


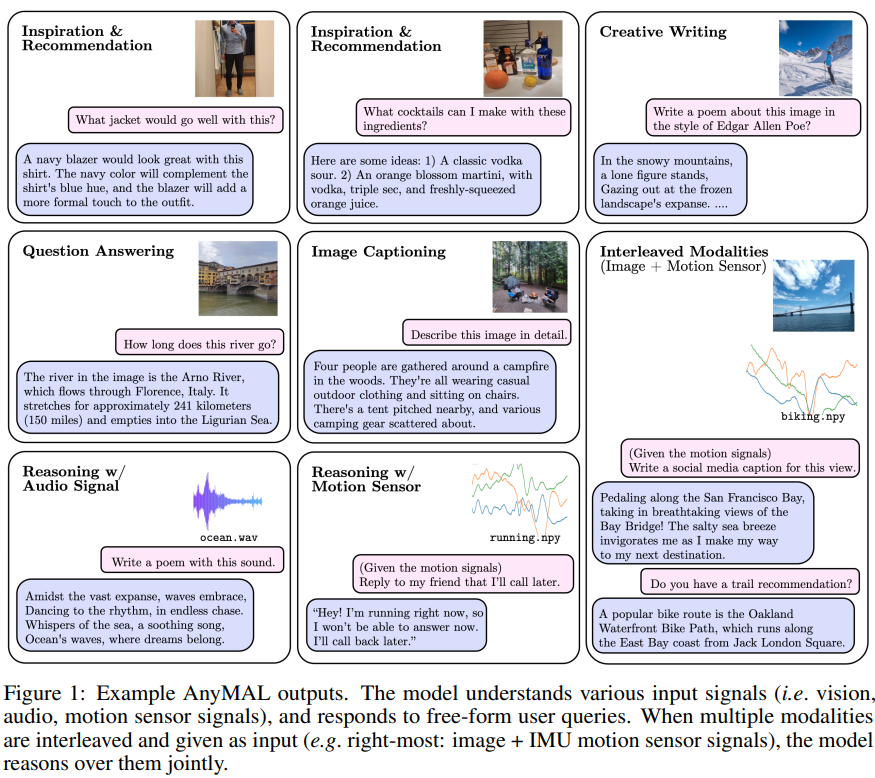
Actualisation des meilleures performances zéro tir de l'industrie dans plusieurs tests de référence.
Un modèle unifié qui peut comprendre différents contenus d'entrée modale (texte, image, vidéo, audio, données du capteur de mouvement IMU) et générer des réponses textuelles. La technologie est basée sur Llama 2 et vient de Meta.
Hier, la recherche sur le grand modèle multimodal AnyMAL a attiré l'attention de la communauté des chercheurs en IA.
Les grands modèles linguistiques (LLM) sont connus pour leur taille et leur complexité énormes, qui améliorent considérablement la capacité des machines à comprendre et à exprimer le langage humain. Les progrès des LLM ont permis des avancées significatives dans le domaine du langage visuel, comblant le fossé entre les encodeurs d'images et les LLM, en combinant leurs capacités d'inférence. Les précédentes recherches LLM multimodales se sont concentrées sur des modèles combinant du texte avec une autre modalité, tels que des modèles de texte et d'image, ou sur des modèles de langage propriétaires qui ne sont pas open source.
S'il existe une meilleure façon d'obtenir une fonctionnalité multimodale et d'intégrer diverses modalités dans LLM, cela nous apportera-t-il une expérience différente ?
Adresse papier : https://huggingface. co/papers/2309.16058
Selon la description, les principales contributions de cette recherche sont les suivantes :

Présentation de la méthode
Le contenu de l'alignement modal pré-entraîné doit être réécrit 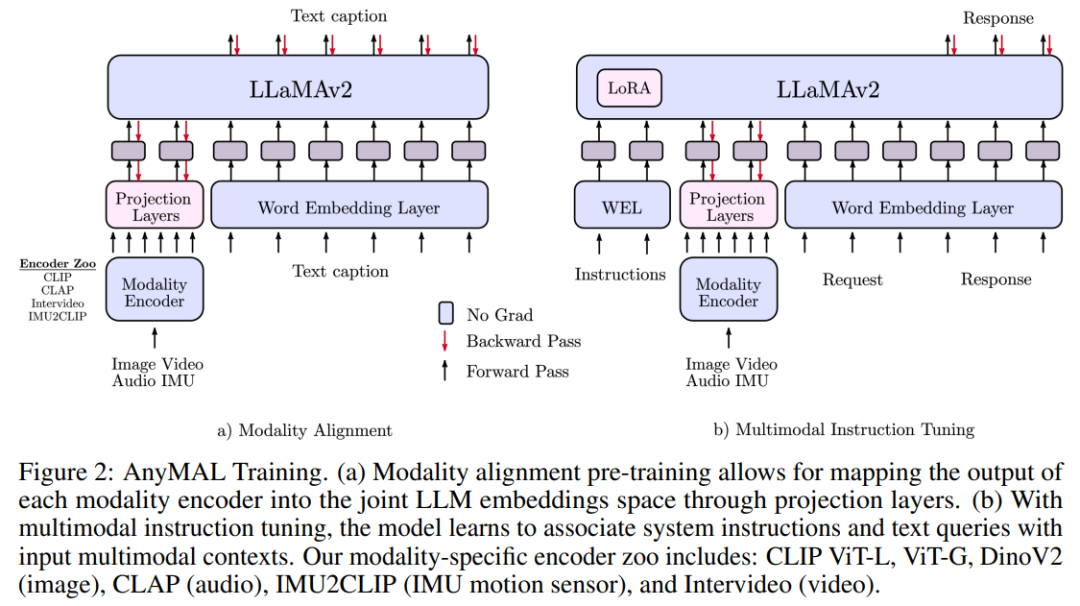 en utilisant des données multimodales appariées, y compris un signal modal spécifique et un récit textuel), cette étude LLM pré-entraîné pour atteindre des capacités de compréhension multimodale, comme le montre la figure 2. Plus précisément, nous formons un adaptateur léger pour chaque modalité qui projette le signal d'entrée dans l'espace d'intégration de jeton de texte d'un LLM spécifique. De cette façon, l'espace d'intégration de jetons de texte de LLM devient un espace d'intégration de jetons commun, où les jetons peuvent représenter du texte ou d'autres modalités
en utilisant des données multimodales appariées, y compris un signal modal spécifique et un récit textuel), cette étude LLM pré-entraîné pour atteindre des capacités de compréhension multimodale, comme le montre la figure 2. Plus précisément, nous formons un adaptateur léger pour chaque modalité qui projette le signal d'entrée dans l'espace d'intégration de jeton de texte d'un LLM spécifique. De cette façon, l'espace d'intégration de jetons de texte de LLM devient un espace d'intégration de jetons commun, où les jetons peuvent représenter du texte ou d'autres modalités
Pour les grands ensembles de données, la mise à l'échelle du pré-entraînement vers un modèle de paramètres de 70 B nécessite beaucoup de ressources, nécessitant souvent l'utilisation de wrappers FSDP sur plusieurs GPU. est fragmenté. Pour faire évoluer efficacement la formation, nous mettons en œuvre une stratégie de quantification (4 bits et 8 bits) dans un cadre multimodal, où la partie LLM du modèle est figée et seul le tokenizer modal peut être entraîné. Cette approche réduit les besoins en mémoire d'un ordre de grandeur. Par conséquent, 70B AnyMAL peut effectuer une formation sur un seul GPU VRAM de 80 Go avec une taille de lot de 4. Par rapport à FSDP, la méthode de quantification proposée dans cet article n'utilise que la moitié des ressources GPU, mais atteint le même débit
Utiliser des ensembles de données d'instructions multimodales pour un réglage fin signifie utiliser des ensembles de données d'instructions multimodales pour un réglage fin
Afin d'améliorer encore la capacité du modèle à suivre des instructions pour différentes modalités de saisie, nous étudions le utilisation d'ensembles de données d'instructions multimodales Des ajustements supplémentaires ont été effectués sur l'ensemble de données de réglage d'instructions (MM-IT) de pointe. Plus précisément, nous concaténons l'entrée sous la forme [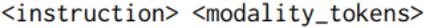 ] afin que la cible de réponse soit basée à la fois sur l'instruction textuelle et sur l'entrée modale. La recherche est menée sur les deux situations suivantes : (1) entraîner la couche de projection sans modifier les paramètres LLM ou (2) utiliser une adaptation de bas niveau (Low-Rank Adaptation) pour ajuster davantage le comportement du LM ; L’étude utilise à la fois des ensembles de données collectées manuellement et des données synthétiques.
] afin que la cible de réponse soit basée à la fois sur l'instruction textuelle et sur l'entrée modale. La recherche est menée sur les deux situations suivantes : (1) entraîner la couche de projection sans modifier les paramètres LLM ou (2) utiliser une adaptation de bas niveau (Low-Rank Adaptation) pour ajuster davantage le comportement du LM ; L’étude utilise à la fois des ensembles de données collectées manuellement et des données synthétiques.
Expériences et résultats
La génération de légendes d'images est une technologie d'intelligence artificielle utilisée pour générer automatiquement les légendes correspondantes pour les images. Cette technologie combine des méthodes de vision par ordinateur et de traitement du langage naturel pour générer des légendes descriptives liées à l'image en analysant le contenu et les caractéristiques de l'image, ainsi qu'en comprenant la sémantique et la syntaxe. La génération de légendes d'images a de nombreuses applications dans de nombreux domaines, notamment la recherche d'images, l'annotation d'images, la récupération d'images, etc. En générant automatiquement des titres, la compréhensibilité des images et la précision des moteurs de recherche peuvent être améliorées, offrant aux utilisateurs une meilleure expérience de récupération d'images et de navigation
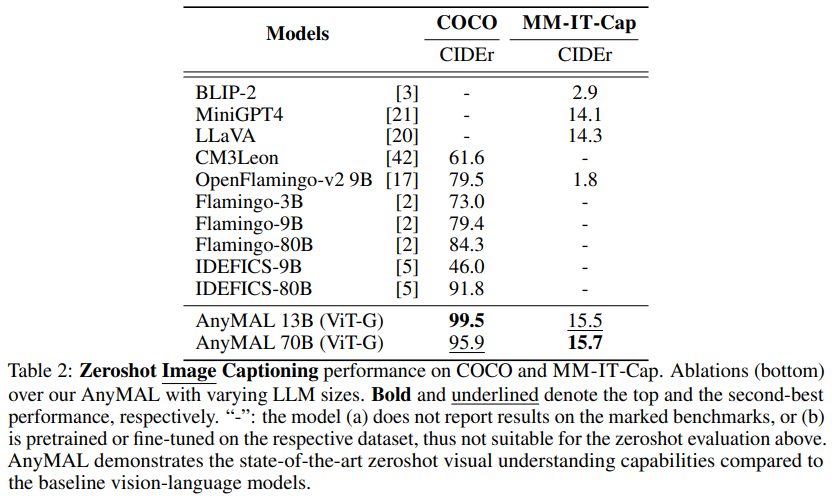
Le tableau 2 montre les résultats dans COCO et les tâches marquées d'une « Description détaillée » (MM- Performances de génération de légendes d'images Zero-shot sur un sous-ensemble de l'ensemble de données MM-IT d'IT-Cap). Comme on peut le constater, la variante AnyMAL fonctionne nettement mieux que la ligne de base sur les deux ensembles de données. Notamment, il n'y a pas d'écart significatif en termes de performances entre les variantes AnyMAL-13B et AnyMAL-70B. Ce résultat démontre que la capacité sous-jacente du LLM pour la génération de légendes d’images est une technique d’intelligence artificielle utilisée pour générer automatiquement les légendes correspondantes des images. Cette technologie combine des méthodes de vision par ordinateur et de traitement du langage naturel pour générer des légendes descriptives liées à l'image en analysant le contenu et les caractéristiques de l'image, ainsi qu'en comprenant la sémantique et la syntaxe. La génération de légendes d'images a de nombreuses applications dans de nombreux domaines, notamment la recherche d'images, l'annotation d'images, la récupération d'images, etc. En automatisant la génération de sous-titres, la compréhensibilité des images et la précision des moteurs de recherche peuvent être améliorées, offrant ainsi aux utilisateurs une meilleure expérience de récupération et de navigation des images. La tâche a moins d'impact, mais dépend fortement de la taille des données et de la méthode d'enregistrement.
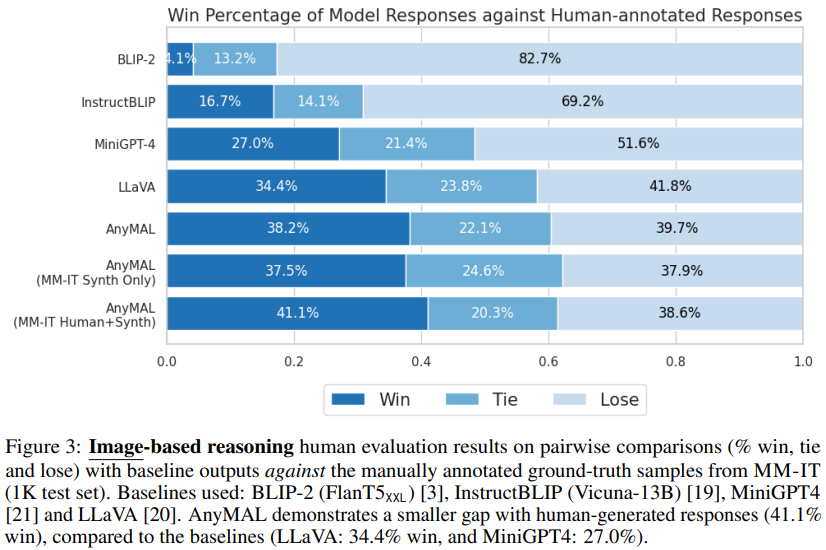
La réécriture requise est : Évaluation humaine sur la tâche d'inférence multimodale
La figure 3 montre qu'AnyMAL se compare à la ligne de base (LLaVA : 34,4 % de taux de victoire et MiniGPT4 : 27,0 % de taux de victoire) La performance est fort et l’écart avec les échantillons réels annotés par des humains est faible (taux de victoire de 41,1 %). Notamment, les modèles affinés avec le jeu d’instructions complet ont montré le taux de victoire prioritaire le plus élevé, démontrant des capacités de compréhension visuelle et de raisonnement comparables aux réponses annotées par l’homme. Il convient également de noter que BLIP-2 et InstructBLIP fonctionnent mal sur ces requêtes ouvertes (taux de victoire prioritaire de 4,1 % et 16,7 %, respectivement), bien qu'ils fonctionnent bien sur le benchmark public VQA (voir tableau 4).
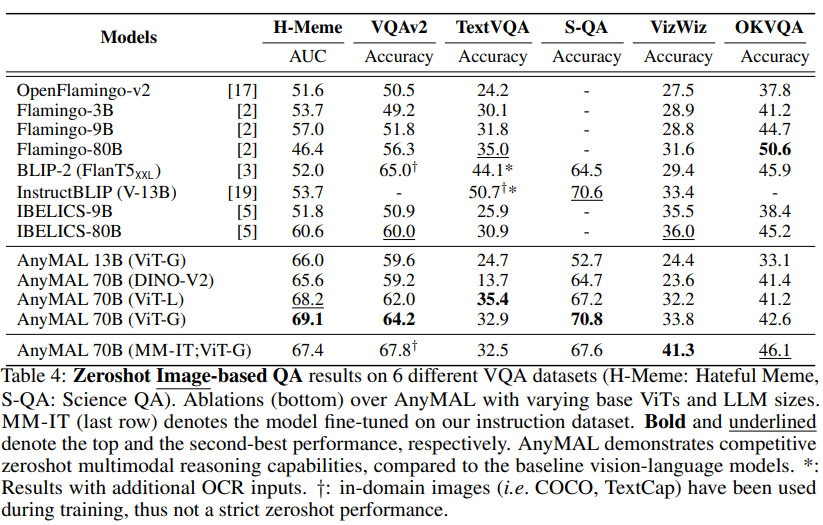
Benchmarks VQA
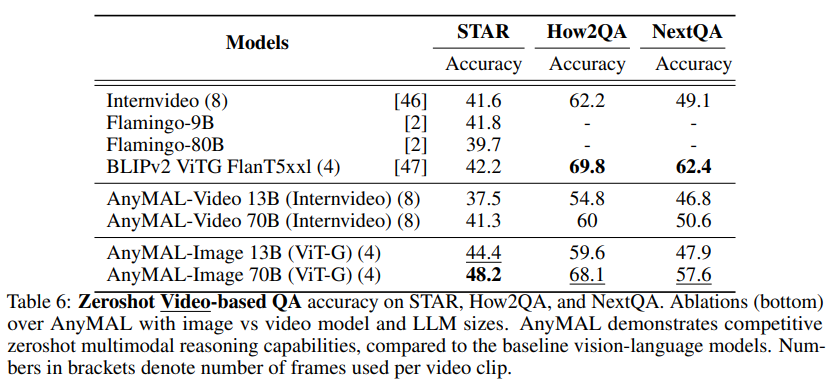
Dans le tableau 4, nous montrons les performances zéro-shot sur l'ensemble de données Hateful Meme, VQAv2, TextVQA, ScienceQA, VizWiz et OKVQA par rapport aux benchmarks respectifs rapportés dans la littérature. les résultats des échantillons ont été comparés. Notre recherche se concentre sur l'évaluation zéro-shot pour estimer le plus précisément possible les performances du modèle sur les requêtes ouvertes au moment de l'inférence. benchmarks d’assurance qualité vidéo.
Régénération des sous-titres audio
Le tableau 5 montre les résultats de la régénération des sous-titres audio sur l'ensemble de données de référence AudioCaps. AnyMAL surpasse considérablement les autres modèles de sous-titres audio de pointe dans la littérature (par exemple, CIDEr +10,9pp, SPICE +5,8pp), indiquant que la méthode proposée est non seulement applicable à la vision mais également à diverses modalités. Le modèle text 70B présente des avantages évidents par rapport aux variantes 7B et 13B.
Fait intéressant, sur la base de la méthode, du type et du calendrier de soumission de l'article AnyMAL, Meta semble prévoir de collecter des données multimodales via son nouveau casque de réalité mixte/métaverse. Ces résultats de recherche pourraient être intégrés à la gamme de produits Metaverse de Meta, ou bientôt appliqués à des applications grand public
Veuillez lire l'article original pour plus de détails.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 données de récupération de disque
données de récupération de disque
 Comment résoudre le problème de l'impossibilité de créer un nouveau dossier dans Win7
Comment résoudre le problème de l'impossibilité de créer un nouveau dossier dans Win7
 Liste des clés d'activation de Windows 10
Liste des clés d'activation de Windows 10
 Comment exporter des fichiers Excel à partir de Kingsoft Documents
Comment exporter des fichiers Excel à partir de Kingsoft Documents
 Quelle devise est MULTI ?
Quelle devise est MULTI ?
 ps luminosité contraste touches de raccourci
ps luminosité contraste touches de raccourci
 site web java en ligne
site web java en ligne
 utilisation de la fonction setproperty
utilisation de la fonction setproperty








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



