours envisager d'ajouter des fonctionnalités définies manuellement, ce qui devrait également améliorer l'effet du modèle.
En termes de temps, cette solution utilise une méthode d'un ré-encodage + plusieurs décodages légers, ce qui réduit avec succès les délais de calcul. L'article souligne que le délai peut être compressé à 98 millisecondes
Il appartient aux rangs SOTA parmi les planificateurs basés sur l'apprentissage, et l'effet en boucle fermée est proche du schéma PDM basé sur des règles n°1 de nuplan mentionné dans l'article précédent.
En y regardant, je pense que ce paradigme est une bonne idée. Vous pouvez trouver des moyens d'ajuster le processus spécifique au milieu :

Le contenu qui doit être réécrit est : Lien original : https://mp.weixin. qq.com/s/ZJtMU3zGciot1g5BoCe9Ow
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Quelles compétences sont nécessaires pour travailler dans l'industrie PHP ?
Quelles compétences sont nécessaires pour travailler dans l'industrie PHP ?
 Structure de données en langage C
Structure de données en langage C
 À quelle entreprise appartient le système Android ?
À quelle entreprise appartient le système Android ?
 Quel logiciel est Unity ?
Quel logiciel est Unity ?
 Comment publier du texte dans WeChat Moments
Comment publier du texte dans WeChat Moments
 Méthode d'enregistrement du compte Google
Méthode d'enregistrement du compte Google
 Diagramme de topologie de réseau
Diagramme de topologie de réseau
 introduction à la commande route add
introduction à la commande route add





















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



