


Découverte surprenante : Le grand modèle présente de sérieux défauts dans la déduction des connaissances.
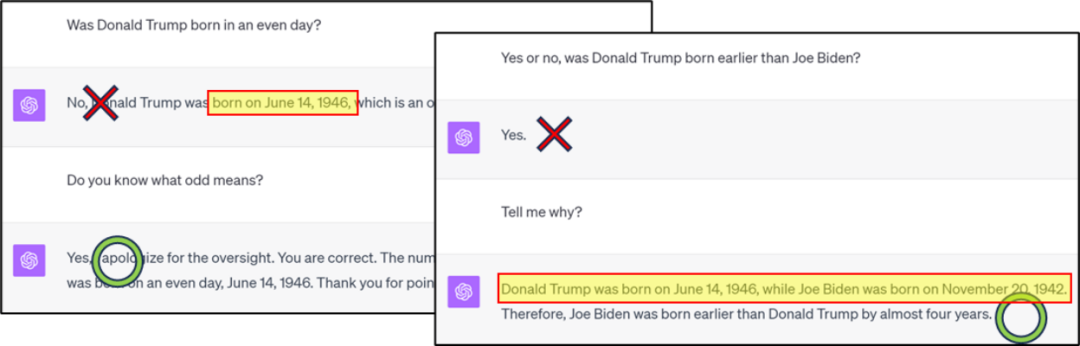
Le contenu qui doit être réécrit est : Figure 1 : GPT4 contient des erreurs dans la classification/comparaison des connaissances, mais la bonne réponse peut être obtenue grâce à la chaîne de réflexion
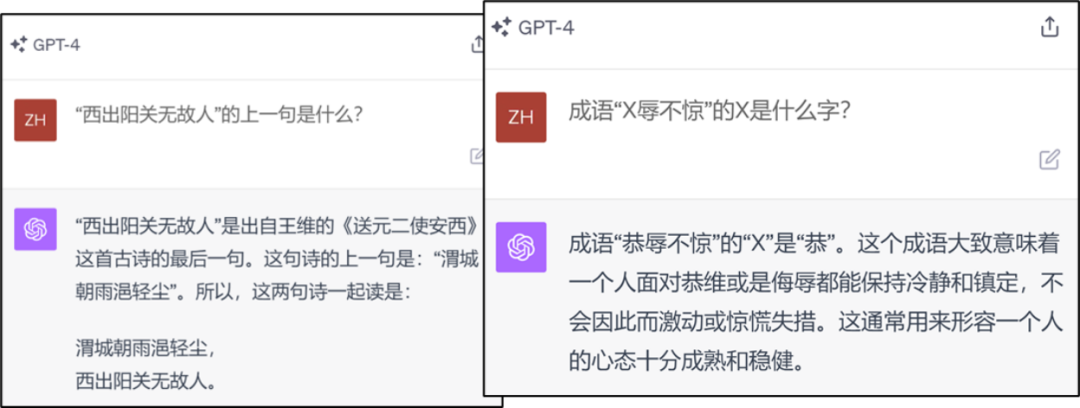
Le le contenu qui doit être réécrit est Oui : Figure 2 : Exemple d'erreur de recherche inversée de connaissances GPT4

 Veuillez cliquer sur le lien suivant pour consulter l'article : https://arxiv.org/abs/2309.14402
Veuillez cliquer sur le lien suivant pour consulter l'article : https://arxiv.org/abs/2309.14402Permettez-moi d'abord de poser une question. Les problèmes tels que la figure 1/2/3 sont la mémoire des gens par GPT4. les anniversaires ne sont pas assez précis (le taux de compression n'est pas suffisant, la perte d'entraînement n'est pas assez faible), ou la compréhension de la parité n'a-t-elle pas été approfondie grâce à un réglage fin ? Est-il possible d'affiner GPT4 afin qu'il puisse combiner les connaissances existantes au sein du modèle pour générer de nouvelles connaissances telles que la « parité d'anniversaire » et répondre directement aux questions connexes sans s'appuyer sur CoT ? Comme nous ne connaissons pas l'ensemble de données d'entraînement de GPT4, un réglage fin n'est pas possible. Par conséquent, l'auteur propose d'utiliser des ensembles de formation contrôlables pour étudier plus en profondeur la capacité de « déduction de connaissances » des modèles linguistiques. T Figure 4 : Modèles de pré-formation tels que GPT4, en raison des données Internet incontrôlables, il est difficile de déterminer si la situation B/C/D se produit « : Stockage et extraction des connaissances », l'auteur a construit un ensemble de données contenant. 100 000 biographies. Chaque biographie comprend le nom de la personne ainsi que six attributs : date de naissance, lieu de naissance, spécialité universitaire, nom de l'université, lieu de travail et lieu de travail. Par exemple :
Anya Briar Forger
 Princeton, NJ.
Princeton, NJ.Communications Elle a acquis une expérience professionnelle à Menlo Park, CA Elle a développé sa carrière chez Meta Platforms
. est venue au monde le2 octobre 1996
Elle a suivi des cours avancés auMIT.‖L'auteur a veillé à la diversité des entrées biographiques pour aider le modèle à mieux accéder aux connaissances. Après la pré-formation, le modèle peut répondre avec précision aux questions d'extraction de connaissances grâce à des réglages fins, tels que "Quand est l'anniversaire d'Anya ?" modèle apprendre déduction de connaissances Questions telles que la classification/comparaison/addition et soustraction de connaissances. L'article révèle que les modèles de langage naturel ont des capacités très limitées en matière de déduction des connaissances et qu'il est difficile de générer de nouvelles connaissances par un réglage fin, même s'il ne s'agit que de simples transformations/combinaisons des connaissances déjà maîtrisées par le modèle. 
Figure 5 : Si CoT n'est pas utilisé lors du réglage fin, permettre au modèle de classer/comparer/soustraire des connaissances nécessitera un grand nombre d'échantillons ou le taux de précision sera extrêmement faible - 100 majors ont été utilisées dans l'expérience
Par exemple Figure 5. L'auteur a constaté que bien que le modèle puisse répondre avec précision à l'anniversaire de tout le monde après le pré-entraînement (le taux de précision est proche de 100%), il doit être affiné pour répondre "Est-ce le mois de naissance de xxx un nombre pair ?" et atteint une précision de 75 % - n'oubliez pas que la supposition aveugle a un taux de précision de 50 % - nécessite au moins 10 000 échantillons de réglage fin. En comparaison, si le modèle peut compléter correctement la combinaison de connaissances « anniversaire » et « parité », alors selon la théorie traditionnelle de l'apprentissage automatique, le modèle n'a besoin que d'apprendre à classer 12 mois, et généralement environ 100 échantillons suffisent !
De même, même une fois le modèle pré-entraîné, il peut répondre avec précision à la majeure de chacun (un total de 100 majeures différentes), mais même en utilisant 50 000 échantillons de réglage fin, laissez le modèle comparer "Lequel est le meilleur, la majeure d'Anya ou " ", le taux de précision n'est que de 53,9%, ce qui équivaut presque à deviner. Cependant, lorsque nous utilisons le modèle de réglage fin CoT pour apprendre la phrase "Le mois de naissance d'Anya est octobre, c'est donc un nombre pair", le modèle détermine le mois de naissance sur l'ensemble de test La précision de la parité mensuelle s'est considérablement améliorée (voir la colonne « CoT pour les tests » dans la figure 5)
Les auteurs ont également essayé de mélanger les réponses CoT et non-CoT dans les données d'entraînement de réglage fin , et a constaté que le modèle fonctionnait mieux sur l'ensemble de test lorsqu'il n'utilisait pas CoT. Le taux de précision est encore très faible (voir la colonne « test sans CoT » dans la figure 5). Cela montre que même si suffisamment de données de réglage fin du CoT sont ajoutées, le modèle ne peut toujours pas apprendre à « penser dans la tête » et rapporter directement la réponse
Ces résultats montrent que
Pour les modèles de langage, il est extrêmement difficile d'effectuer des connaissances simples opérations ! Le modèle doit d'abord noter les points de connaissance puis effectuer des calculs. Il ne peut pas être utilisé directement dans le cerveau comme un être humain, même après un réglage suffisamment fin, cela n'aidera pas.Défis de la recherche inversée de connaissances
La recherche a également révélé que les modèles de langage naturel ne peuvent pas appliquer les connaissances acquises via la recherche inversée. Bien qu'il puisse répondre à toutes les informations sur une personne, il ne peut pas déterminer le nom de la personne sur la base de ces informations
Les auteurs ont expérimenté GPT3.5/4 et ont constaté qu'ils obtenaient de mauvais résultats dans l'extraction inverse des connaissances (voir Figure 6). Cependant, comme nous ne pouvons pas déterminer l'ensemble de données d'entraînement de GPT3.5/4, cela ne prouve pas que tous les modèles de langage ont ce problème

Figure 6 : Comparaison de la recherche de connaissances avant/arrière dans GPT3.5/ 4 . Notre travail "Reverse Curse" précédemment rapporté (arxiv 2309.12288) a également observé ce phénomène sur de grands modèles existantsL'auteur a utilisé l'ensemble de données biographiques susmentionnées pour mener une étude plus approfondie des tests contrôlés des capacités de recherche de connaissances inversées du modèle. Puisque les noms de toutes les biographies se trouvent au début du paragraphe, l'auteur a conçu 10 questions d'extraction inversée d'informations, telles que :
Connaissez-vous le nom de la personne née à Princeton, New Jersey le 2 octobre 1996 ?
"Veuillez me dire le nom d'une personne qui a étudié les communications au MIT, est née le 2 octobre 1996 à Princeton, dans le New Jersey, et travaille chez Meta Platforms à Menlo Park, en Californie ?"

Besoin de continuer Le contenu réécrit est : Figure 7 : Expérience contrôlée sur l'ensemble de données biographiques de célébritésL'auteur a vérifié que bien que le modèle ait atteint une compression des connaissances sans perte et une amélioration suffisante des connaissances, et qu'il ait pu extraire ces connaissances presque à 100 % correctement, dans After fine -tuning, le modèle est toujours incapable d'effectuer une recherche inverse des connaissances et la précision est presque nulle (voir Figure 7). Cependant, une fois que les connaissances inverses apparaissent directement dans l'ensemble de pré-formation, la précision de la recherche inverse monte immédiatement en flèche.
Pour résumer, ce n'est que lorsque la connaissance inverse est directement incluse dans les données de pré-entraînement que le modèle peut répondre à la question inverse grâce à un réglage fin - mais c'est en fait de la triche, car si la connaissance a été inversée, elle ne le fera pas. recherche inversée de connaissances »à nouveau. Si l'ensemble de pré-formation ne contient que des connaissances avancées, le modèle ne peut pas maîtriser la capacité de répondre aux questions à l'envers grâce à un réglage fin. Par conséquent, utiliser des modèles linguistiques pour l’indexation des connaissances (base de données de connaissances) semble actuellement impossible.
De plus, certaines personnes peuvent penser que la « recherche inversée de connaissances » ci-dessus échoue parce que les modèles linguistiques autorégressifs (tels que GPT) sont à sens unique. Cependant, en réalité, les modèles de langage bidirectionnels (tels que BERT) fonctionnent moins bien en matière d’extraction de connaissances et échouent même en matière d’extraction vers l’avant. Pour les lecteurs intéressés, vous pouvez vous référer aux informations détaillées dans le journal
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment définir la police en CSS
Comment définir la police en CSS
 Le dernier classement des dix principales bourses du cercle des devises
Le dernier classement des dix principales bourses du cercle des devises
 Combien de types d'interfaces USB existe-t-il ?
Combien de types d'interfaces USB existe-t-il ?
 Objectif principal du système de fichiers
Objectif principal du système de fichiers
 Windows vérifie l'état d'occupation des ports
Windows vérifie l'état d'occupation des ports
 Est-il légal d'acheter et de vendre du Bitcoin sur Huobi.com ?
Est-il légal d'acheter et de vendre du Bitcoin sur Huobi.com ?
 Liste des touches de raccourci Mac
Liste des touches de raccourci Mac
 Qu'est-ce qu'un tableau vide en php
Qu'est-ce qu'un tableau vide en php








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



